Use Kafka, Data Set, and Data Flow in Pega
This knowledge sharing article shows common implementation patterns of using Kafka, Data Set and Data Flow in Pega application to process a large number of records and create cases in a real time.
Pega Infinity version used: 24.2.1
Client use case
A large federal agency provides federal grants to various applicants across the country. Each year, there are many entities applying for various grant opportunities. The requirement is to receive a large volume of applications and create cases in a real time.
To implement this, we'll use Kafka, Data Set and Data Flow in the Pega Infinity platform.
The implementations are organized into three parts.
- Load 100,000 application records to a local data type table.
- Feed the 100,000 application records to a Kafka topic.
- Process the 100,000 application records from the Kafka topic and create cases in real time.
Configurations
(Part A - Load 100,000 sample application records to a local data type table)
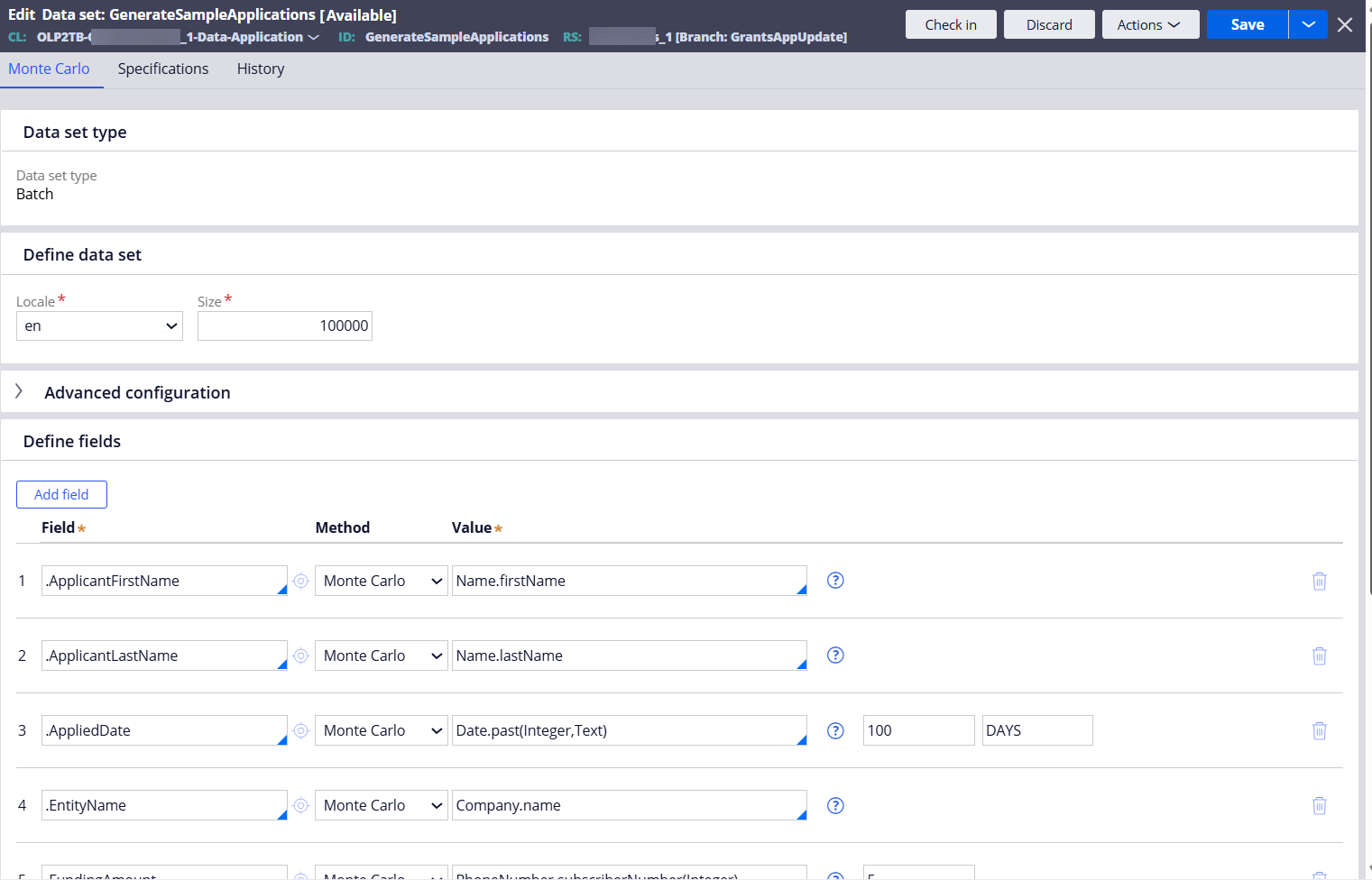
Step 1 - Create a Data Set (Type=Monte Carlo) in the data type class to generate 100,000 sample application records.
Map the properties to auto populate with random values.
This Data Set will be configured as a source of Data Flow later.
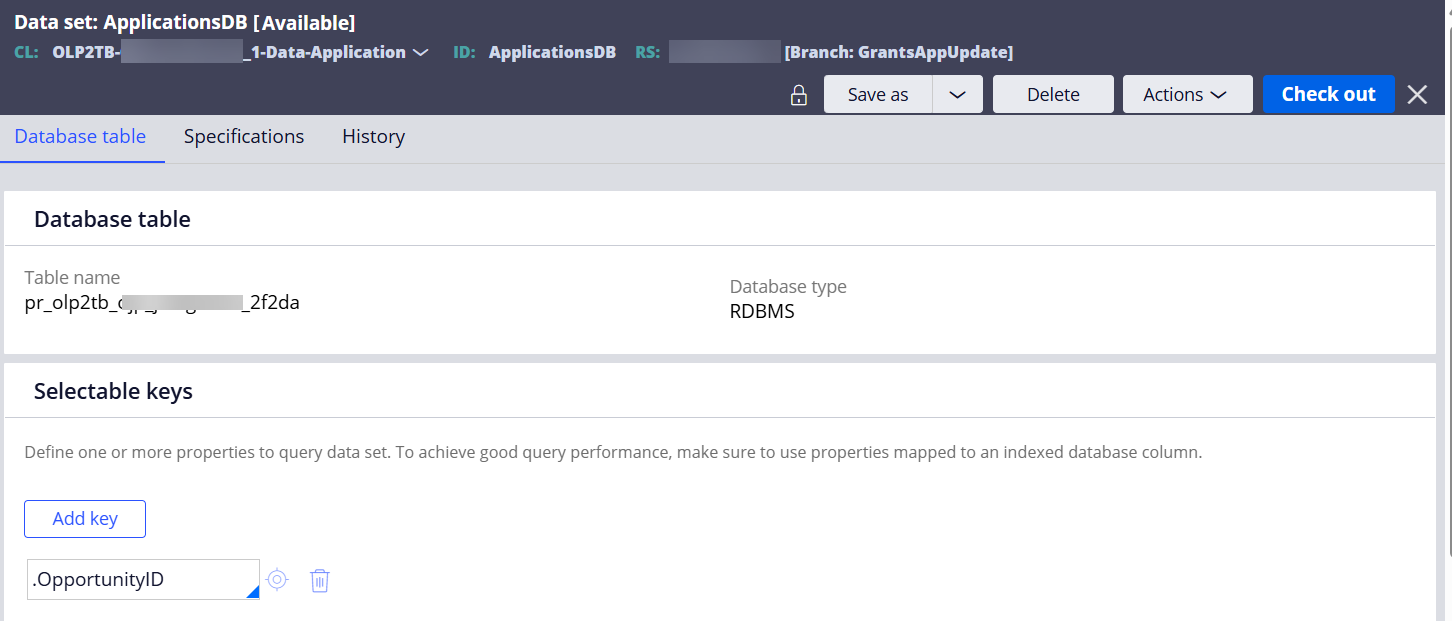
Step 2 - Create another Data Set (Type=Database Table) in the data type class.
Notice that the table name will be automatically set.
This Data Set will be configured as a destination of Data Flow later.
Step 3 - Create a Data Flow to generate and load 100,000 sample application records to the local data type table.
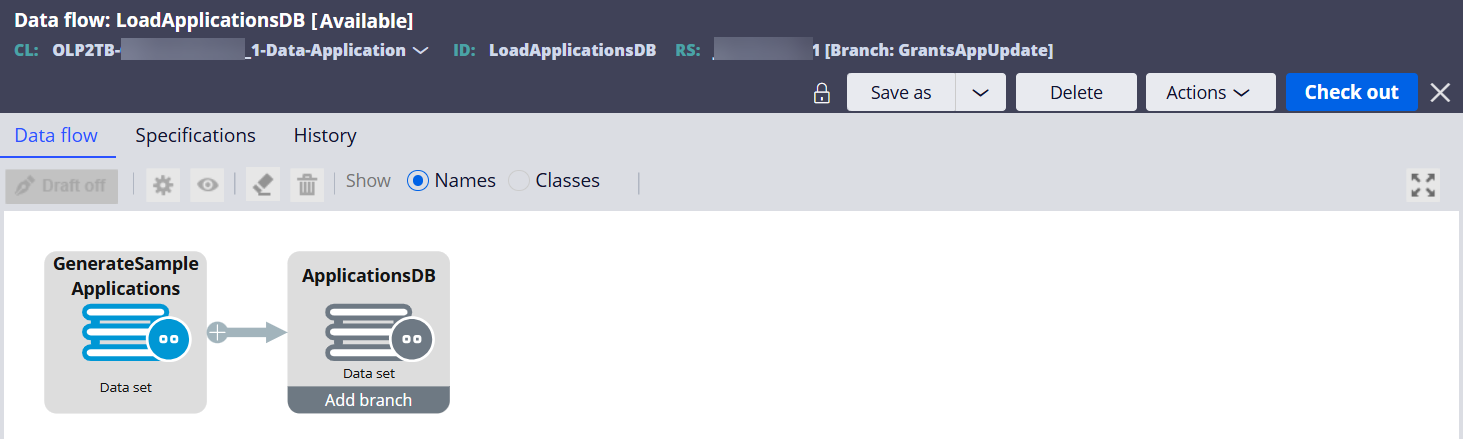
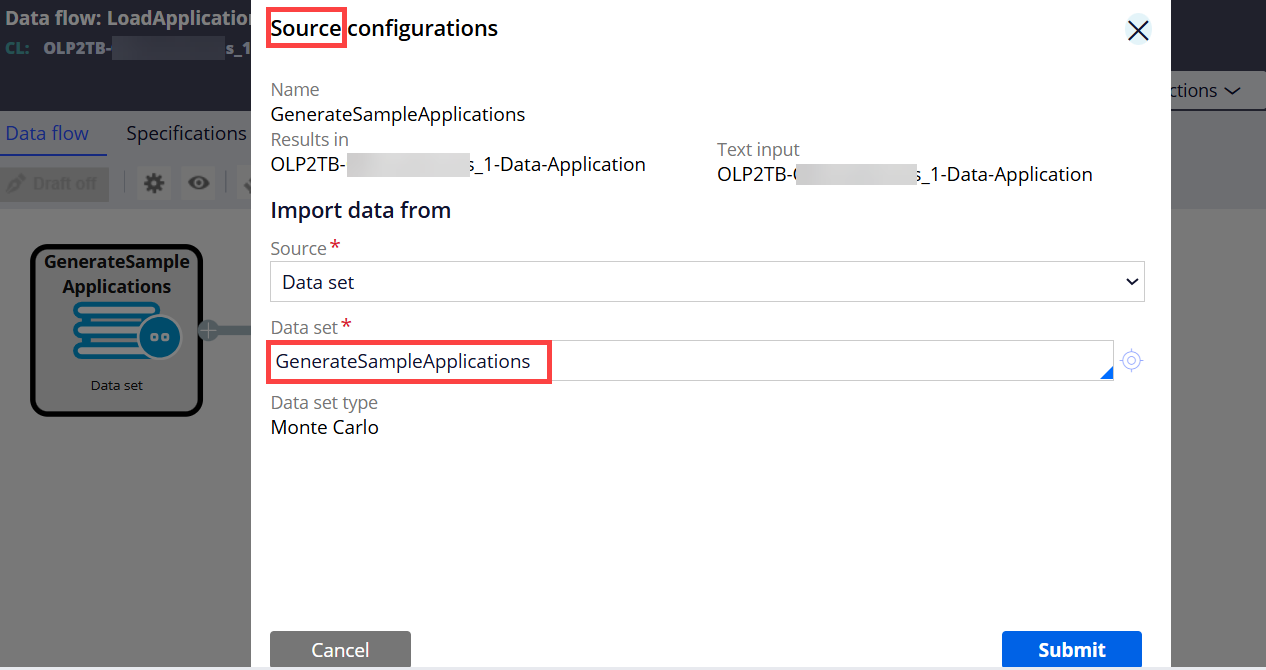
Set the source and destination of the Data Flow with the two Data Set rules created above.
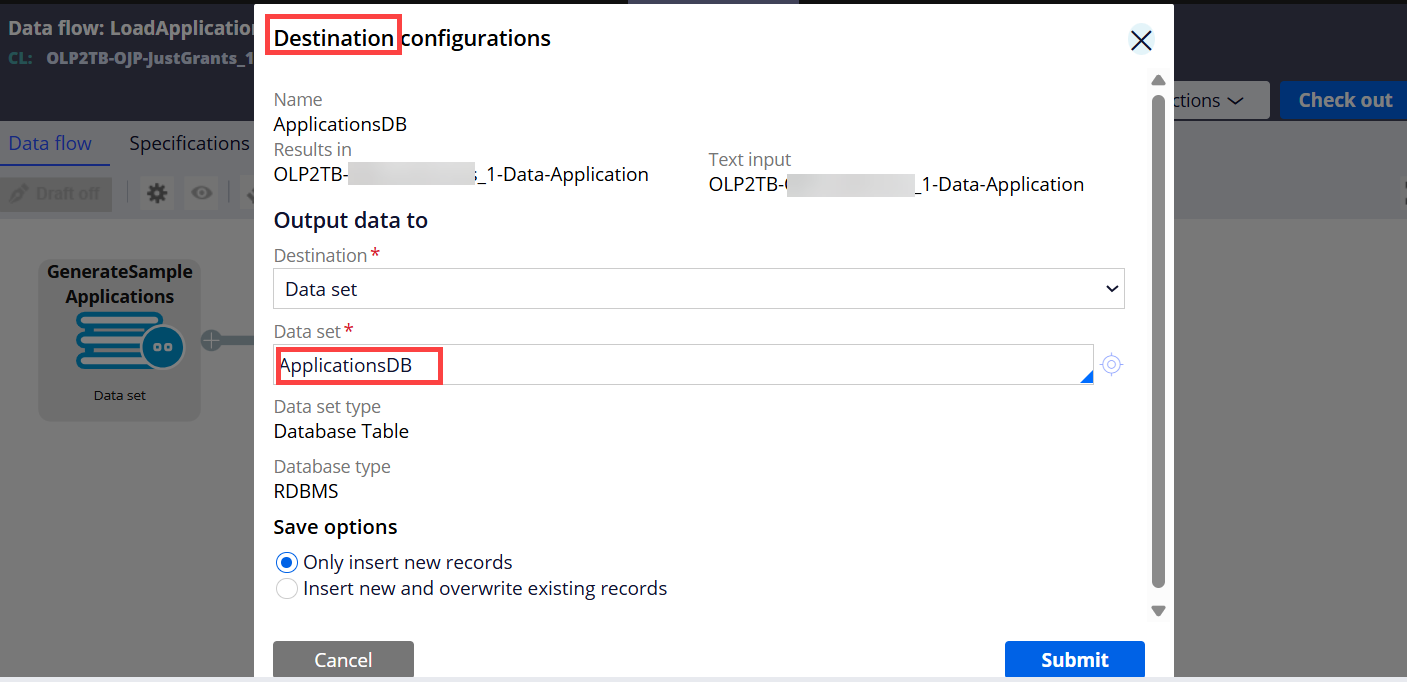
Step 4 - Run the Data Flow (click Actions > Run)
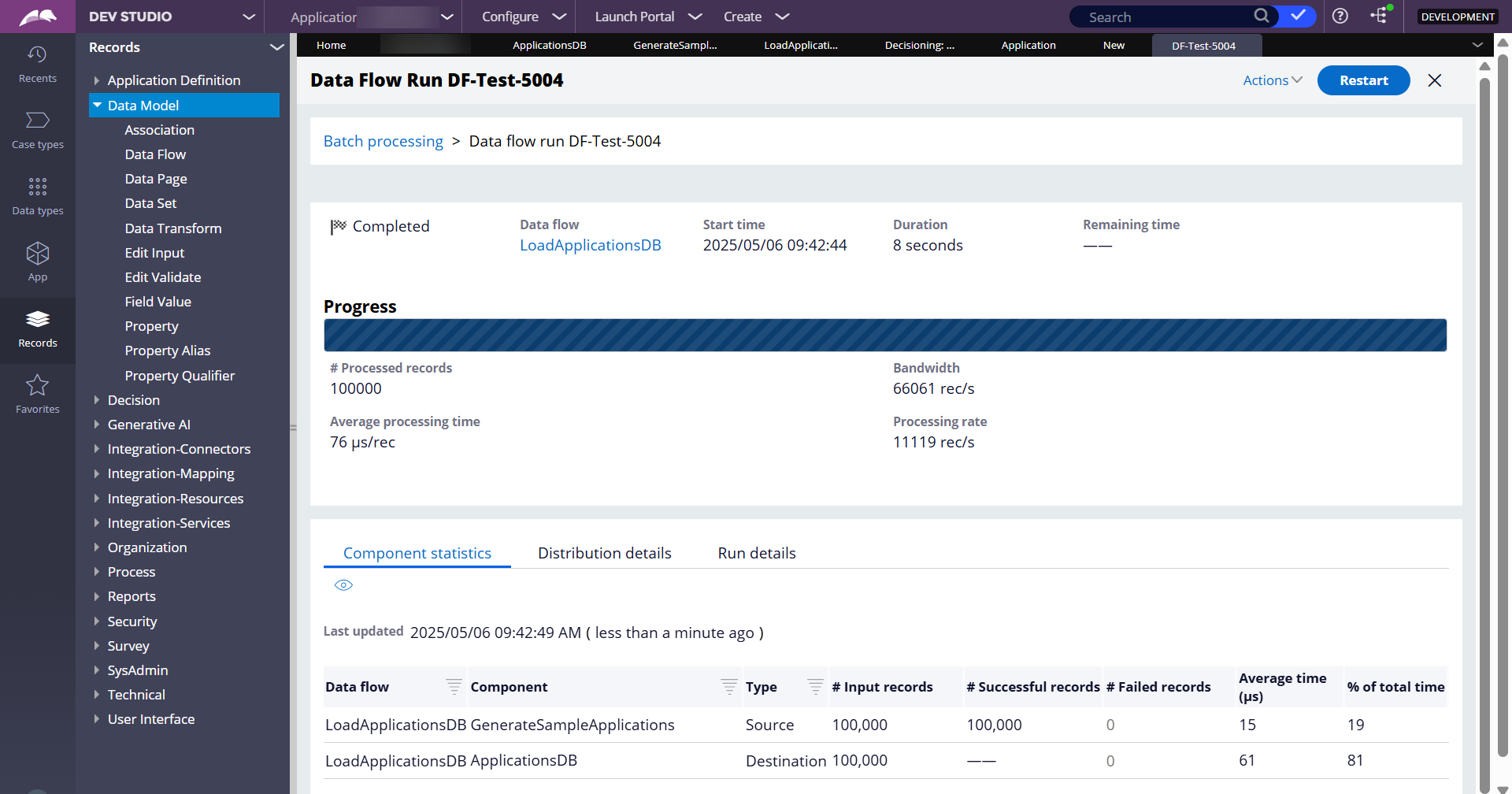
After the run, 100,000 records got created and loaded to the local data type table.
Notice the random data automatically generated by the 'Monte Carlo' method in the source Data Set.

(Part B - Feed the 100,000 application records to a Kafka topic)
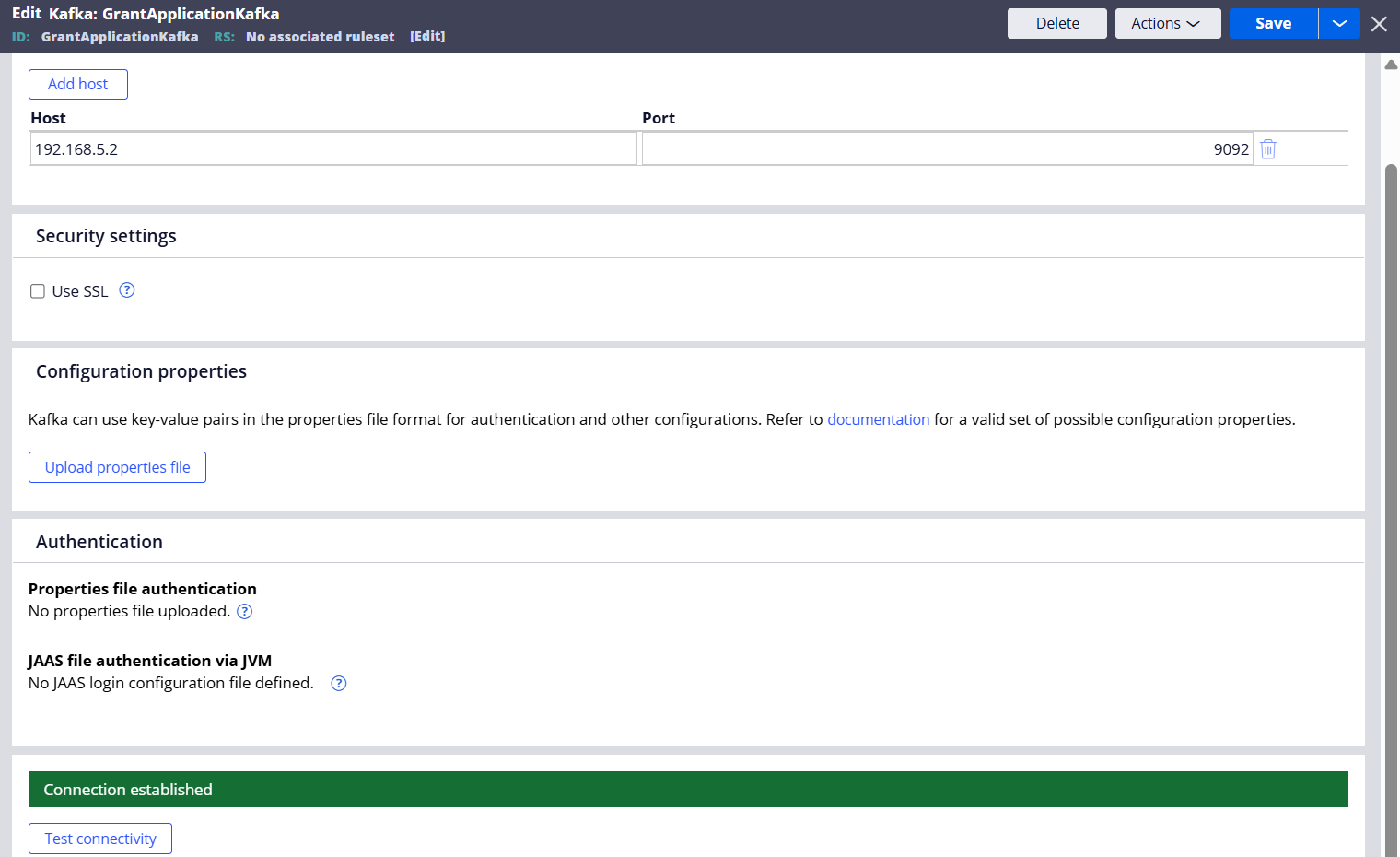
Step 1 - Create a Kafka instance.
I got the Host IP & Port information from the Pega Cloud administrator.
Step 2 - Create a Data Set (Type=Kafka) and link to the Kafka instance created above.

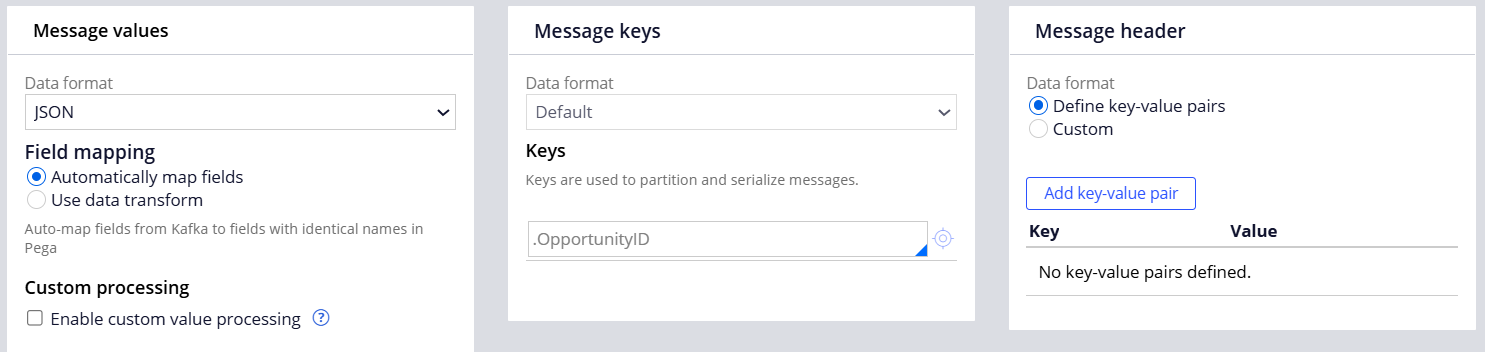
Step 3 - Create a Data Flow to feed the 100,000 application records from the data type table to the Kafka topic.
Note that the source Data Set is created in Part A above.
We'll run this Data Flow in Part 3 below.
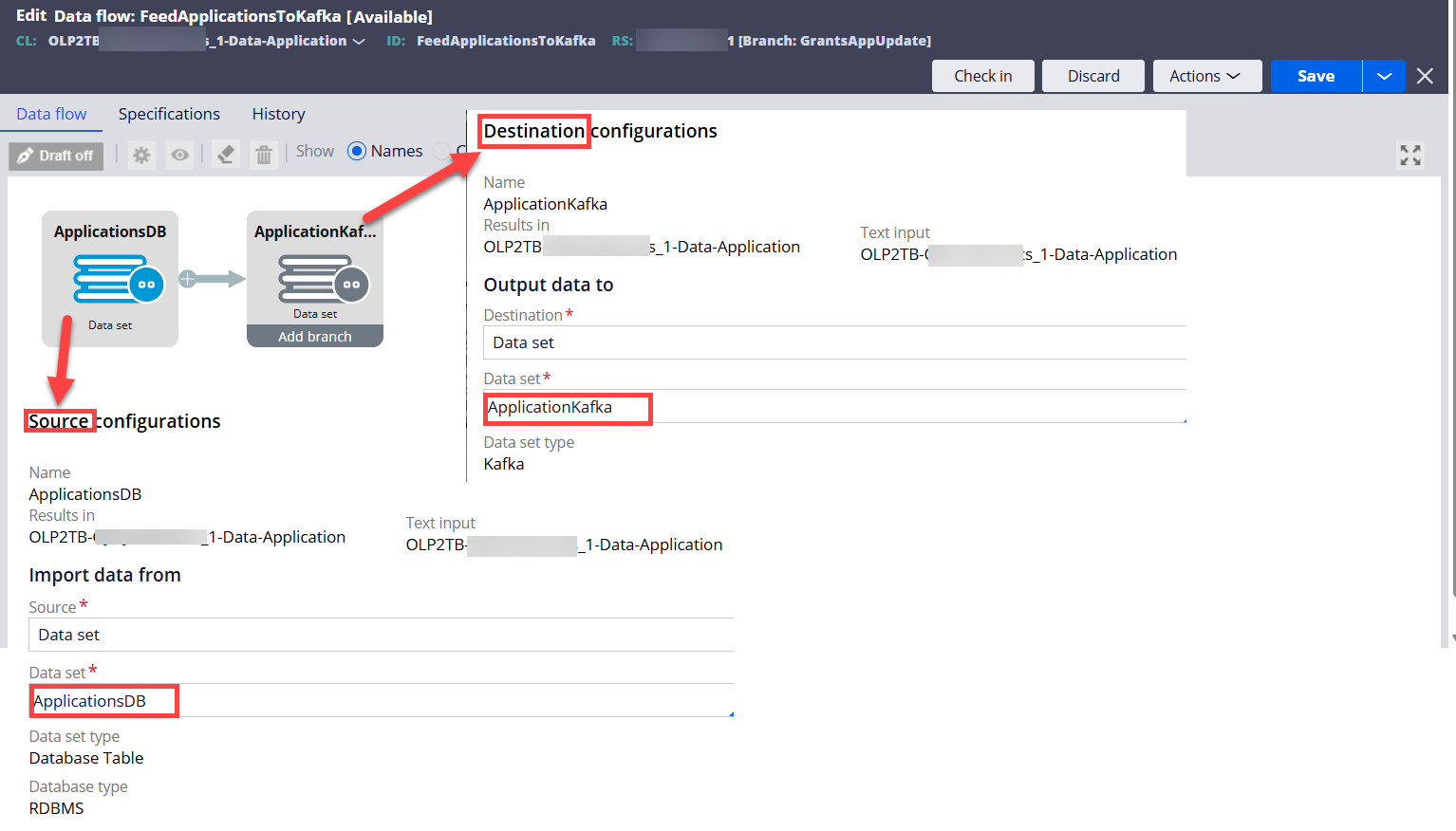
(Part C - Process the 100,000 application records from the Kafka topic and create cases in real time)
Step 1 - Create a Data Flow to consume the application records in the Kafka topic and create cases in a real time.
Notice that we can map the case properties from the source in the Destination configurations popup.
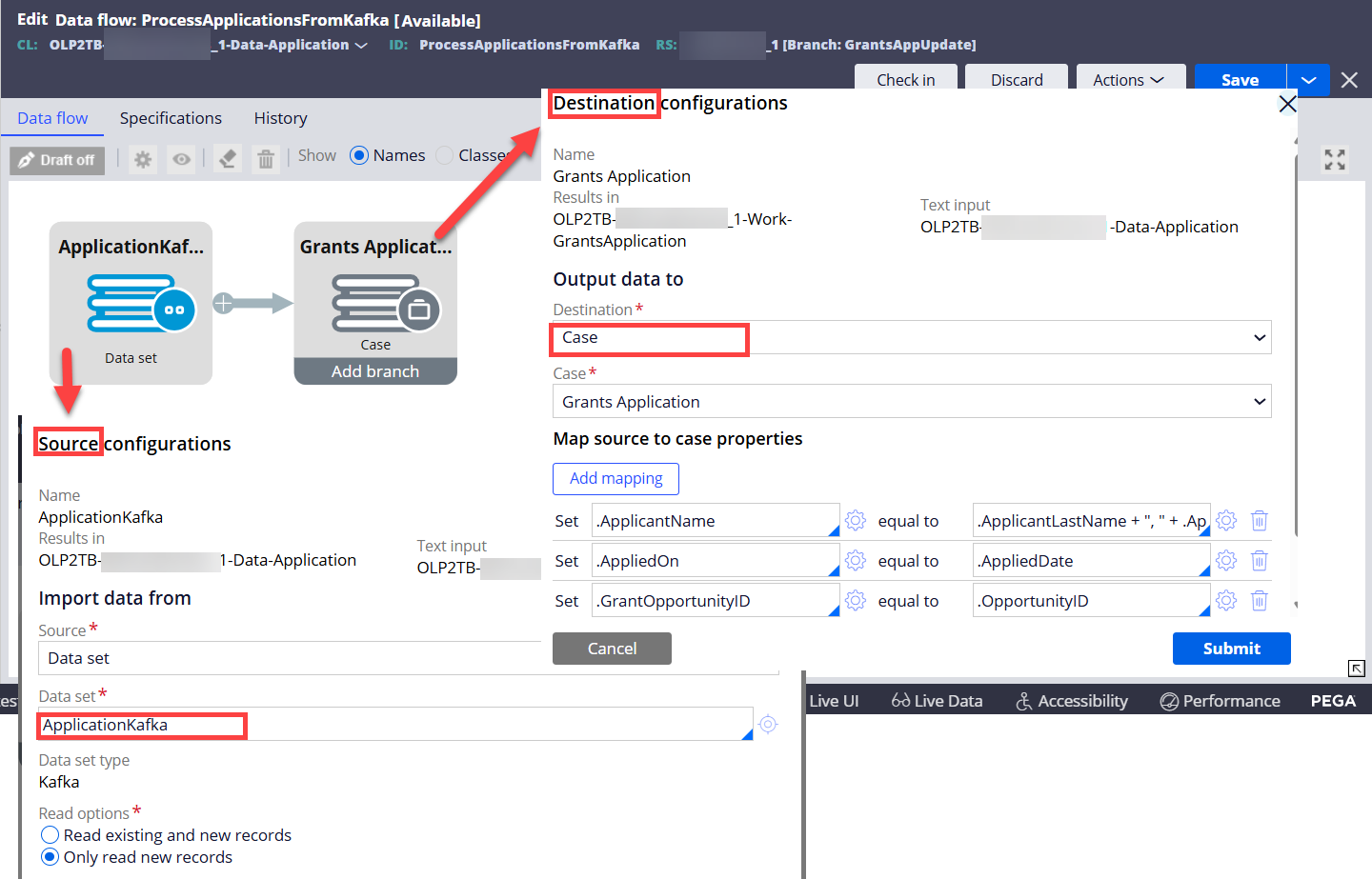
Step 2 - Run the Data Flow (click Actions > Run) to monitor and process the new records in the Kafka topic in a real time.
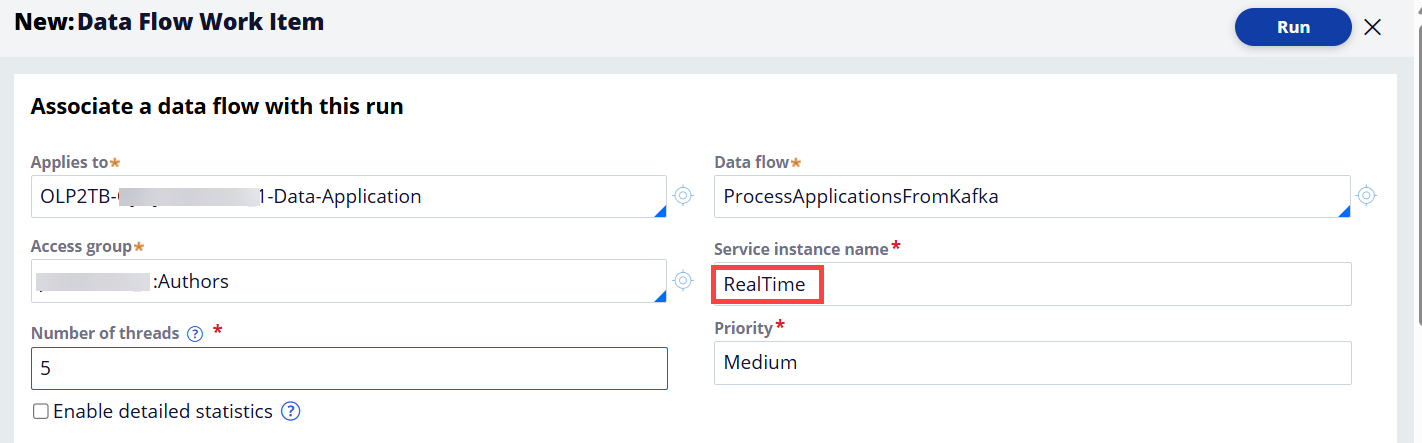
The Data Flow is now in progress and waiting for a new message in the Kafka topic.
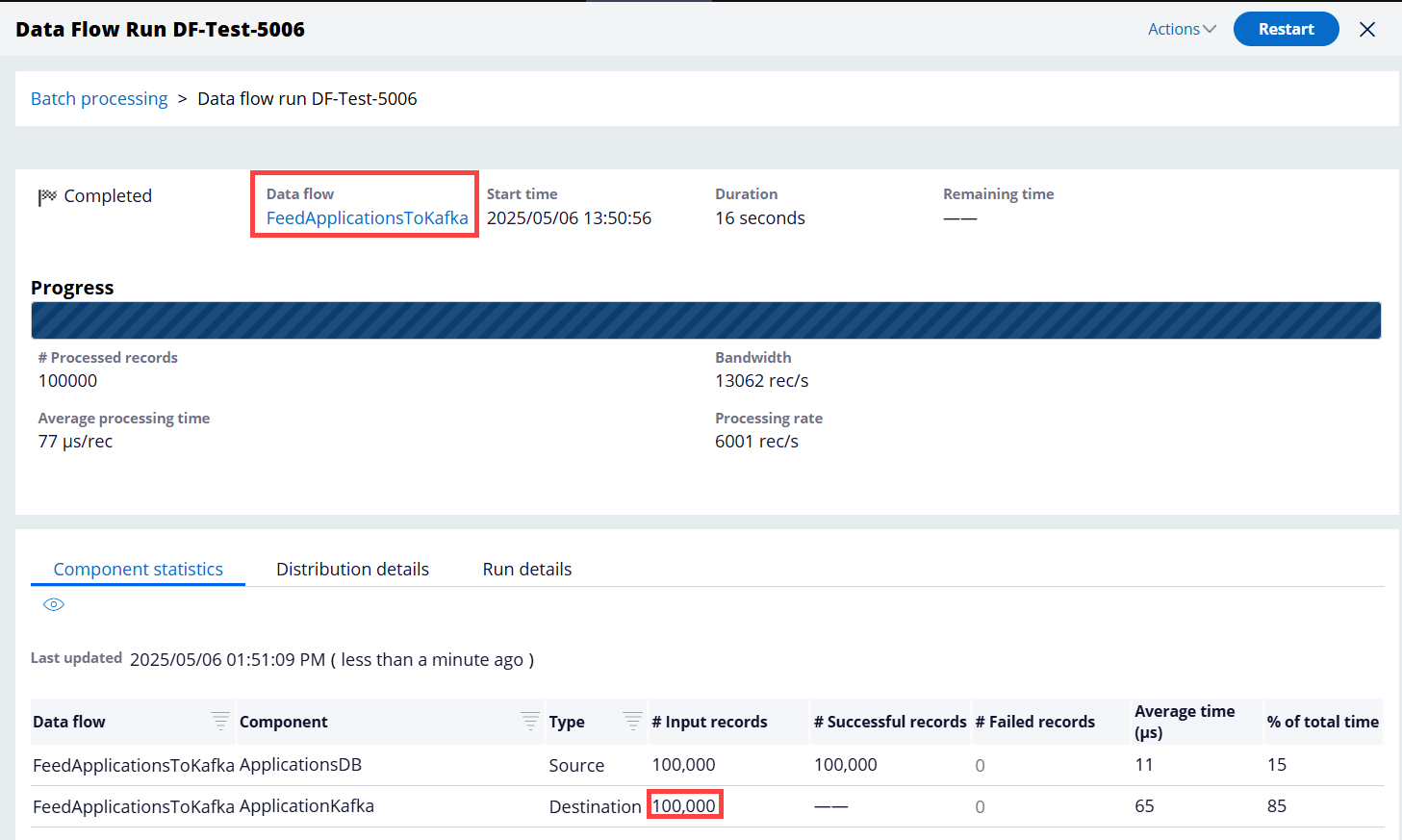
Step 3 - Run the FeedApplicationsToKafka Data Flow created in Part B above to send the 100,000 application records to the Kafka topic.
It completed sending the 100,000 records to the Kafka topic pretty quickly. See below.
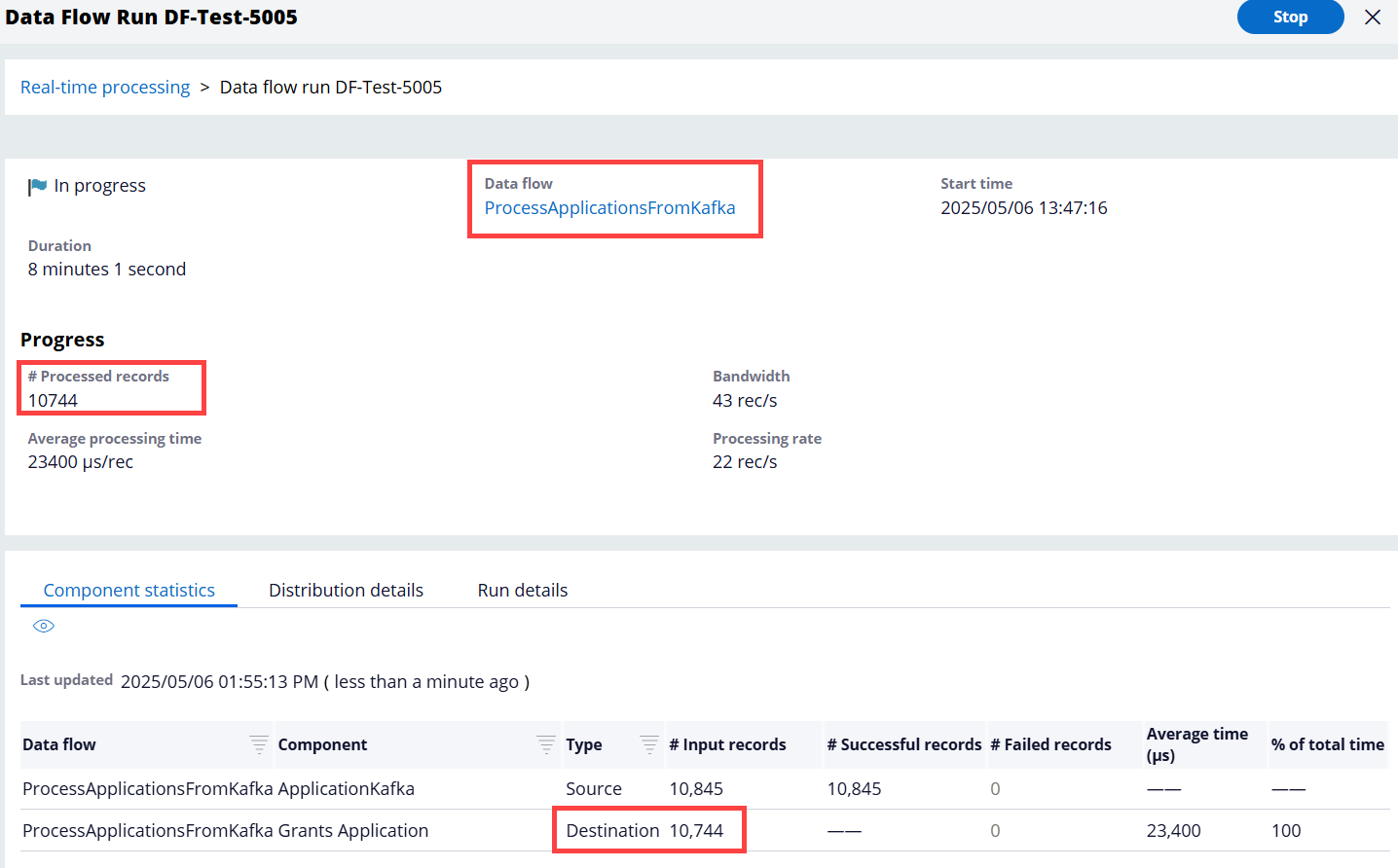
Step 4 - Go back to the ProcessApplicationsFromKafka Data Flow (which has been running) and verify the results.
As we can see below, the processing is happening. So far, it processed 10,744 records from the Kafka topic and created 10,744 cases.
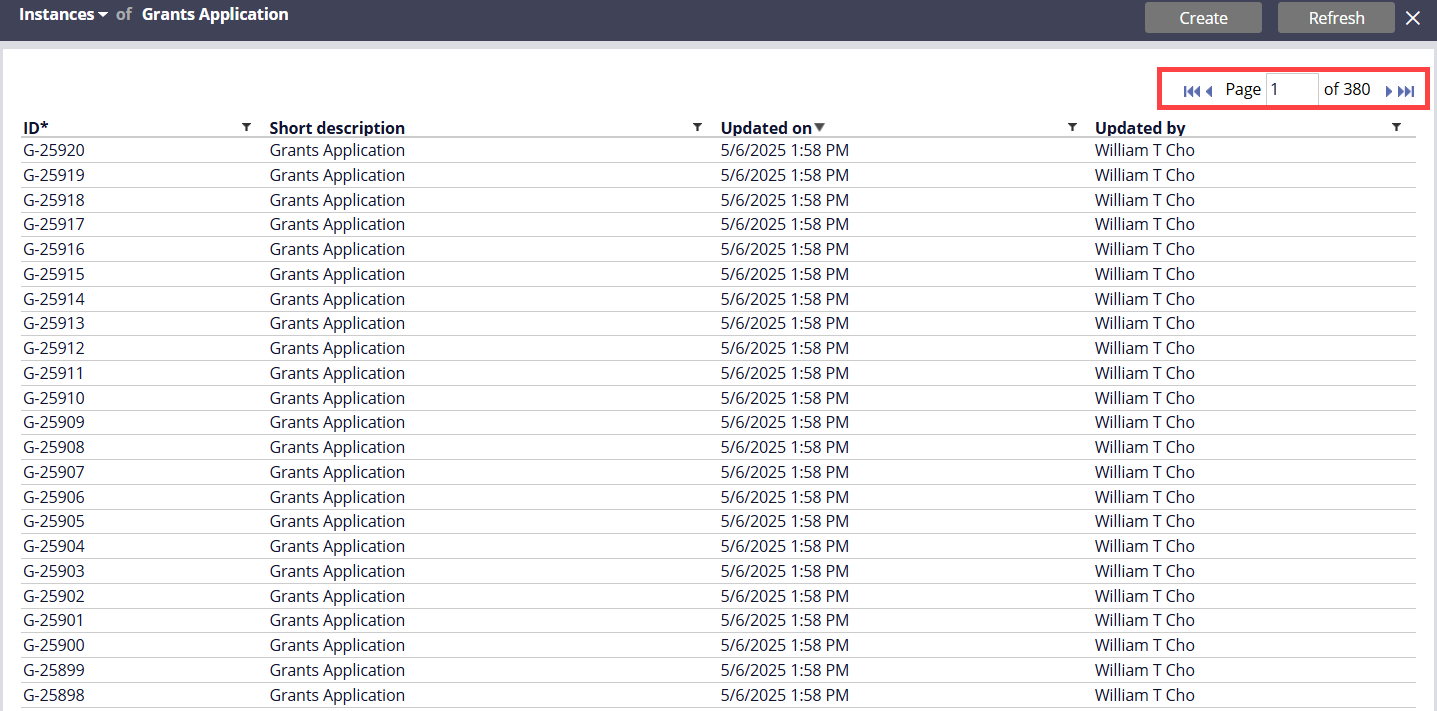
We can also verify the large number of Grants Application cases created.
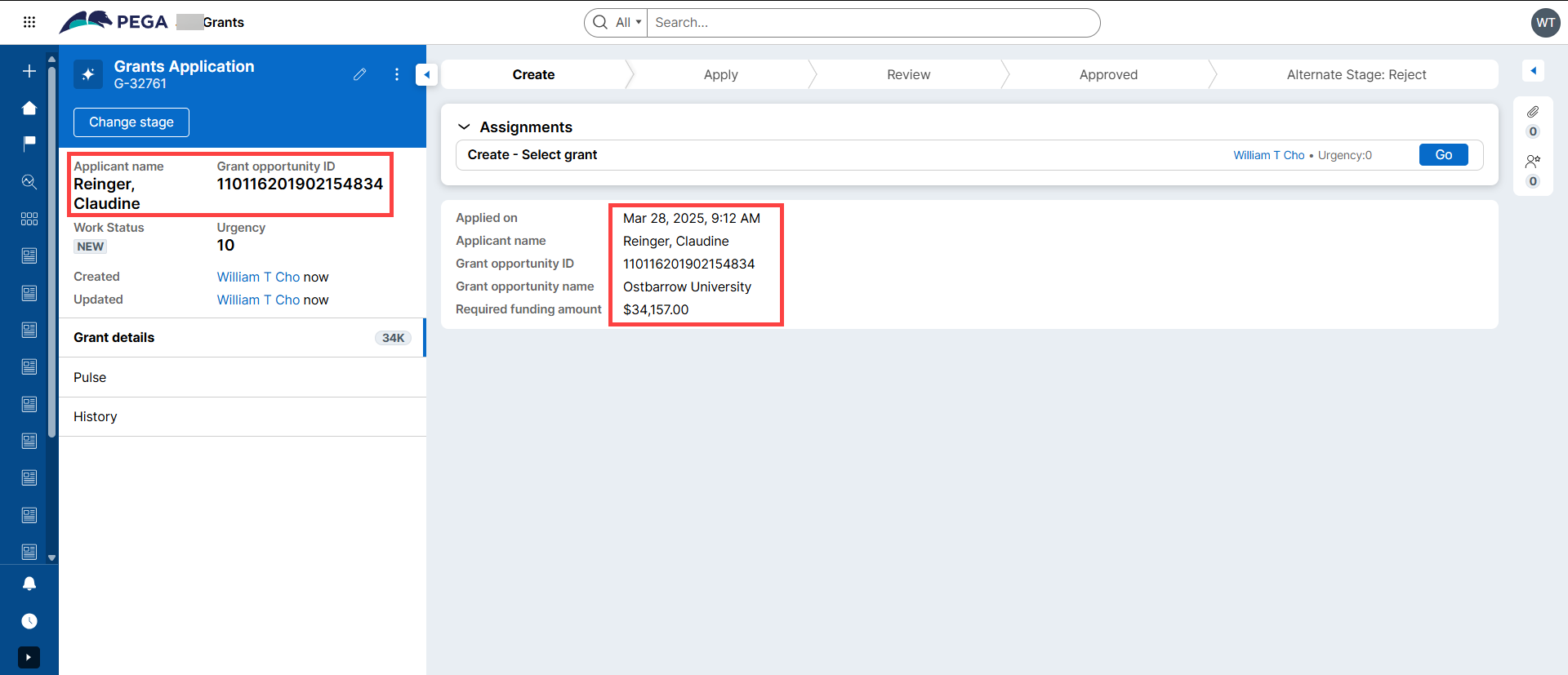
Open one of the cases created. Notice the random test data auto generated by the 'Monte Carlo' method of Data Set configured in Part A above.
Additional information
- I'm hearing that Data Flow might be a separate license. Please check with your Pega account contact before considering it for use.
- Data Flows can be managed in the following landing page (Decisioning > Decisions > Data Flows)
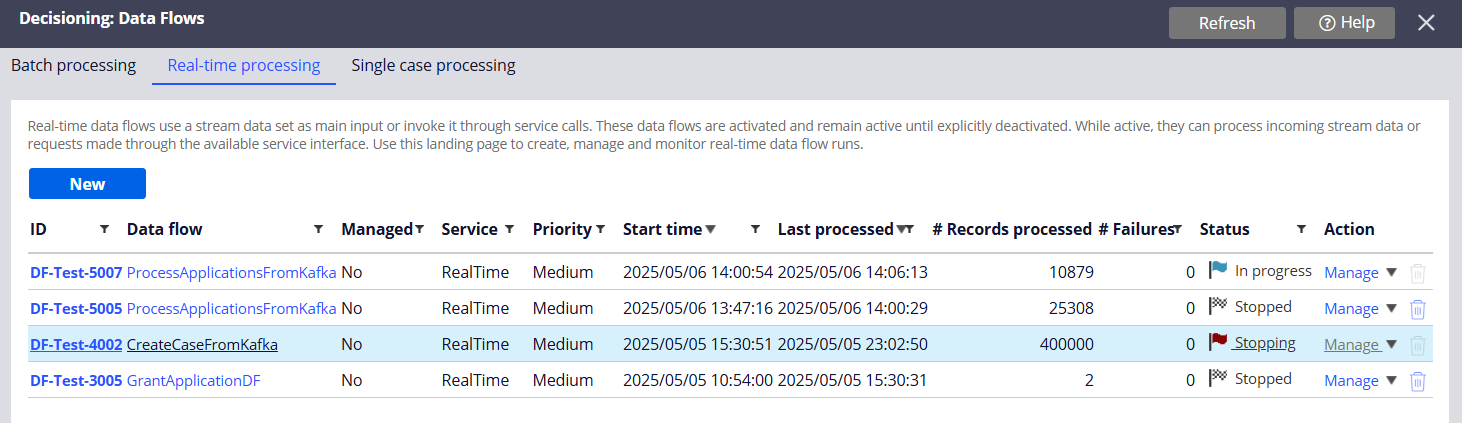
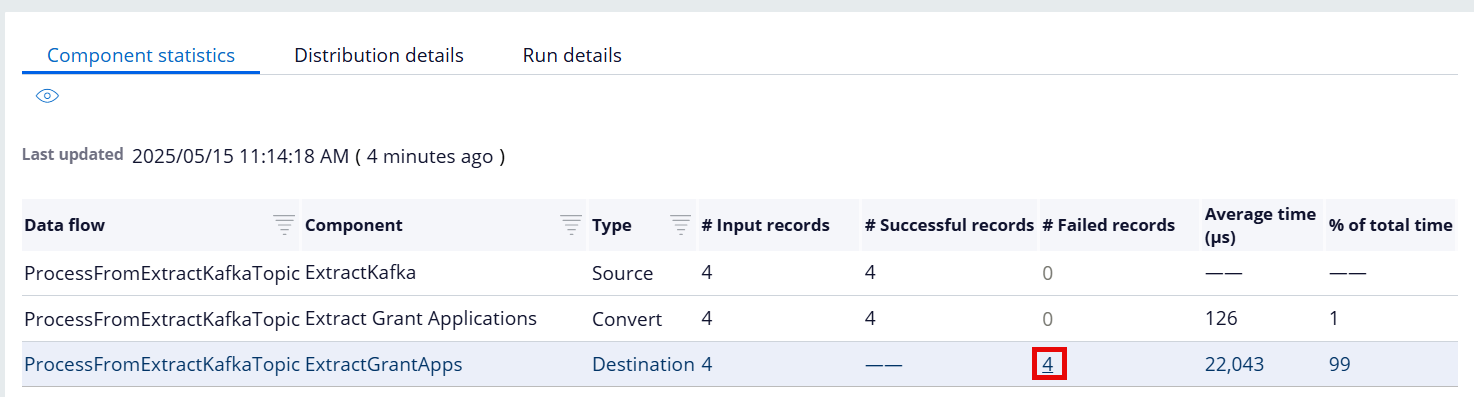
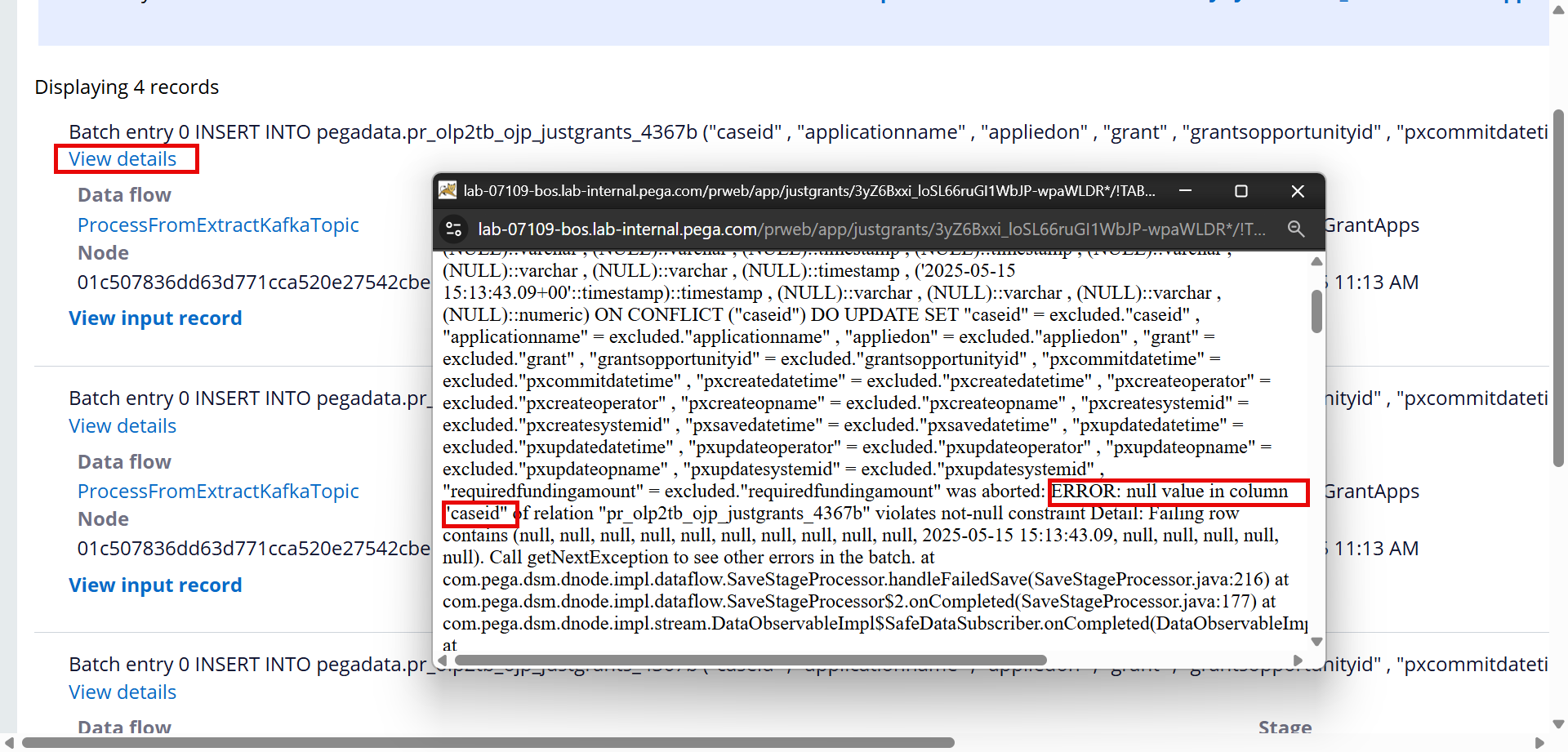
- If something fails during a Data Flow processing, the Data Flow reports the errors which can be further drilled down to see the failure details.
Please feel free to leave any comment or question.
Wells Fargo
IN
@Will Cho Thanks for sharing this knowledge bite. If for some reason the records are not processed, how would it be tracked and re-tried? Could you please throw some light.
Pegasystems Inc.
US
@suraj. I haven't encountered an exception during this proof-of-concept implementation, but here are some information from Pega doc you may find relevant. It is from the new real-time BIX extraction feature which also leverages Kafka. Sounds like Pega plans to continually enhance the exception handling feature.
https://docs.pega.com/bundle/platform/page/platform/reporting/bix-faq.h…
The extracted data is published to Kafka, where it is retained until the message is read or until the topic's message retention configuration is met. When the system is back online, the subscriber, consumer, or target can read the messages from Kafka.
Currently, there is limited support available for handling errors and exceptions. If failures occur while pushing data to Kafka, messages are sent to a Dead Letter Topic. This capability is being enhanced to support message retries from the Dead Letter Topic in upcoming releases.
An exception will be logged in the event of any failures encountered while writing data to Kafka.
TD
CA
@Will Cho Thank you for the very helpful implementation pattern reference!
With regards to error handling, Queue Processors has a number of capabilities that seem to stand out:
QPs are made for streaming, have better OOTB error handling capabilities, and scale well for Kafka functionality:
I wanted to check if QPs had been in scope for your use case, and if so, any analysis that stood out. Thanks!