Extract case/data in real-time (BIX)
This knowledge sharing article introduces the new real-time BIX extraction feature in Pega Infinity 24.2.
This article will show how to configure a real-time BIX extraction using Kafka model and process using Data Flow.
Pega Infinity version used: 24.2.2
Client use case
Currently, client is using Pega Business Intelligence Exchange (BIX) to extract case data from BLOB to a .CSV file and upload it to a Pega Cloud repository. After that, their reporting & analytics team consumes the .CSV file, performs an ETL process, and adds the case details to a data warehouse for enterprise reporting and analytics. However, the issue is that this is done in a batch mode using Job Schedulers on a fixed schedule, which causes data latency and delays the management decision.
Client wants to see a real-time update to their reports to make a more timely decision.
Our solution is to use BIX "real-time" extraction feature to implement this requirement.
Configurations
The configurations are organized into five parts:
- Configure a Kafka/Data Set where extracted case details will be published in real-time.
- Configure a real-time BIX extract rule.
- Configure a DB table/Data Set, which will be the destination of the extracted case details.
- Configure a Data Flow to process the extracted case details from Kafka and insert/update them to a database table.
- Run a test.
## Part A - Configure a Kafka/Data Set where extracted case details will be published in real-time.
Step 1 - Create a Kafka instance.
Note: Clients should use their own external Kafka.
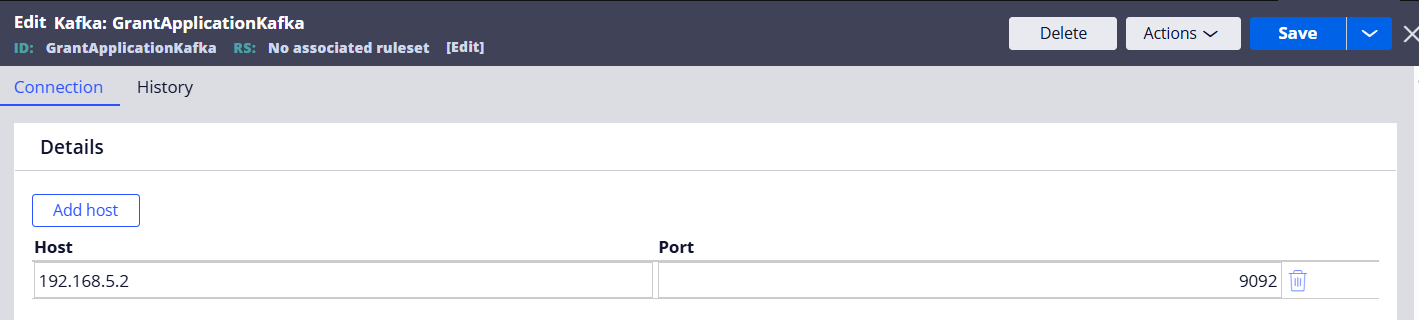
Step 2 - Create a Data Set (type=Kafka) and connect to the Kafka instance created above.
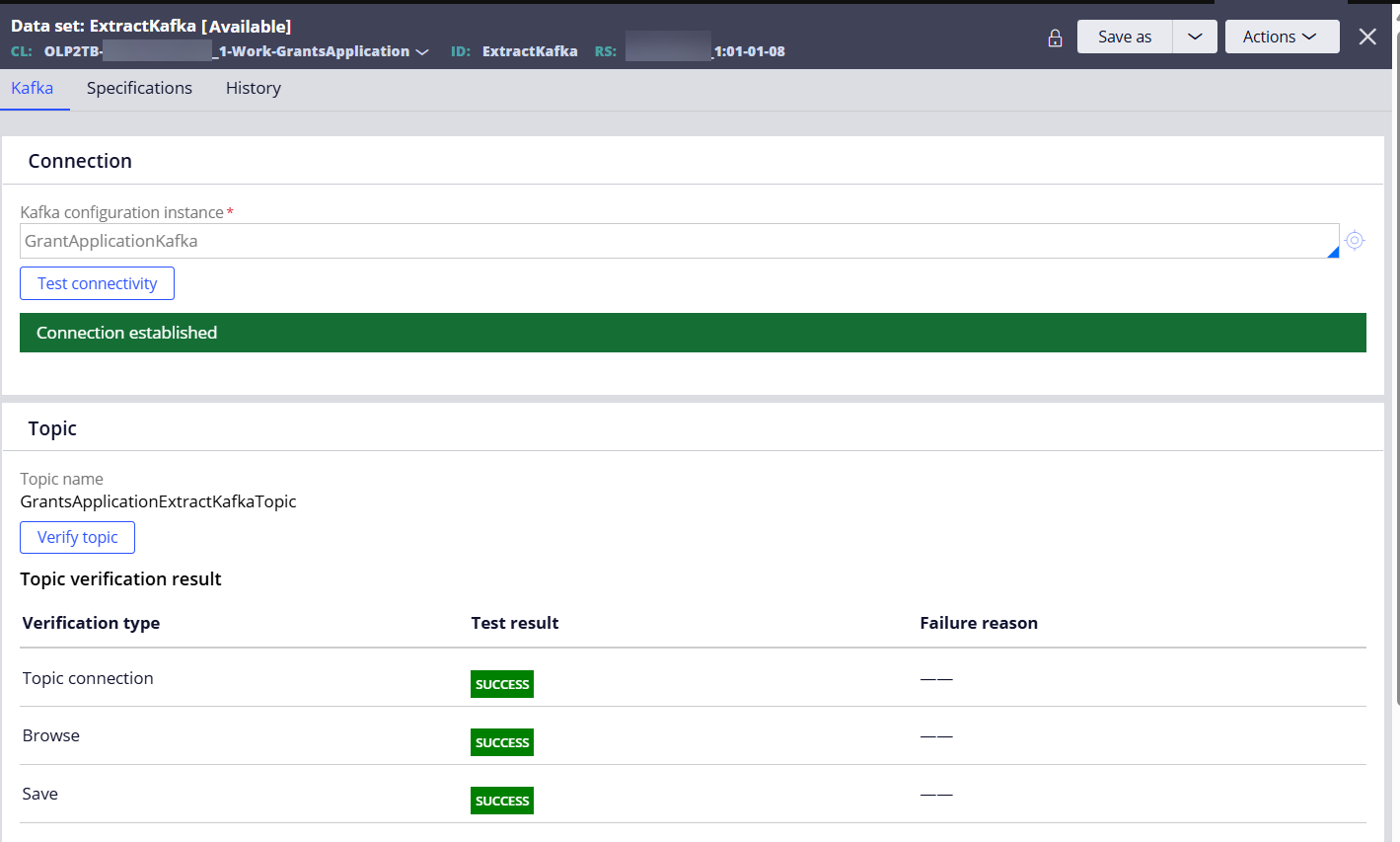
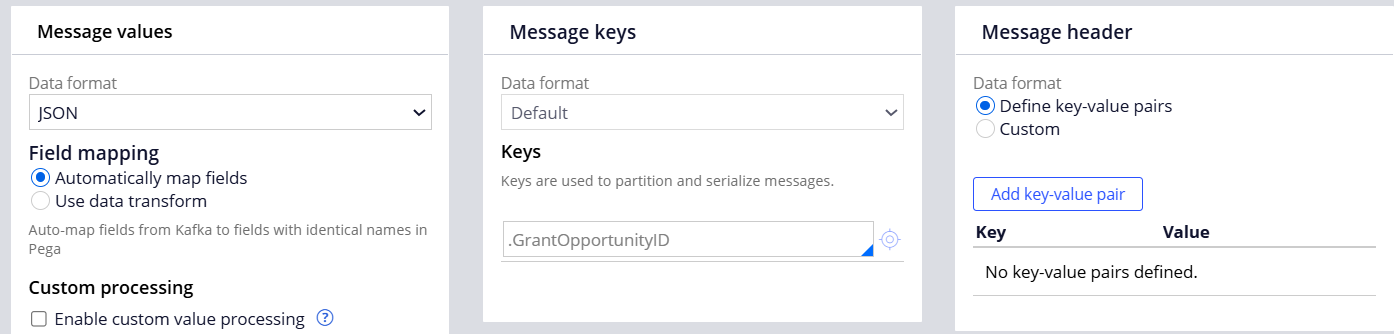
## Part B - Configure a real-time BIX extract rule.
Step 1 - Create an Extract rule and select properties to extract.
We are defining the Extract rule in the GrantsApplication work class.
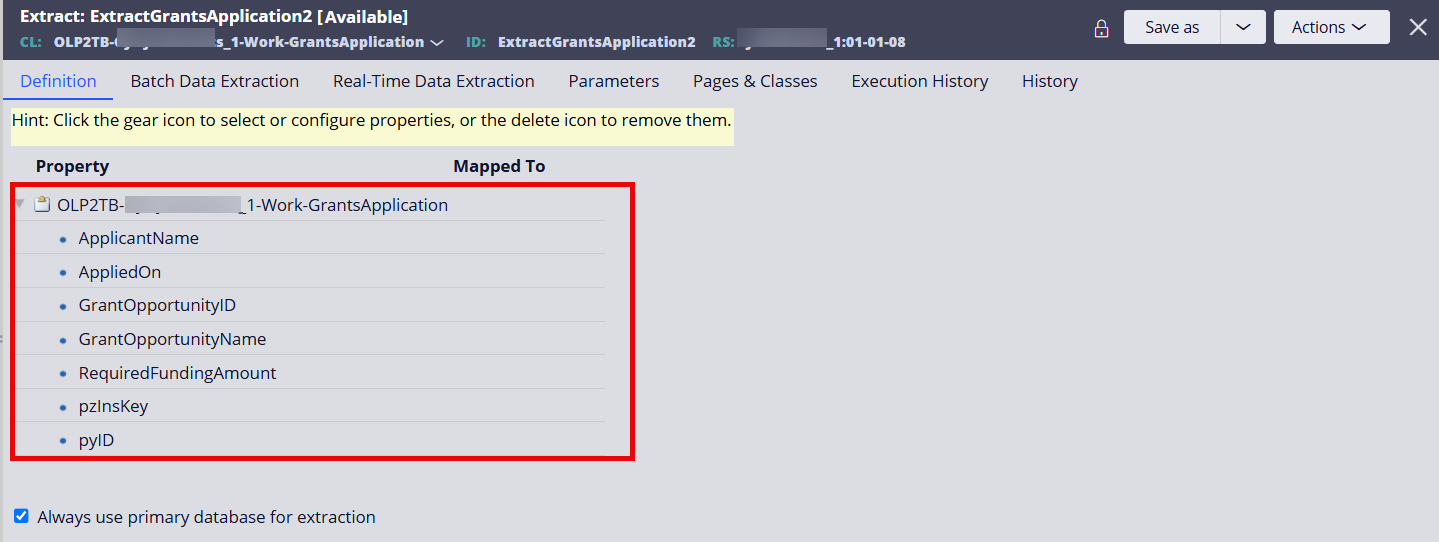
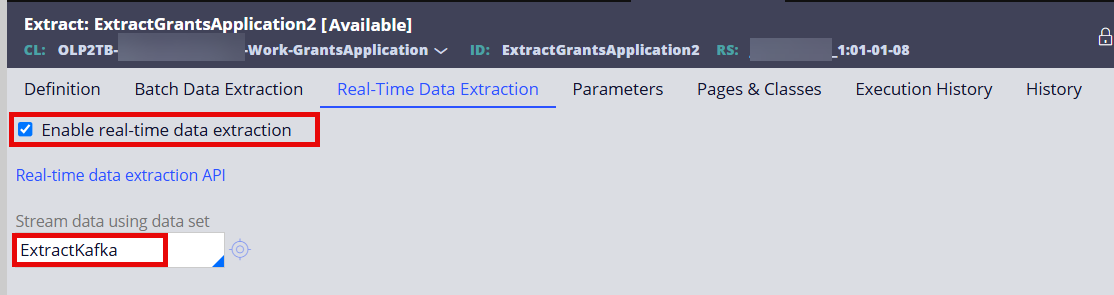
Step 2 - Select the 'Enable real-time data extraction' option and reference the Data Set (Kafka) created above.
## Part C - Configure a DB table/Data Set, which will be the destination of the extracted case details.
In this example, we will insert/update extracted case metadata to a database table after consuming them from Kafka topic.
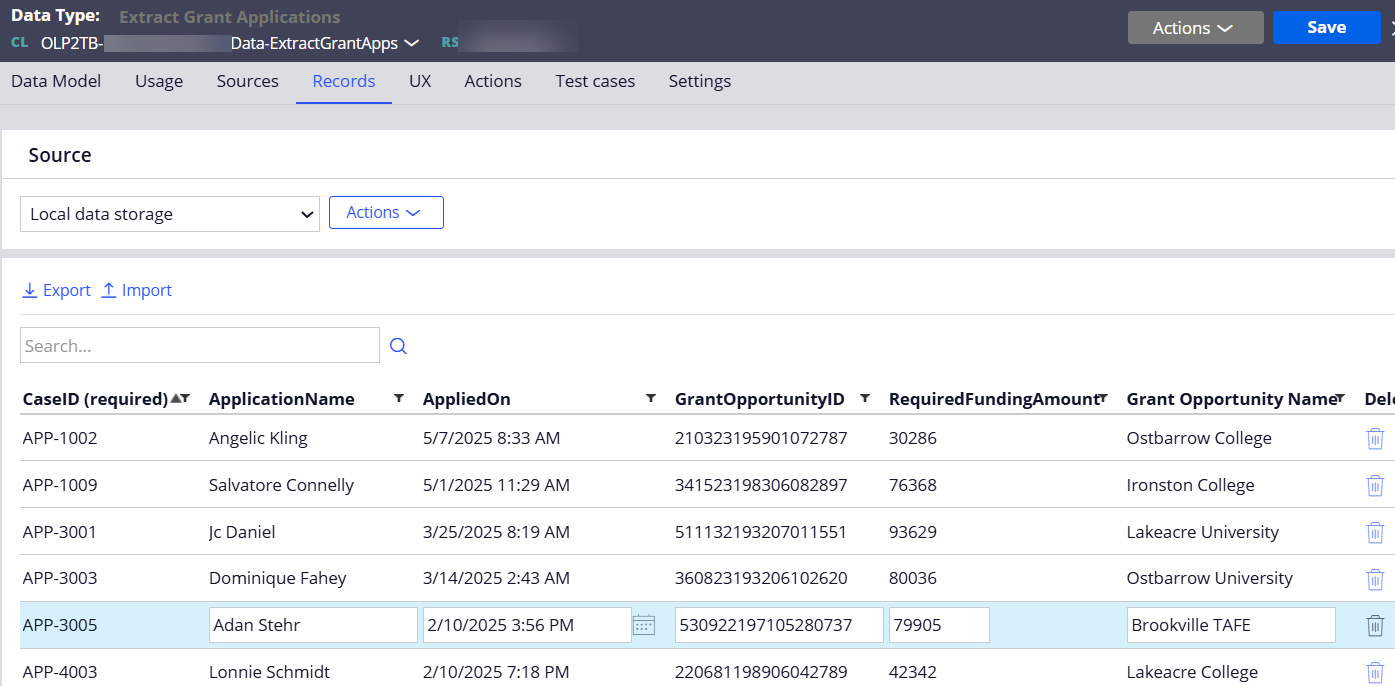
Step 1 - Create a data type table and define the properties to map the extracted case metadata.
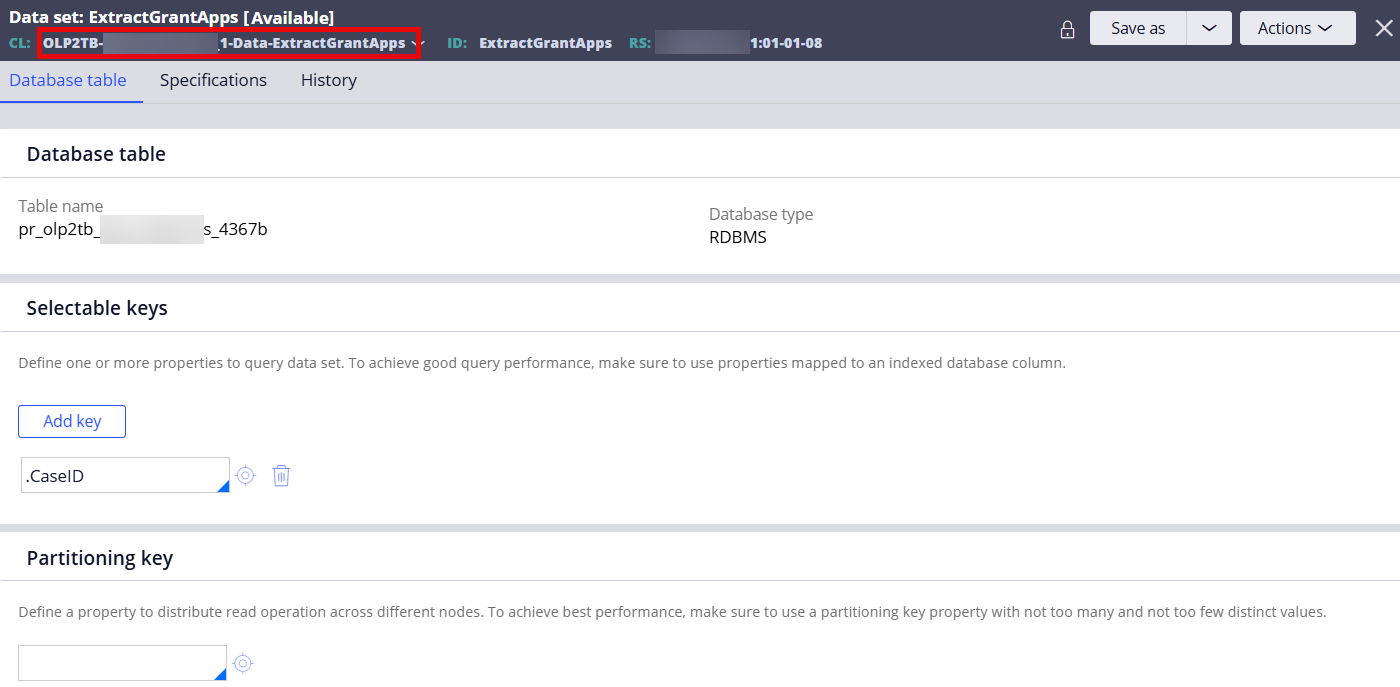
Step 2 - Create a Data Set and reference the data type class created above.
Note: Table name will be set automatically.
## Part D - Configure a Data Flow to process the extracted case details from Kafka and insert/update them to a database table.
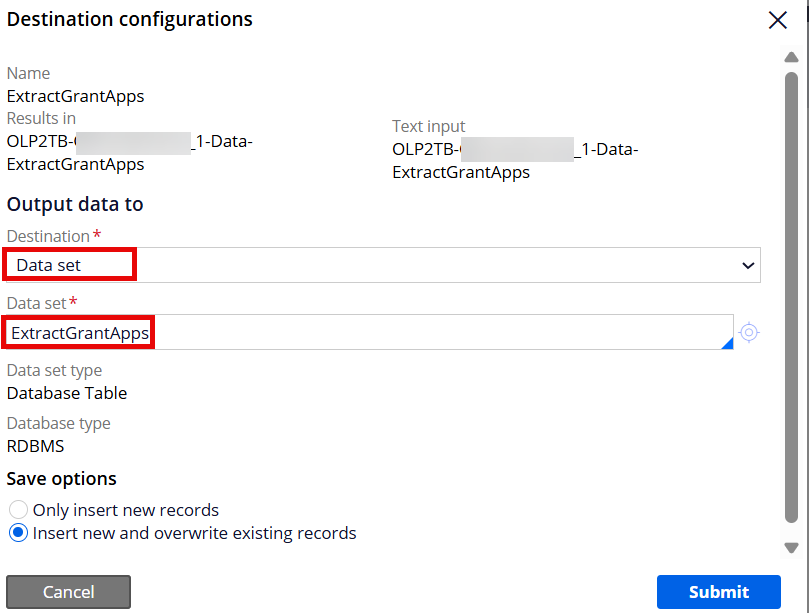
Step 1 - Create a Data Flow rule and set the source & destination.
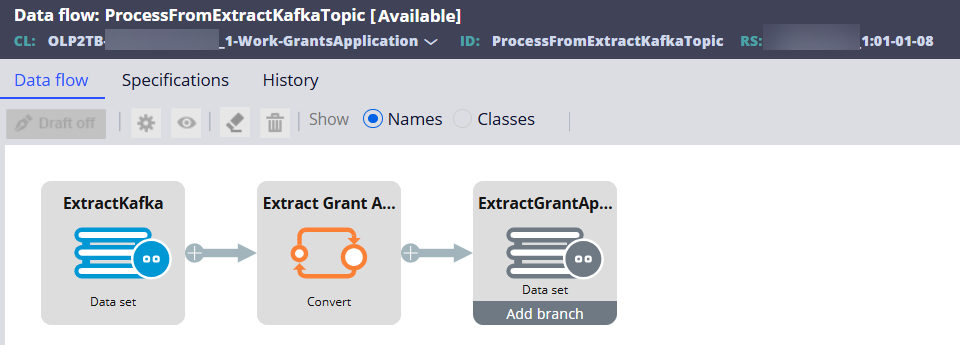
Source: Data Set/Kafka (created above)
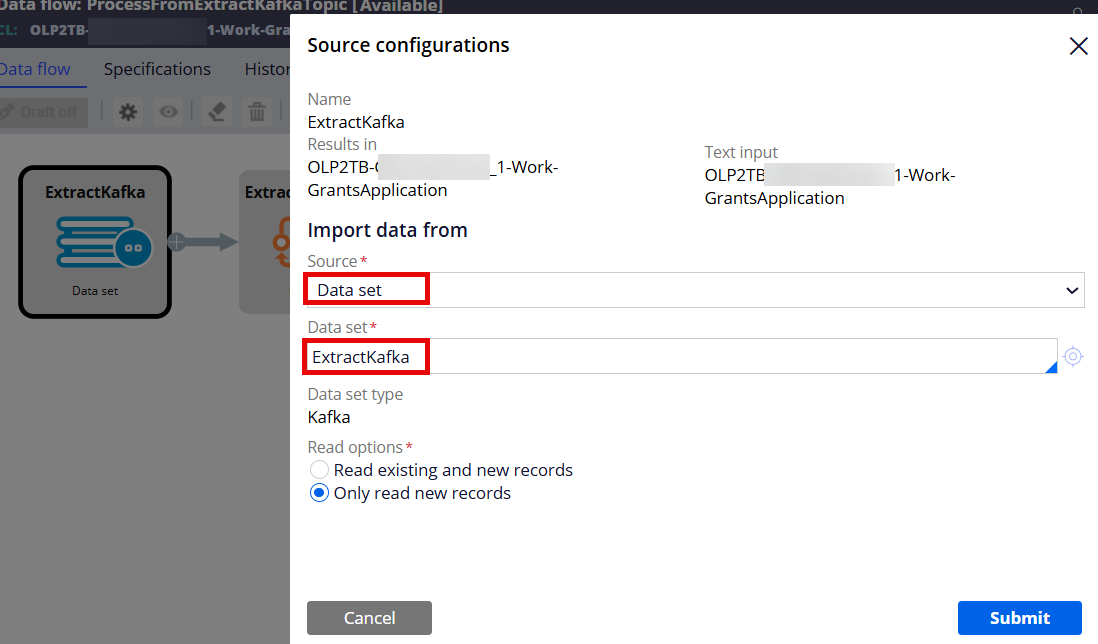
Destination: Data Set/Database Table (created above)
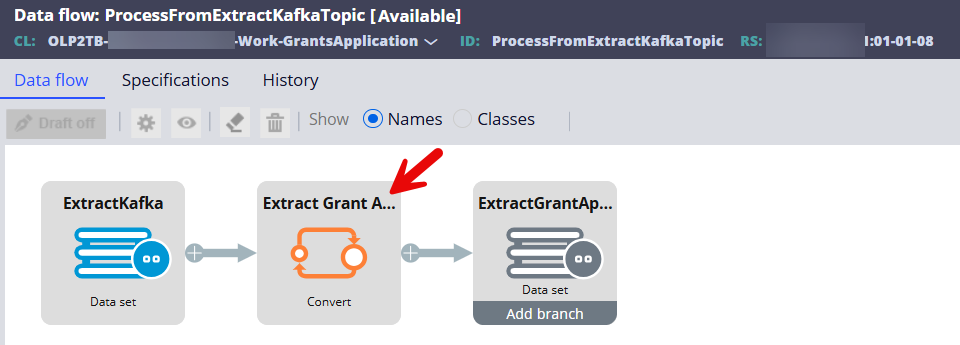
Step 2 - Insert the Convert shape to convert and map the work class properties to the data class properties.
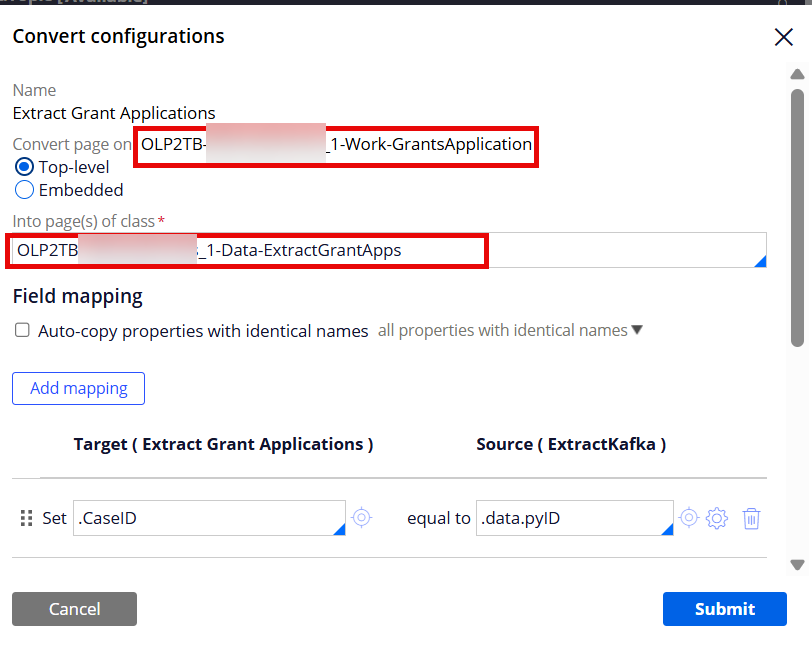
Set the field mappings. The source comes from Kafka. Notice that the extracted source properties are placed under .data Page property. The target properties are defined in the data class.
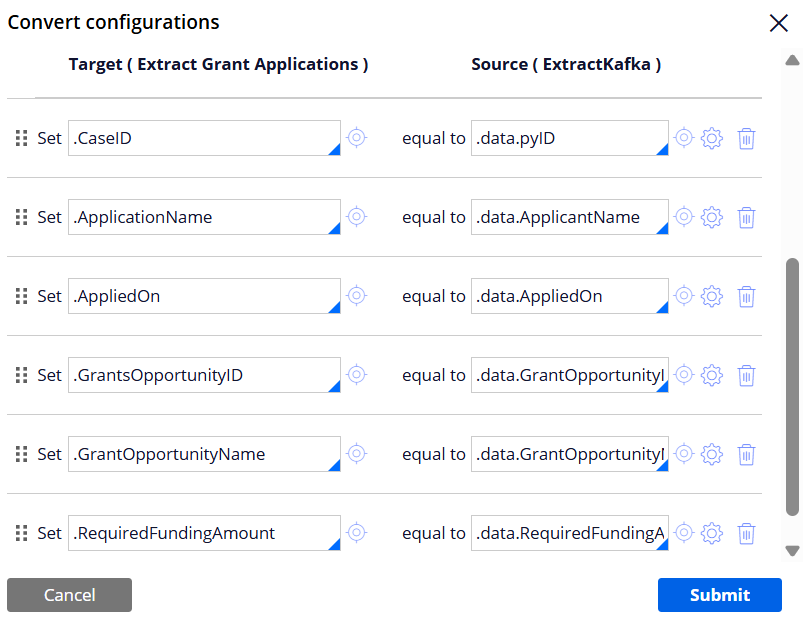
Note: I manually created .data Singe Page property under the GrantsApplication work class and referenced the work class name in the Page definition field.
## Part E - Run a test.
Step 1 - Start the Data Flow (Click Actions > Run)
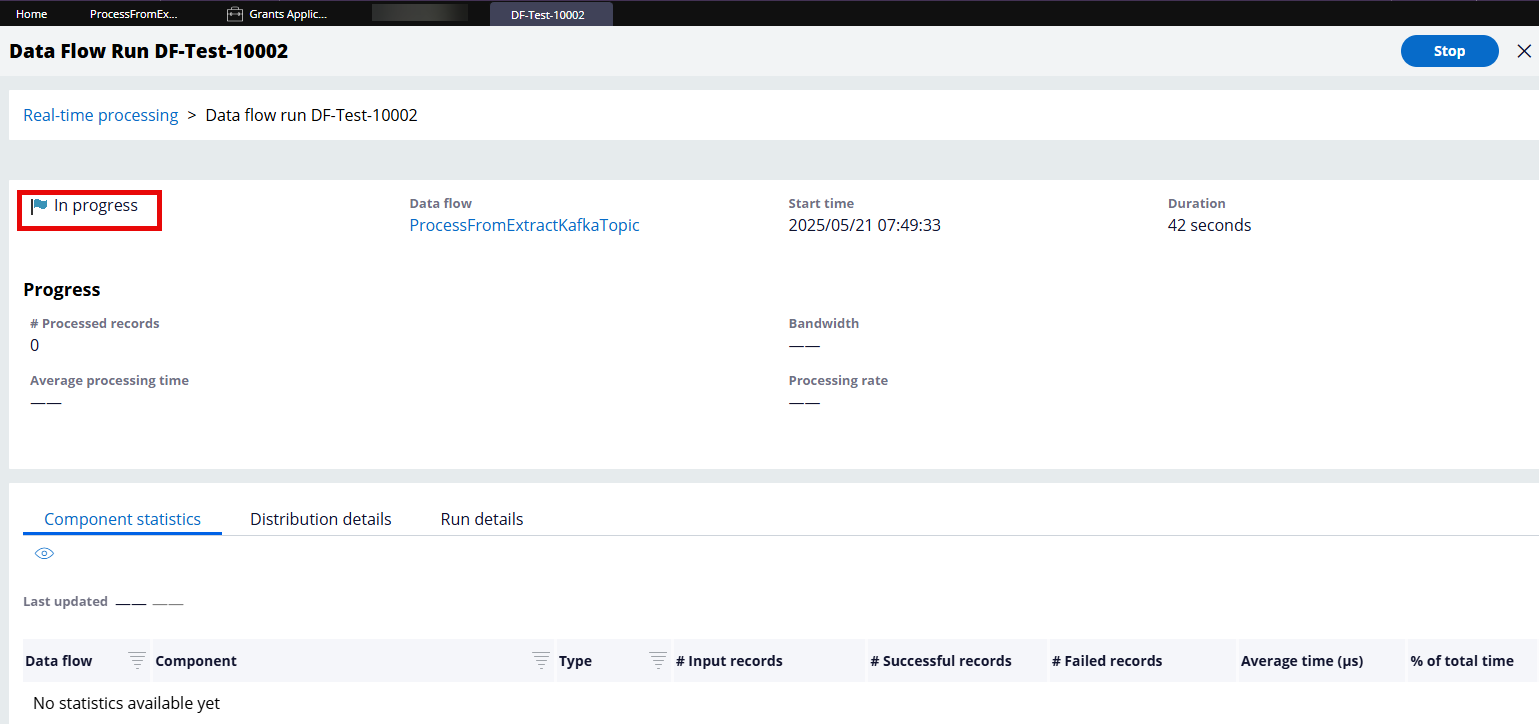
At this point, the Data Flow is running and listening to the Kafka topic in real-time.
Step 2 - Create and submit a GrantsApplication case through different stages in its case lifecycle.
This will save/commit the case to the work table, which will trigger the real-time BIX extraction and publish the case properties to the Kafka topic.
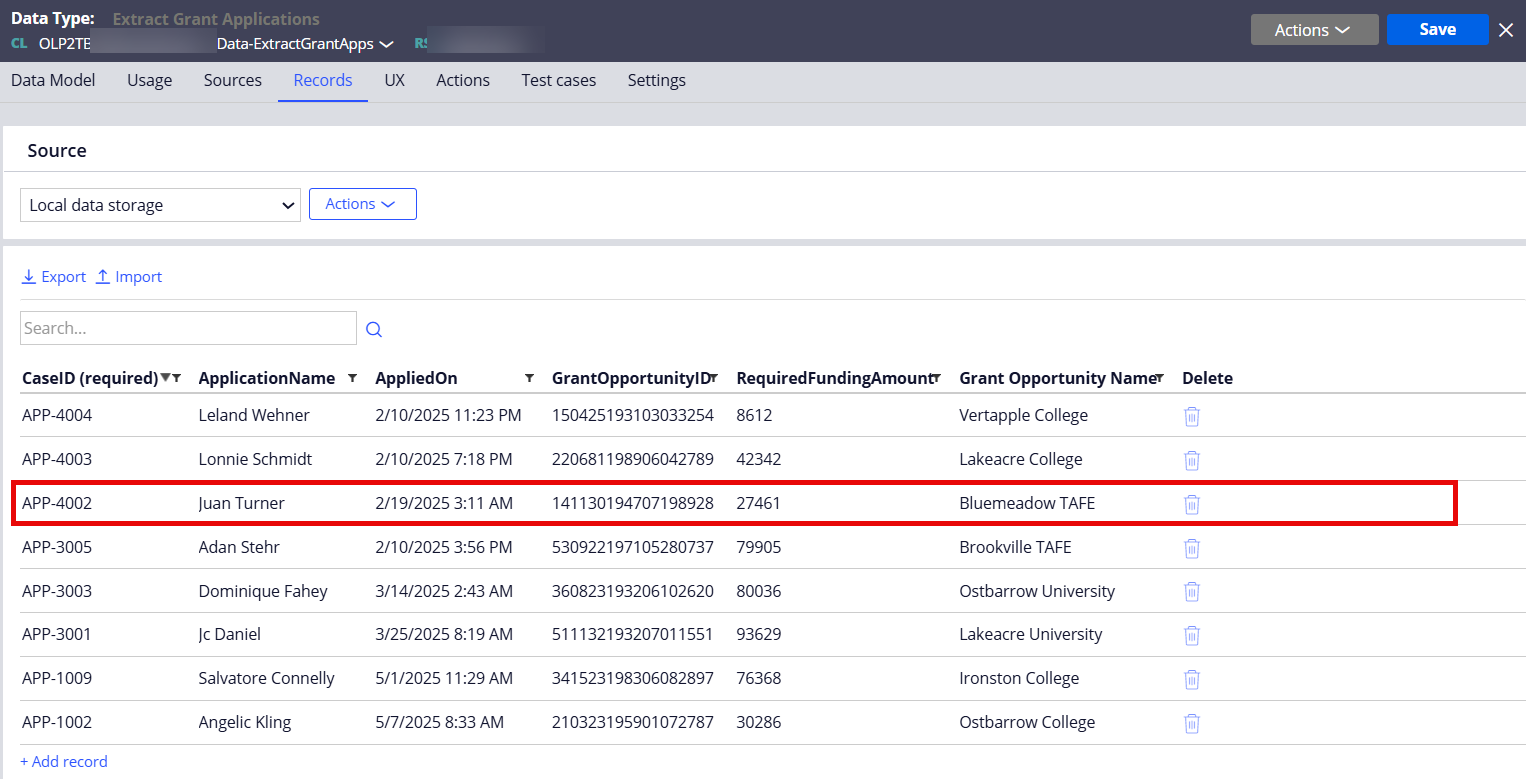
In this example, APP-4002 case had been processed and resolved.
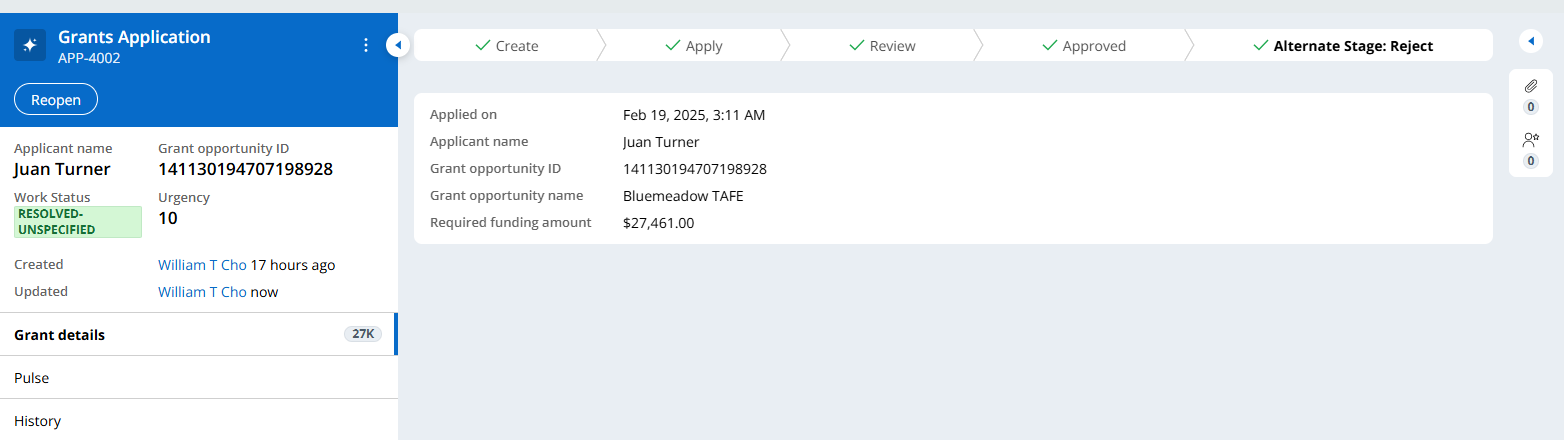
As the case is created and processed, the real-time event is fired using the Declare Trigger (auto generated).
The following Tracer shows the Declare Trigger execution, which extracts and publishes the case metadata to the Kafka topic.
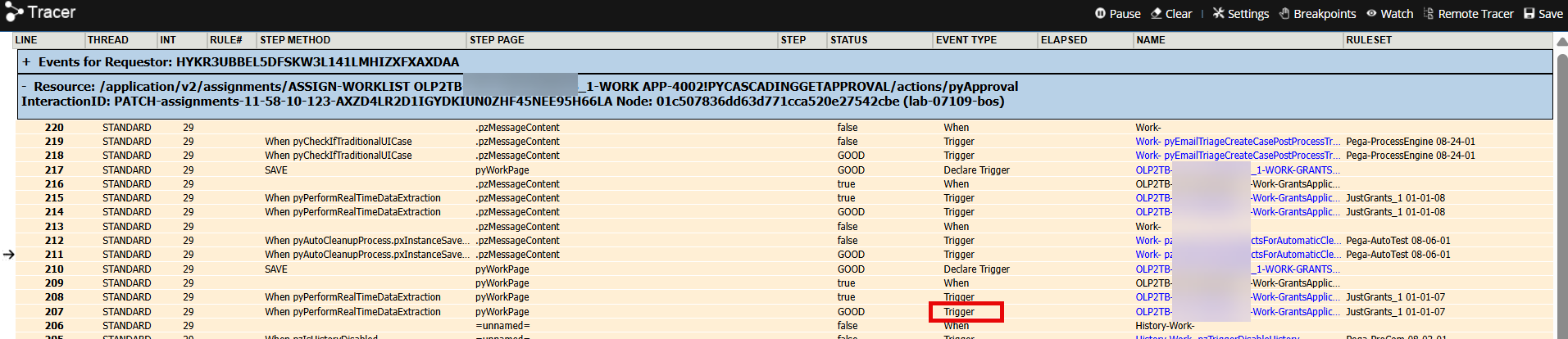
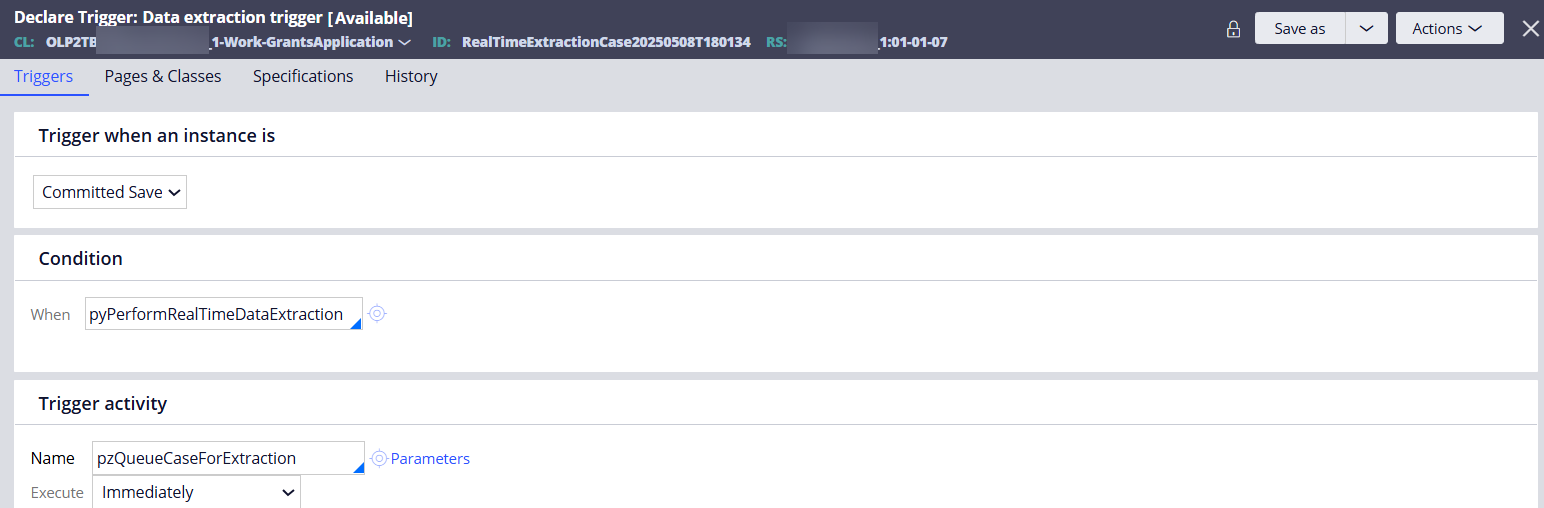
Run the Data Set (Kafka) and select the 'Browse' operation to verify the case in the Kafka topic.
As shown below, APP-4002 case details are published to the Kafka topic.
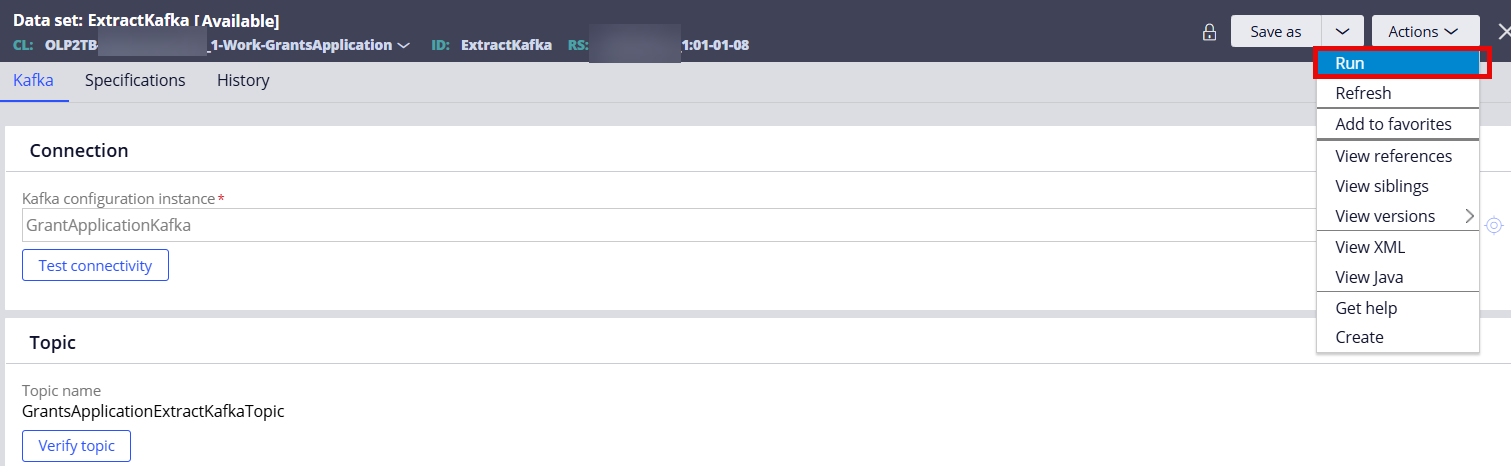
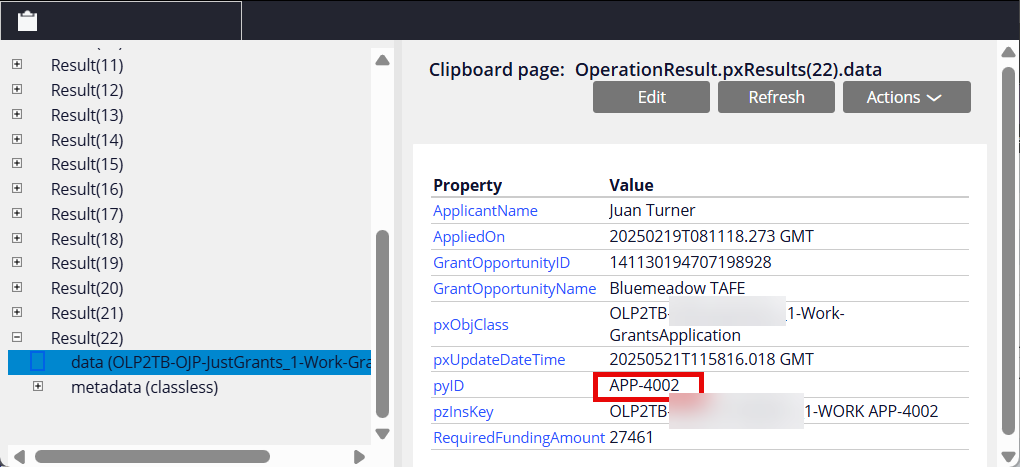
Step 3 - Verify that the Data Flow processed APP-4002 from the Kafka topic and inserted/updated the extracted case details to the database table.
In this example, 18 records got processed and updated to the destination (database table). These 18 records were added to the Kafka topic when the Declare Trigger was executed after the case got processed through different stages and saved/committed to the work table.
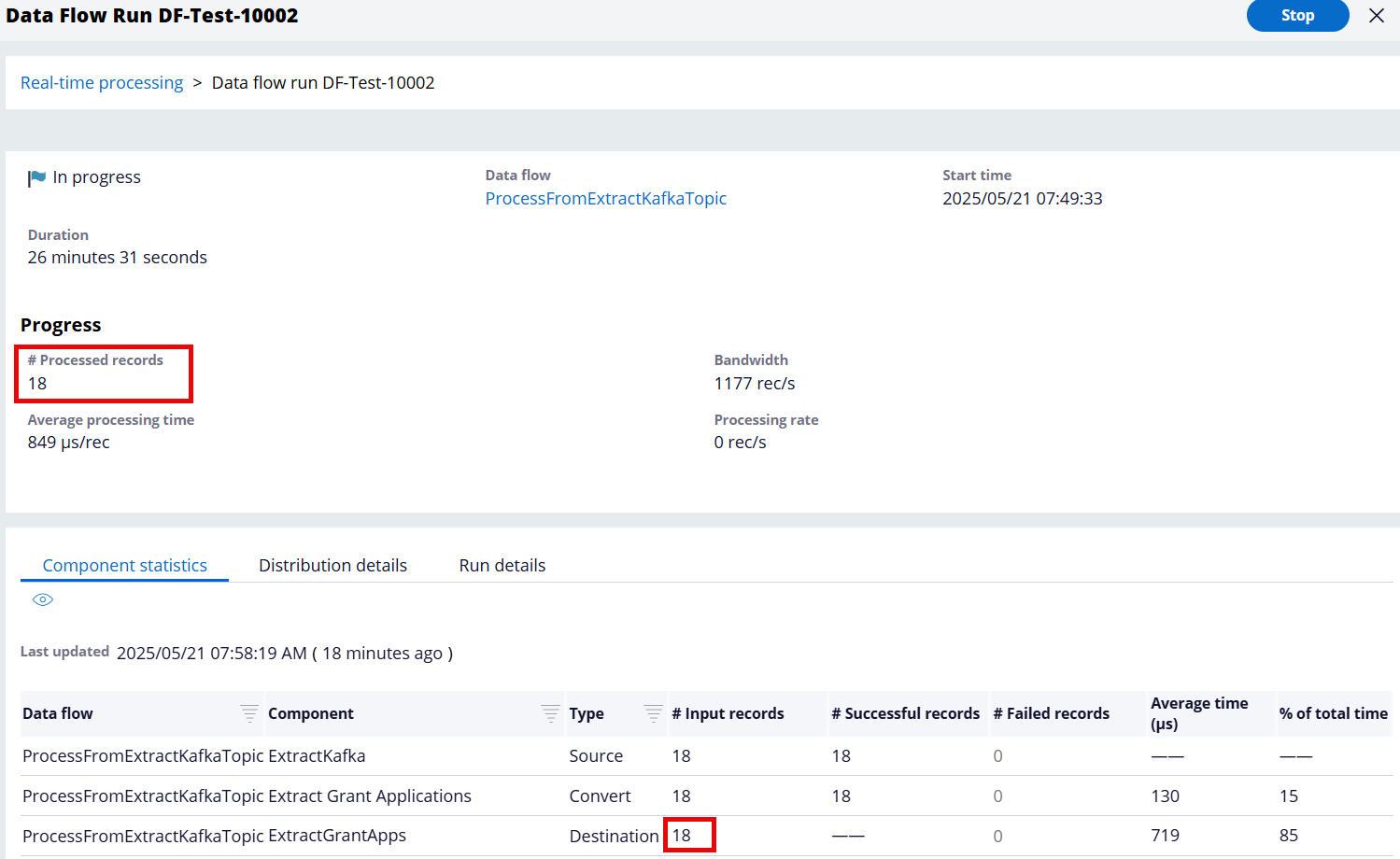
The following data type table (which is the destination of the Data Flow) now contains the APP-4002 case metadata.
Additional information
-
We need to set the 'EnableDataExtraction' release toggle ON to make the real-time extraction to work.
-
Found this BIX FAQ useful: https://docs.pega.com/bundle/platform/page/platform/reporting/bix-faq.h…
-
I'm hearing that Data Flow might be a separate license. Please check with your Pega account contact.
-
When a case was manually submitted and saved/committed to DB, the real-time BIX extract was triggering as expected. However, when I created and saved/committed cases using a background process by Data Flow (Batch), the real-time BIX extract was NOT firing. Created INC-C21257 to validate this observation. I would expect the real-time extraction to work for both scenarios. Response from Pega Engineering (5/22/25): For data flow, the declare triggers are disabled by default due to performance issues.
-
Ensure that your application is added to the System Runtime context. It is required for the standard queue processor activity "pzProcessChangeDataCaptureCaseTypes" invoked by the real-time extract Declare Trigger rule.
-
If you want to try the BIX extract APIs, refer to the draft document attachd. Product Team is currently working to publish a more formal documentations. In addition, if you go to the 'OpenAPI' tab in the Service REST' rule form, you can also find more API details. Here is the example of api/extract/v1/registration and a sample response. The registration ID will be passed to the api/extract/v1/connect/{reg ID} to get the extracted case/data (see a sample response JSON below).
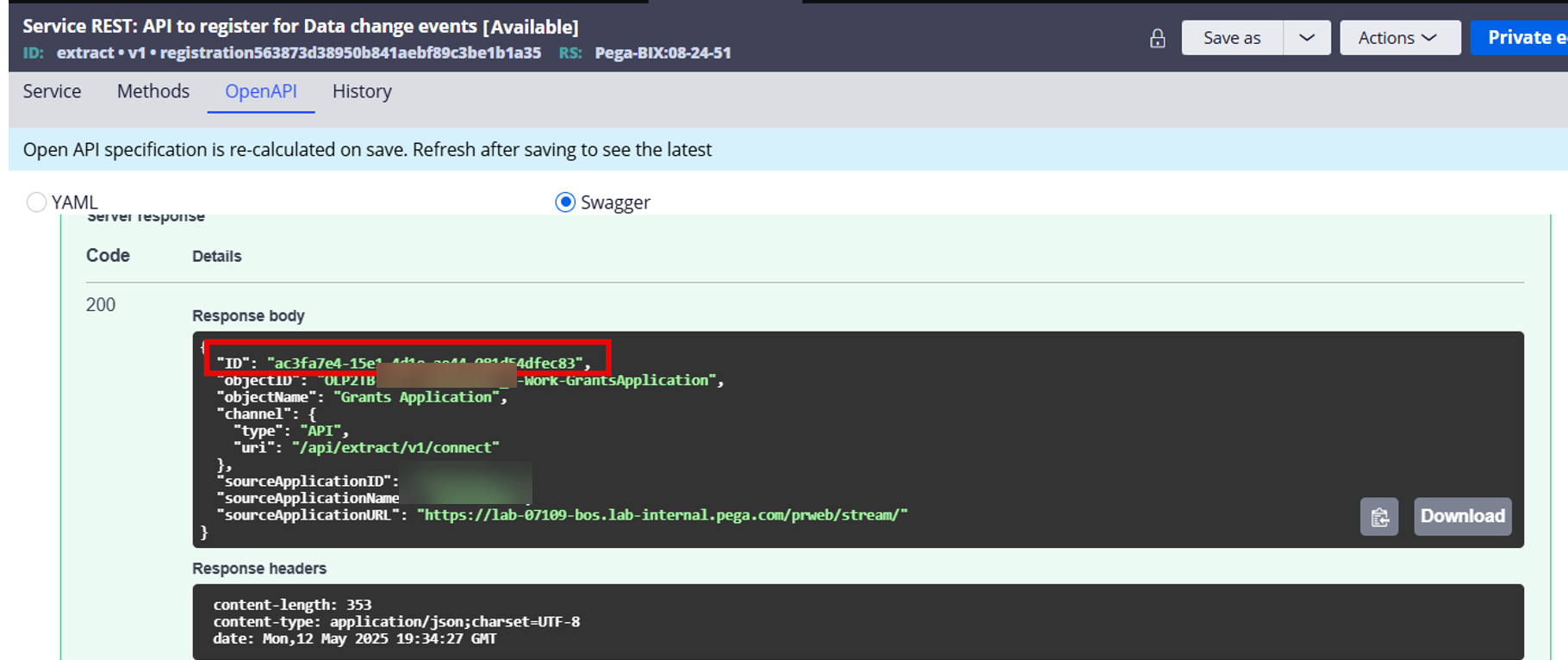
- Here is a sample response JSON of the connect api.
{
"metadata": {
"eventDateTime": 1747160313341,
"eventType": "UPDATE",
"messageType": "EVENT",
"objClassName": "OLP2TB-XXX-XXX-Work-GrantsApplication",
"objType": "CASE",
"primaryKeys": "OLP2TB-XXX-XXX-WORK APP-1001"
},
"data": {
"pxObjClass": "OLP2TB-XXX-XXX-Work-GrantsApplication",
"pyID": "APP-1001",
"GrantOpportunityID": "130534193601314026",
"ApplicantName": "Gilma Shanahan",
"GrantOpportunityName": "Brighthurst University",
"pzInsKey": "OLP2TB-XXX-XXX-WORK APP-1001",
"AppliedOn": "20250227T222010.478 GMT",
"RequiredFundingAmount": "36171",
"pxUpdateDateTime": 1747160313341
}
}
- Currently, there are two recommended approaches - 1) Use the provided APIs to read from internal kafka, or 2) Use an external Kafka.
Please leave any question or comment.
Tokio Marine HCC
GB
@Will Cho: Very good article . It will be great if you can configure kafka instance in azure where message will land .Most organisation will send kafka message outside pega . I am working on sending it to Azure Event Hub and will keep you updated on progress.
Pegasystems Inc.
US
@NavdeepK2565 Pega BIX real-time extraction should also work with external Kafka. Some clients may prefer that. It will be great to know how it turns out with Kafka in Azure. Please keep me posted.
Credera
GB
@Will Cho I tried configuring real-time BIx extraction for my case type, but it’s not working. The data flow is also in a running status.
Does the first extraction need to be a batch extraction (as mentioned in the article below)? Or am I missing something else?

Tokio Marine HCC
GB
@Arunkum@r : Did you tried to run real time BIX to push data outside pega in azure event hub or just like Will in pega event hub.
can you drop me mail at Proprietary information hidden i have few question , we can connect.
Credera
GB
Updated: 22 May 2025 12:47 EDT
Pegasystems Inc.
US
@Arunkum@r I did not have to do a batch extraction. Can you check if you set this toggle ON?
Pega Platform™ is shipped with the EnableDataExtraction release toggle that needs to be enabled.
Reference: https://docs.pega.com/bundle/platform/page/platform/reporting/bix-faq.h…
Some debugging suggestions:
- Use an activity (DataSet-Execute method) to manually push some case data to your DataSet/Kafka and see if the Data Flow would process it.
- You can also run the Data Set/Kafka and select 'Browse' to verify that the data exists in the Kafka topic. You will see the clipboard view.
- Trace to verify that the extraction Declare Trigger is fired when a work object is saved/committed to the work table.
- Verify that the new Declare Trigger is automatically generated by the system when you enabled the real-time option in the Extract rule.
Credera
GB
Hi @Will Cho,
Thanks for your response.
I’ve verified that the toggle is ON.
When I create a case, I also confirmed that the "RealtimeExtract" trigger is running properly, and the Queue Processor is functioning as expected.
However, when I browse the Kafka dataset (configured in the Extract rule), there are no results in the dataset.
So, I’m not sure what might be wrong with the Realtime Extract rule.
Pegasystems Inc.
US
@Arunkum@r Do you get a successful test connection to the Kafka topic? Tested both in the Kafka instance and Data Set. If so, then i would raise an issue ticket with GCS.
Pegasystems Inc.
US
@Arunkum@r I meant you or your account team to raise a ticket with GCS and follow up directly.
Credera
GB
@Will Cho I found the root cause of my issue: my application was not added to the System Runtime context 😭 , which is required for the standard queue processor activity "pzProcessChangeDataCaptureCaseTypes" invoked by the real-time extract Declare Trigger rule. and it is working fine now.
Thank you so much for the support.
Pegasystems Inc.
US
@Arunkum@r Glad that it got resolved. Thanks for sharing the additional piece of information about real-time BIX extraction. Very helpful!
Credera
GB
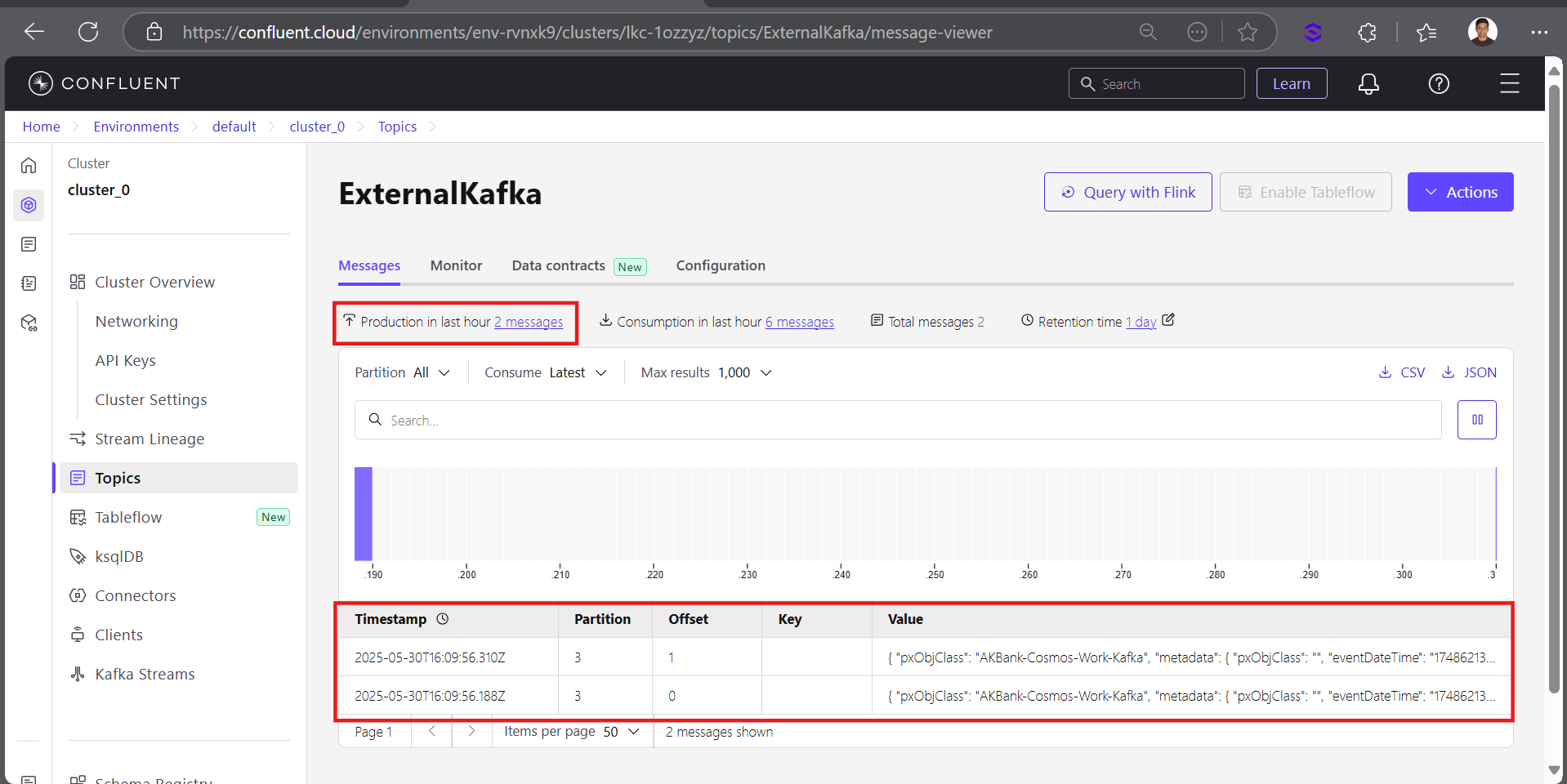
@Will Cho I tested Pega BIX real-time extraction by creating a cluster and topic in Confluent Cloud, and it worked very well. However, I noticed an issue: whenever I delete an existing real-time extract rule in Pega and create a new extract rule, the Declare Trigger rule is not created automatically. I have to create it manually and reference the trigger activity "pzQueueCaseForExtraction".
Updated: 4 Jun 2025 8:05 EDT
Pegasystems Inc.
US
@Arunkum@r Glad to hear that the real-time BIX extract also works well with External Kafka using Confluent Cloud!
When you get a chance, could you raise an incident ticket with Pega regarding the Declare Trigger issue and provide details? From what i read, it may be a bug. The new Declare Trigger should be automatically created after deleting old and creating a new Extract rule.
Genworth Financial, Inc.
US
@Arunkum@r - I'm working on similar implementation on streaming case data to confluent cloud, i had issues while check-in process for the extract rule when enabled real time processing. I had to create the when rule(pyPerformRealTimeDataExtraction) manually now declare trigger got created and it is running, I had traced the QP as well and no errors in the QP. the problem is I'm not able to messages in the confluent cloud, i can see that topics are getting created but the data is not getting posted, any insights?
Erste Digital
AT
@Will Cho When defining the convert shape of data flow as you mentioned, I am getting error like 'data' property is not defined in work class.I have peviewed my source data set and it is also storing data into .data page property.Did you define this .data property of source anywhere additionally?
Pegasystems Inc.
US
@RumelaBasu Yes - create .data Singe Page property under your work class and reference the work class name in the Page definition field.
Erste Digital
AT
@Will ChoYes, I Already have done the same and it's working, as PEGA is handling it automatically , I expected the page property 'data' to be already present.Only one thing, I had few properties within the embedded Customer page to be extracted: pyWorkPage.Customer.CustomerName, only top level properties are being picked up, not the embedded page properties. Do I need to do something additionally Or there is any restriction?
Pegasystems Inc.
US
@RumelaBasui believe embedded page properties should be also extracted in BIX. In my project, our Extract rules contain many embedded properties. Does your embedded properties extract fine using a batch mode? I would assume that it works for both batch and real-time extractions. I would suggest to raise a ticket with GCS to double check.
Cognizant
IN
@Will Cho Can you please share some details on the API based approach? Metadata, Registration and Connect all the API are working fine however in the connect API response not getting any value (expecting it to be a JSON) other than status code 200.
Updated: 10 Jun 2025 8:14 EDT
Pegasystems Inc.
US
@ParthasarathiRC please see the update in the Additional Information section. I just shared my findings regarding the BIX extract APIs. I was also able to use Postman to call the registration API and then call connect API (pass the registration ID parameter) to get the extracted case/data.
Product Management is currently working to publish a formal documentation of the extract APIs.
If you want to know how to create OAuth2 access token, i wrote another article - https://support.pega.com/discussion/create-oauth-20-access-token-call-p….
Cognizant
IN
@Will Cho I'm attaching one document which detailed the steps I followed. I'm still not getting any response. I would really appreciate your help. Thanks!
Updated: 11 Jul 2025 10:22 EDT
Pegasystems Inc.
US
@ParthasarathiRC Can you use a work class and extract properties from BLOB? Invoke the connect API and it will listen for an event. While the connect api is running and polling, create a new work object and submit through the different stages to cause the work object to be Saved/Committed to trigger the real-time extraction Declare Trigger. Then, the response should come. In this example, the response came when i created/submitted a new work object while the connect API was polling for a new event.
[
{
"metadata": {
"eventDateTime": 1749728746911,
"eventType": "CREATE",
"messageType": "EVENT",
"objClassName": "OLP2TB-XXX-XXX-Work-GrantsApplication",
"objType": "CASE",
"primaryKeys": "OLP2TB-XXX-XXX-WORK APP-2002"
},
"data": {
"pxObjClass": "OLP2TB-XXX-XXX-Work-GrantsApplication",
"pyID": "APP-2002",
"ApplicantName": "Will Cho",
"pzInsKey": "OLP2TB-XXX-XXX-WORK APP-2002",
"pxUpdateDateTime": 1749728746907
}
}
]If there is no event, i also get nothing. The connect api spins for a while and then finishes with no response.

@ParthasarathiRC Can you use a work class and extract properties from BLOB? Invoke the connect API and it will listen for an event. While the connect api is running and polling, create a new work object and submit through the different stages to cause the work object to be Saved/Committed to trigger the real-time extraction Declare Trigger. Then, the response should come. In this example, the response came when i created/submitted a new work object while the connect API was polling for a new event.
[
{
"metadata": {
"eventDateTime": 1749728746911,
"eventType": "CREATE",
"messageType": "EVENT",
"objClassName": "OLP2TB-XXX-XXX-Work-GrantsApplication",
"objType": "CASE",
"primaryKeys": "OLP2TB-XXX-XXX-WORK APP-2002"
},
"data": {
"pxObjClass": "OLP2TB-XXX-XXX-Work-GrantsApplication",
"pyID": "APP-2002",
"ApplicantName": "Will Cho",
"pzInsKey": "OLP2TB-XXX-XXX-WORK APP-2002",
"pxUpdateDateTime": 1749728746907
}
}
]If there is no event, i also get nothing. The connect api spins for a while and then finishes with no response.
Besides, this is my setting in extract service package. i'm using OAuth 2.0 authentication and passing the access token in Postman when invoking extract APIs.
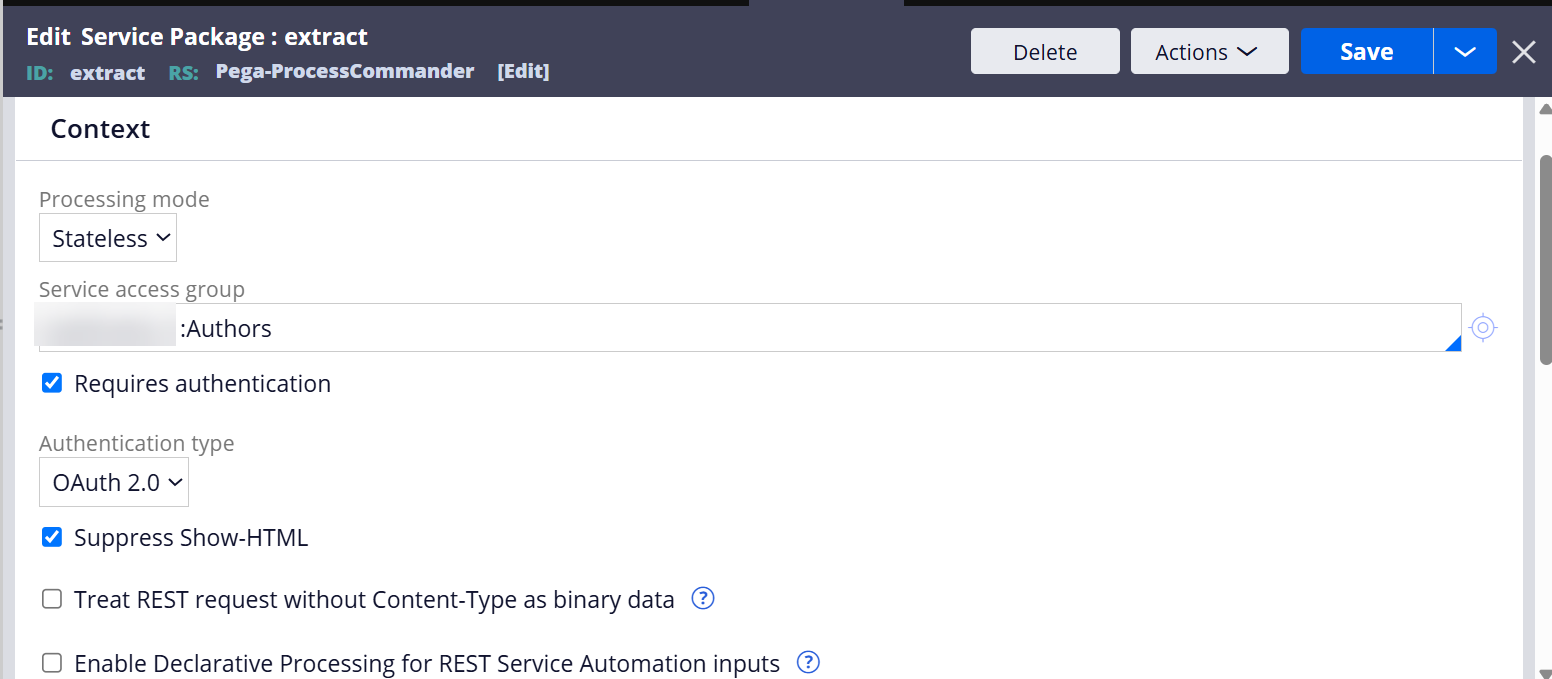
Pegasystems Inc.
US
@ParthasarathiRC i only tested with work object, but i would think data object should work, too. Can you force the data instances to resave/commit to DB (e.g. using activity rule) and verify that the real-time extraction Declare Trigger runs? You should be able to use the Tracer. There needs to be an event that cause the DB save/commit to fire the Declare Trigger while the connect api is running and polling.
Tokio Marine HCC
GB
@William Cho : Does real time bix extract via kafka stream supports oAuth2.0 . Without this our network security will not accept the solution. Any suggestion ?
Updated: 11 Jul 2025 10:31 EDT
Pegasystems Inc.
US
@NavdeepK2565 If you read the threads above, i used OAuth 2.0 to call extract APIs. I would also suggest to check with your Pega account contact to confirm.
This article may provide useful information about creating OAuth 2.0 access token.
Updated: 30 Nov 2025 22:30 EST
Virtusa
US
@Will Cho, thanks for the detailed article. I have a couple of questions about real-time data extraction and would appreciate your inputs:
-
When real-time extract is enabled for a case type, messages first go to the
pzRealTimeDataExtractiontopic before being streamed to the custom Kafka topic configured in the BIX Extract rule (“Stream data using data set”). What is the purpose of this temporary topic? Can it be enabled only when needed(when system is unable to connect to external kafka or API based extraction is used? Isn't redundant.? -
How does Pega consume messages from
pzRealTimeDataExtractionand push them to the destination? I don't see a data flow . Could you clarify the mechanism?
Pegasystems Inc.
US
@SRIDHAR.N Thanks for your in-depth questions. Unfortunately, i don't have much insight into how the product is architected internally. My understanding is mainly around the low-code configurations. I would suggest to submit a service request (SR-) ticket to Pega to validate your questions or post a question to Pega Community. If your project has an assigned Pega account manager, the person may be also able to find an internal Pega SME to help with your questions.