Discussion
Pegasystems Inc.
US
Last activity: 4 May 2021 9:28 EDT
Ask the Expert - Pega Search with Pawel Szadkowski
Join Pawel Szadkowski @szadp as he answers your questions on search and indexing, clustering (in search context), and reporting on top of search data!
Gather your questions now, save this to your Favorites and be prepared to join us for our 2-week session April 12th - April 23rd here in the Pega Collaboration Center!

Meet Pawel:
Pawel is the Product Manager for Search (Indexing, Searching), Reporting, and NativeSQL. He has been with Pega for almost 7 years now! Before then he was working with Antenna and Volatis, giving him 15 years all together!
Message from Pawel:
I am very excited to answer your questions as they pertain to Search! In my time here at Pega, I have experience working with DSM (External Data Flows, DDS/Cassandra, Big Data Connectors and Datasets, e.g. HDFS), PDC, Data Engine and now Search and Reporting areas! Having this experience helps to give me a broader vision across Pega Platform and how everything fits together! Also, not to mention it helps to have a more complete undestanding on our client and partner use cases and needs!
Pegasystems Inc.
US
Morgan Stanley
CA
@szadp Thanks for this opportunity.
Can you explain the end to end flow between various components for an item to be indexed? (e.g. when an item gets saved into tables like pr_sys_queue_ftsindexer, pr_sys_delayed_queue. when they get picked up by queue processor. How they get pushed to stream service, etc.)
What's the difference between adding a search node directly on Pega UI (System > Setting > Search) vs. defining the node type as "Search"?
Updated: 14 Apr 2021 10:32 EDT
Pegasystems Inc.
US
There are a lot of different QPs and Job Schedulers that at least seem to relate to search indexes, for example:
pyPegaIndexer
pyManageIncrementalIndexer
pyArchival_Reindexer
pyBIBatchIndexProcessor
pySASBatchIndexProcessor
pyBatchIndexClassesProcessor
If these are related to search and indexing, what are they intended to do?
When would the BI* or SAS* IndexProcessors be used?
Updated: 15 Apr 2021 8:05 EDT
Pegasystems Inc.
PL
Hi Nick,
We indeed has few Queue Processor instances which are responsible for indexing data to ES or SRS. You can identify three groups:
Dispatching
- We use pzStandardProcessor for that matter, with activity called pzFTSBatchIndexMessanger which is handling full re-index operations for embedded and external ES modes. SRS deployments does not depend on this Queue Processor and invokes proper APIs directly from rules layer, e.g. from Search Landing Page
Incremental indexing
- Both ES and SRS modes are using their own Queue Processors to progress with indexing of incremental changes. For SRS we use pySASIncrementalIndexer and for ES we use pyFTSIncrementalIndexer.
- Those processors are pushed with events for every change in a system which is triggered by obj-save and/or obj-commit operations (or by corresponding pega API Java methods). Therefore, both processors are contributing to real-time synchronization of Pega Database and Search data.
- In addition to this there is one more Queue Processor - pyBIIncrementalIndexer. It is responsible for incremental indexing to the BI system but this deployment mode is currently deprecated
Full re-index
Hi Nick,
We indeed has few Queue Processor instances which are responsible for indexing data to ES or SRS. You can identify three groups:
Dispatching
- We use pzStandardProcessor for that matter, with activity called pzFTSBatchIndexMessanger which is handling full re-index operations for embedded and external ES modes. SRS deployments does not depend on this Queue Processor and invokes proper APIs directly from rules layer, e.g. from Search Landing Page
Incremental indexing
- Both ES and SRS modes are using their own Queue Processors to progress with indexing of incremental changes. For SRS we use pySASIncrementalIndexer and for ES we use pyFTSIncrementalIndexer.
- Those processors are pushed with events for every change in a system which is triggered by obj-save and/or obj-commit operations (or by corresponding pega API Java methods). Therefore, both processors are contributing to real-time synchronization of Pega Database and Search data.
- In addition to this there is one more Queue Processor - pyBIIncrementalIndexer. It is responsible for incremental indexing to the BI system but this deployment mode is currently deprecated
Full re-index
- Full re-index is split into two parts, prepare events for every class which should be re-indexed and process such events by loading and sending data to ES / SRS
- Preparation phase is handled by pySASBatchIndexClassesProcessor (SRS) and pyBatchIndexClassesProcessor (ES). Those Queue Processors are populated by events for classes (directly or from pzStandardProcessor) and then produces events for the second (indexing) phase. Every event is a batch of actual item ids (e.g. case instances) which should be indexed in single request to SRS/ES for performance reasons. That way we distribute indexing cross all configured nodes and threads as second phase Queue Processors are split into multiple partitions and every partition is handled by one of the threads on one of the nodes
- Actual indexing (second) phase is handled by pySASBatchIndexProcessor (SRS) and pyBatchIndexProcessor (ES) Queue Processors. Those processors are responsible for loading data from Pega Database what happens for every item id found in (batch) events. As next step, items are serialized to SRS or ES format and sent in batch to corresponding engines. As mentioned earlier, this happens in distributed way what significantly improves performance in compare to previous, single node re-indexing mechanism. It also allows customers to improve performance by additional nodes or tweaks around per-node threads count. Keep in mind though that at some point performance will be controlled by the speed/load on database rather than SRS or ES
- In addition to this we have corresponding BI processors - pyBIBatchIndexClassesProcessor and pyBIBatchIndexProcessor which are working in similar way for deprecated BI indexing
Pawel
Pegasystems Inc.
US
When using the search bar in Dev Studio, I've noticed that some characters entered into the search string could potentially cause the search to return no results. I've come across this on a few occasions when searching for specific styles contained within some CSS rules. I've attached a few sample screenshots to highlight this.
Some colleagues have recommended to use a white space (spacebar) in lieu of any of these characters that seem to affect the search results. Could you clarify if there are any known special characters/delimiters that may interfere with the results of the search?
To workaround this, would the suggested approach be the aforementioned white space replacing whichever characters seem to change the behavior? Thank you!
Pegasystems Inc.
PL
Hi,
The general advice would be to indeed remove special characters or escape them. It really depends on the character itself and how it is used inside a query as different use cases may have different 'best' solutions.
Keep in mind that what we use in search gadget and in search API and what you see as a simple search string is in fact an DSL which allows you to build more complex queries than just a search for single or multiple words. Out syntax is based on Elasticsearch's query string query syntax so please refer to it for more details.
While indexing data and while performing search, there are characters which are treated as a regular part of word and there are characters which are used as a split/white characters.
All the terms/tokens can consist of:
- Digits
- Letters
- Characters: '-', '_', '!', '%', '@', '.'
It means that anything what belongs to the list above can be searched. Anything from outside of this list, like space, is treated as a split character and is used to find tokens in property values during indexing.
Some of the token characters are also part of DSL, e.g. “-“ is an Boolean “must not” operator. Depends on how you use it, it will be treated as part of the word to find or as an operator:
Hi,
The general advice would be to indeed remove special characters or escape them. It really depends on the character itself and how it is used inside a query as different use cases may have different 'best' solutions.
Keep in mind that what we use in search gadget and in search API and what you see as a simple search string is in fact an DSL which allows you to build more complex queries than just a search for single or multiple words. Out syntax is based on Elasticsearch's query string query syntax so please refer to it for more details.
While indexing data and while performing search, there are characters which are treated as a regular part of word and there are characters which are used as a split/white characters.
All the terms/tokens can consist of:
- Digits
- Letters
- Characters: '-', '_', '!', '%', '@', '.'
It means that anything what belongs to the list above can be searched. Anything from outside of this list, like space, is treated as a split character and is used to find tokens in property values during indexing.
Some of the token characters are also part of DSL, e.g. “-“ is an Boolean “must not” operator. Depends on how you use it, it will be treated as part of the word to find or as an operator:
- Used inside double quotes means it is a part of word to find
- Used inside other term characters, e.g. letters, means it is used as a part of word to find
- Used in front of the word means it is used as a Boolean operator
- When escaped it is used as a part of word to find
You can escape any of the DSL special characters, in such situation such character is used as any other in search and will be discarded and used to preprocess search query (if not belong to the list of term tokens) or used as part of word to find.
Important note: wildcard queries are not analyzed, except prefixes not impacted by the regexp expression. It means that if search contains a ‘*’ or ‘?’ character, starting from the first occurrence any white character will be used in a query as-is, making it impossible to find a document because analyzed data does not contain such characters. This is related to both CONTAINS search method and DSL usage of wildcard characters. This is default limitation in Elasticsearch and is related to the performance restrictions.
The rules around reserved and token characters in Search can be complex and may require additional analyze to understand them. In doubt please refer to Elasticsearch documentation around query_string query dsl.
Examples (please note that input assumes we need to escape double quotes and escape character like in an expression which contains text value):
- “\”Auto&Loans\”” is equivalent to “+\”Auto Loans\””
‘&’ character used inside the double quotes is used as a split/white character (is equivalent to space) and because of this we are looking for a phrase build from two words, Auto and Loans - “Auto OR \\+Loans” is equivalent to “Auto Loans”
Escaping ‘+’ means we use it as a while character and therefore, it will be removed from the second word - “Auto AND *-Loans” is equivalent to “+Auto +*-Loans”
Because ‘-‘ can be part of terms this query is searching for documents with term Auto and terms ending with ‘-Loans’, e.g. ‘Expensive-Loans’ or ‘Fast-Loans’ - “Auto AND *+Loans” is equivalent to “+Auto +*+Loans”
This query is not going to return any results because it is not analyzing/preprocessing a ‘+’ character and at the same time ‘+’ is discarded from indexed data so can’t be found in any term - “\\*Auto*” is equivalent to “+Auto*”
First ‘*’ is ignored during search query analyze as it is escaped, because it’s not part of term tokens list it is going to be removed from a query. Second ‘*’ is treated as part of DSL and used as a wildcard character. This is wildcard query but we analyze it’s prefix part which is not impacted by the second asterisk. It will match documents which contains words like “Autobahn” or “Auto-Loans” etc.
Morgan Stanley
IN
In our Pega application update few thousands of recrods on a daily basis. We show them in a grid in our UI. However, fetching these records based on user preference/filter criteria (not every user gets to see all the records, they filter and then retrive in UI).
We tried configuring RD to use ES, However, for some reason despite selecting ES in RD it's still firing a SQL Query.
How do we check as to why it falled back to DB?
Also, can we get some inputs on the limitations of using this ES i mean can you shed some light on if it supports sub reports, sql functions? etc
Pegasystems Inc.
PL
Hi,
Report definition is analyzed and marked for Search or RDBMS execution as first step when you run it. There are multiple reasons why it may want to fallback which splits into three categories:
- Functional, e.g. we do not support distinct values retrieval
- Data related, e.g. property configured in report definition is not indexed at all or is not even marked for being indexed
- Environment related, e.g. Search is unavailable or index is not available
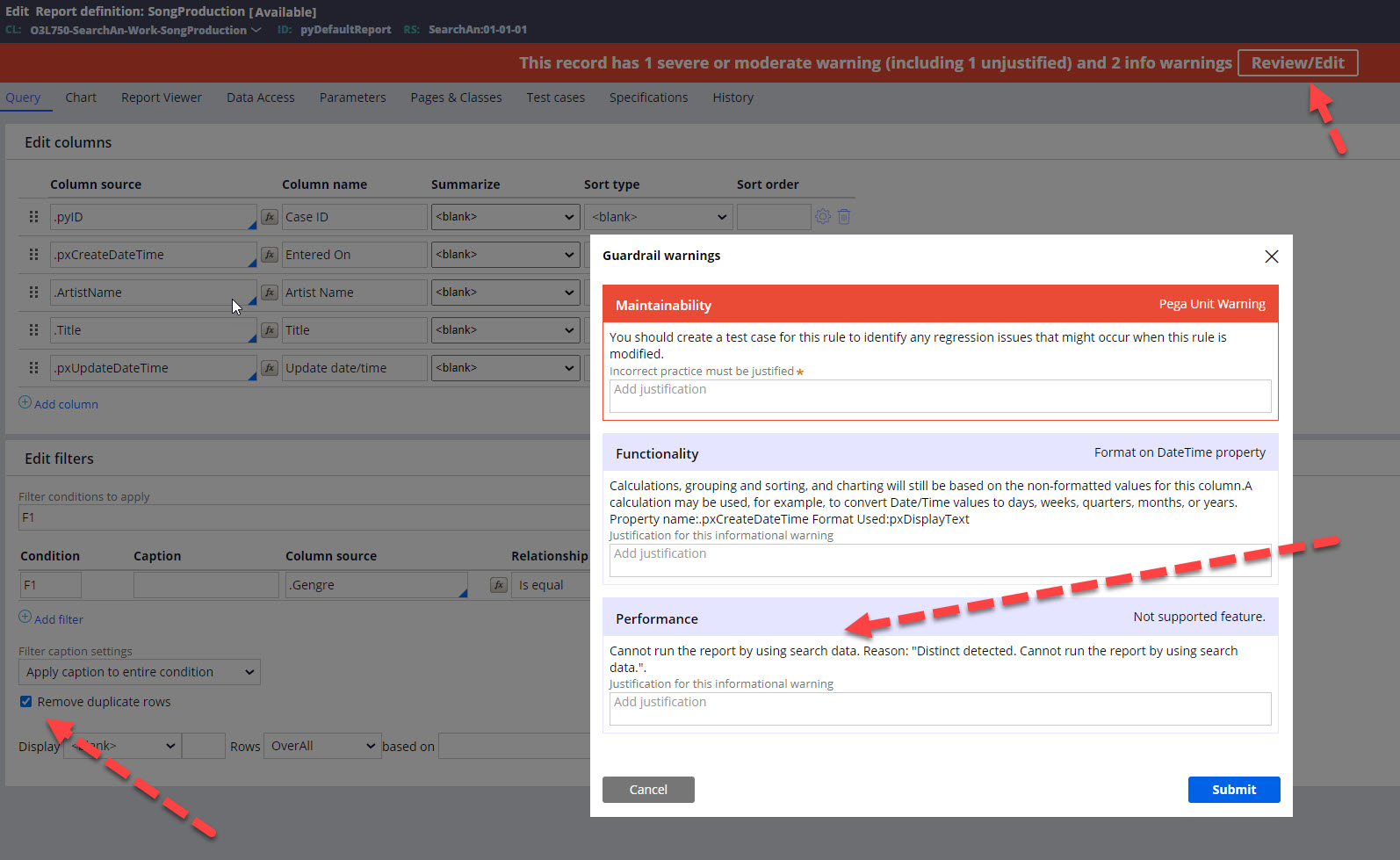
Each category will manifest it's state in a different way. During development you can monitor it via guardrails like on picture below:
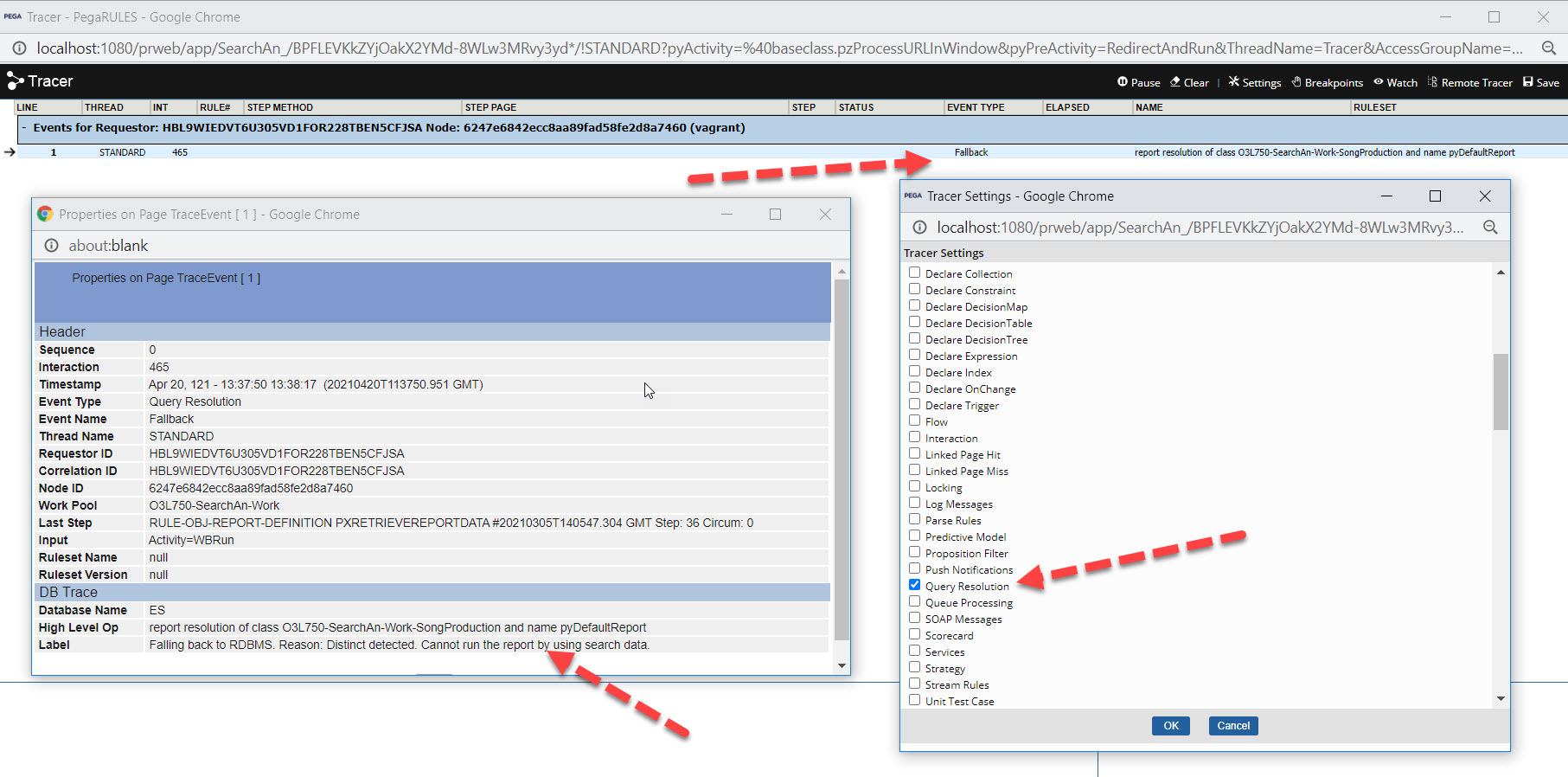
Fallbacks should be also visible in tracer, like in picture below:
You should be also able to see fallbacks in PDC as alerts and/or in issues list, this handles the environment related situations.
Hi,
Report definition is analyzed and marked for Search or RDBMS execution as first step when you run it. There are multiple reasons why it may want to fallback which splits into three categories:
- Functional, e.g. we do not support distinct values retrieval
- Data related, e.g. property configured in report definition is not indexed at all or is not even marked for being indexed
- Environment related, e.g. Search is unavailable or index is not available
Each category will manifest it's state in a different way. During development you can monitor it via guardrails like on picture below:
Fallbacks should be also visible in tracer, like in picture below:
You should be also able to see fallbacks in PDC as alerts and/or in issues list, this handles the environment related situations.
Typical fallback reasons for each category are related to missing classes, properties and property setting incompatibility. It's also worth to know that any cross-class reports like those using sub-reports or joins, in any form, are not supported at the moment. Same thing applies to function aliases which will also cause fallback.
On the other hand, summary reporting is working, except some unsupported combinations of aggregation vs grouping, and it should give performance boost in compare to RDBMS, especially for bigger data sets with less restrictive filter constraints. You should also see performance boost for any type of string related filters. I would also like to mention that Search executions are un-loading database from running reports which is another good effect of switching reports to use Search data.
Please note that a lot of type-related operations may require class to have it's own dedicated index.
Environment related fallbacks are typically causes by unavailable or disabled index or by indexing being in progress
Morgan Stanley
IN
@MarissaRogers Many times we have wondered on what exact query is being executed by a Report definition.
We have that in Prepared Values list but need to manualy substitute each and every parameter value in '?'
Do we have any easy way to get the exact query being fired
Pegasystems Inc.
PL
Hi,
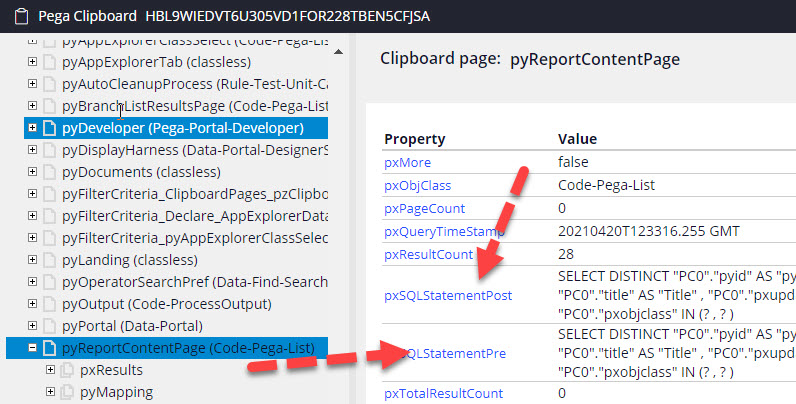
Pre and post SQL statement can be found on result page, like on picture below:
Please note that depends on the Pega version you are using you may need to setup a env variable security/showSQLInListPage to enable it
Pegasystems Inc.
PL
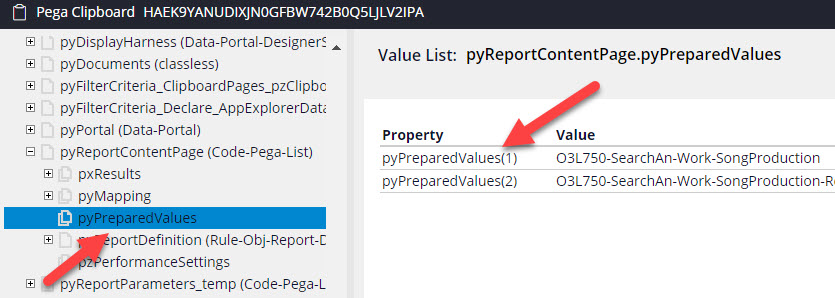
Those values can be found in pyPreparedValues list which is also available on result page:
Pegasystems Inc.
US
REMINDER:
Friday, April 23rd is the last day to get your questions in for this Ask the Expert session with Pawel @szadp
Public Safety
CA
@MarissaRogers @szadp If we need to display some unexposed properties from the Work search results in the "pyWorkSearch" report rule (or any search table specified in "pySearchReprotName" in "Work-.pySearchDefaults" Data Transform), as expected, we have server warnings associated with this report rule. But it seems that we are doing elastic search not a real SQL execution here? Can you explain how does the "pyWorkSearch" report works here?
Pegasystems Inc.
PL
Hi,
Report definition which you are saving (pyWorkSearch) is validated against DB execution, hence why you can see warnings. We do treat report definitions which are used for search queries (e.g. in search gadget) as regular reports, application may still want to use it for execution against DB. At the same time there are much less restrictive expectations when it comes to the search execution, e.g., if there are missing fields in search then search simply skips those on results page
Pegasystems Inc.
US
Does each index host node contain the entirety of the indexed data, or only a subset? Does this vary from version to version of Pega?
What kind of fault tolerance can be expected for search and indexing if one of the index host nodes is down? (Let's assume situations where you have 2, 3, and 4 index host nodes)
Pegasystems Inc.
PL
Data allocation is controlled by embedded ES and is based on so called replica instances. ES Index is split into a Lucene (underlying library) indices named as shards. Index consist of primary shards and it's replicas which are basically a copy of same data, allocated to another node for fault tolerance and high availability.
Prior 7.4 (I believe) number of replicas was based on number of nodes, where every search node was assigned primary shard or replica for it. Therefore, every node holds same data.
In never versions customer can also control number of replicas on their own by special DSS setting which allows to set max number of replicas for indices - indexing/distributed/maximum_replicas. Default value for this setting is 2 and while replica count is still calculated based on number of nodes in a cluster but it maximum caunt can be controlled by this setting.
Data allocation is controlled by embedded ES and is based on so called replica instances. ES Index is split into a Lucene (underlying library) indices named as shards. Index consist of primary shards and it's replicas which are basically a copy of same data, allocated to another node for fault tolerance and high availability.
Prior 7.4 (I believe) number of replicas was based on number of nodes, where every search node was assigned primary shard or replica for it. Therefore, every node holds same data.
In never versions customer can also control number of replicas on their own by special DSS setting which allows to set max number of replicas for indices - indexing/distributed/maximum_replicas. Default value for this setting is 2 and while replica count is still calculated based on number of nodes in a cluster but it maximum caunt can be controlled by this setting.
For example, for two nodes cluster we will allocate one replica for every shard and therefore, every node will have full copy of the data. Same thing will happen when cluster consist of three nodes, the number of replicas will be 2 and every node will have full data copy. This mode will limit number of replicas to max 2 (default value) so for bigger clusters not every node will hold full data copy but this is ok since having at least three copies of same data should be sufficient for most of the situations. Using indexing/distributed/maximum_replicas setting, operators can increase number of replicas for bigger clusters or decrease it and therefore, have impact on the quorum mechanism and potential node unavailability on indexing mechanism and data consistency guarantee.
Platform is checking data consistency and whether every index has enough active shards available. Calculations are similar to the way number of replicas is calculated but mentioned earlier setting does not impact it. To be able to index data platform will look for at least half plus one of the configured shards (primary and replicas, like described earlier) to be available/active. Otherwise, indexing process will stop to avoid potential data loss in future.
Search queries will be handled if at least one active shard is available
Pegasystems Inc.
US
What happens to new or updated work while a re-index operation is happening? Do these items get added to the queue for the batch index process or does the incremental indexer run normally and add / update them on the index undergoing this operation?
Pegasystems Inc.
PL
Hi,
Incremental indexing is progressing during batch re-index and because of this any changes to data which are made after re-index initialization will still be send to the search. Keep in mind that we queue ID and therefore read fresh data from DB before send data to ES so it doesn't matter when queued item is processed
Morgan Stanley
IN
@MarissaRogers Can you shed some light on What exactly is the relevance between ABAC and Custom Search Properties.
I've seen ABAC firing DB queries with some filter condition added.
With Custom Search Properties used as a requirement for some filter logic in ABAC, are we saying that it internally queries ES?
If Yes shouldn't ES be updated in real time?
Pegasystems Inc.
PL
Hi,
ABAC security rules are automatically included in search queries. It happens with some limitations, e.g. we do not support different property level security rules and therefore, such rule will always result in full mask of a property value.
We also assume that values used in ABAC filters are available in search, though if some of them are missing then filter will behave like if there is an empty value in property.
In addition to this, we do use so called analyzed fields with special flag indicating we want to check tokens in same order like in ABAC filter value. Please see my comment about the DSL and how search is using property values.
When it comes to the real time updates - search is eventually consistent and therefore, while we applies filters to the query immediately after you change/update them, data updates are slightly delayed. However, when you update or add your instance to search it is done for whole instance at the same time, e.g. work item is updated as a whole document, without separate updates to properties which are used in ABAC and those which are not used in ABAC. If this is not enough and you need search to be consistent with DB then I believe you should not store sensitive data in search or work on a strategy which will be secure from data consistency perspective, e.g. try to mix DB and search queries or add multi step updates
Morgan Stanley
IN
@MarissaRogers When using a Custom Search Properties rule with "Enable search results for all properties", does it pass all the properties in BLOB irrespective of its hierarchy (any page level) in ES and is available for search?
Updated: 26 Apr 2021 2:19 EDT
Pegasystems Inc.
PL
Hi,
In this mode we do store values of all properties which are sent to search, including embed pages. We use only those properties which actually have data so there is no issue with mappings overload on ES side
Morgan Stanley
IN
@MarissaRogers Could not find any articles for linking embedded ES with Kibana. For on prem any pointers on linking it with Kibana
Pegasystems Inc.
PL
Hi,
By default we do not expose our internal embedded ES structure for external use, e.g. via Kibana. Internal format is not public and may be less intuitive when used by third party tools. Therefore, while there is a way to expose REST endpoint of embedded ES, we would suggest to use it only for diagnostics purpose, ideally with client/server certificates and to disable it right after use for security reasons
Updated: 26 Apr 2021 9:47 EDT
Pegasystems Inc.
US
Hi everyone!
After talking with @szadp we've decided to extend this session one more week!
You have until this coming Friday, April 30th to ask Pawel more questions!
Pegasystems Inc.
PL
Hi John,
Search Gadget itself is not generating direct ES query and is using DSL exposed by Pega API. Such query is later additionally altered e.g.: because of non-EXACT search method etc.
The gadget's query can be seen in tracer, see what comes to the pxRetrieveSearchData activity as a pySearchString parameter's value.
If you are interested in actual query to the ES you should enable additional internal logger PegaSearch.Searcher.ESSearcher, however, starting at some point we are automatically obfuscating query for security reasons.
At the same time, you can check query in 'slow' queries by revisiting of the PEGA0054 alerts which should still contain actual query, e.g.: in PDC. To check any query you can temporarily setup alert threshold to 0 or very low value so every query is considered too slow and notified to PDC.
The threshold setting is alerts/search/operationtime_threshold
Updated: 4 May 2021 9:24 EDT
Pegasystems Inc.
US
Thank you to everyone for this fantastic session on Pega Search!
A huge thank you to our expert, @szadp for answering your questions during this 3 week session!
Until next time, check out our Ask the Expert homepage for upcoming sessions this year!
Thank you!
Our Ask the Expert session with @szadp is now open to questions!
Ask the Expert Rules