Archive case and its associated artifacts
This article demonstrates the step-by-step configurations of how to archive old, resolved cases and their associated artifacts (such as child cases, work history and attachments) in Pega.
Client use case
Client has been running Pega application for many years and the volume of resolved cases and associated data (such as history, attachments) have grown very large in size. This has been increasing the database usage and also adding an overhead to the database performance. The client requirement is to archive them to the secondary storage repository that still allows to search and view the cases but purge them from the primary database.
Configuration steps
Step 1 - Configure the archival policy for a case type.
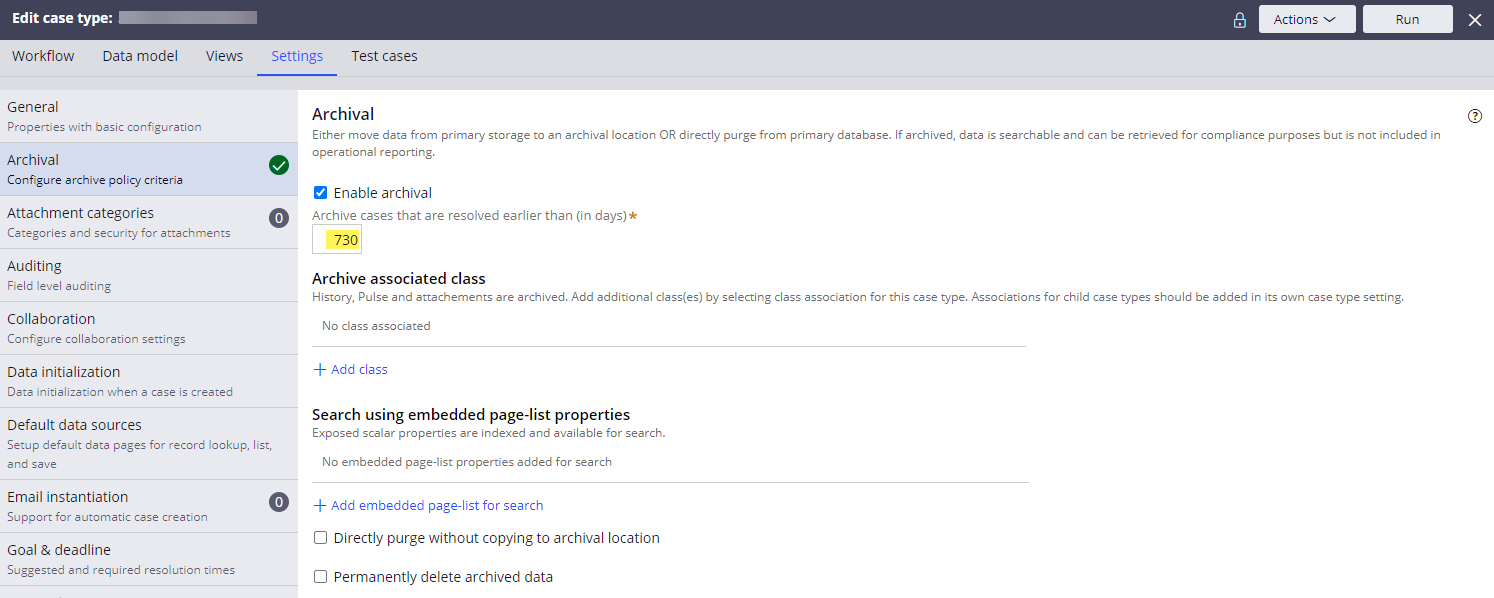
Once saved, this creates a new data instance under the Data-Retention-Policy class.
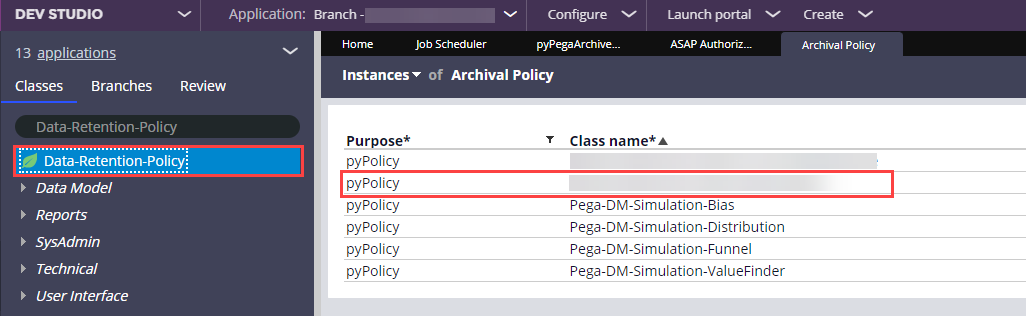
Any additional update to the case archiving policy can be made to the Data-Retention-Policy instance directly, which will also automatically reflect the change in the case type editor.
To set the archiving policy in upper environments, we packaged the Data-Retention-Policy instance from DEV and migrated. After that, we can directly update the instance as needed in each environment (i.e. we could configure a different archiving policy per environment).
Note: we had to temporarily create an unlocked ruleset version to save the new archival policy configuration from the 'Edit case type' page. Upon the save, the platform auto generated following two rules (pyDefault case type & pyDefault data transform). After a new Data-Retention-Policy instance is created, we deleted the two generated rules and temporary ruleset version and migrated only the Data-Retention-Policy instance to higher environments.

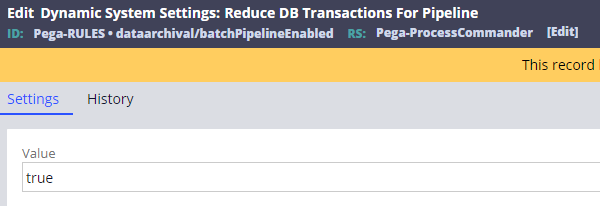
Step 2 - Set dataarchival/batchPipelineEnabled DSS to 'true'.
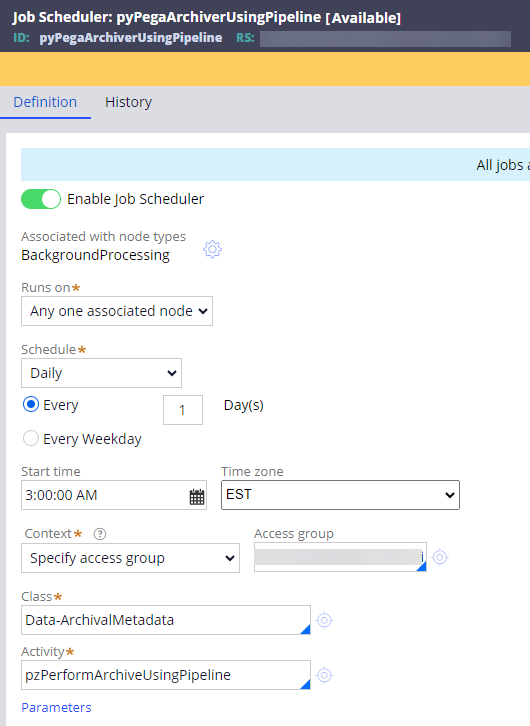
Step 3 - Enable the pyPegaArchiverUsingPipeline job scheduler and set the schedule.
- Save the OOTB job scheduler to your application ruleset and modify.
Validations
Validate 1 - Go to Admin Studio to verify that the job scheduler ran successfully.
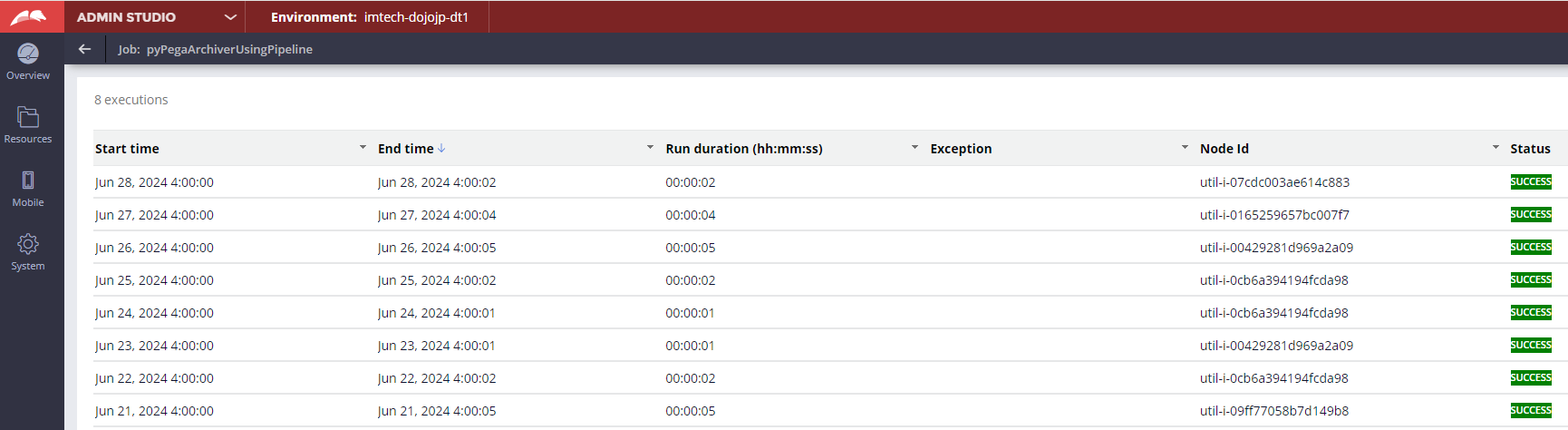
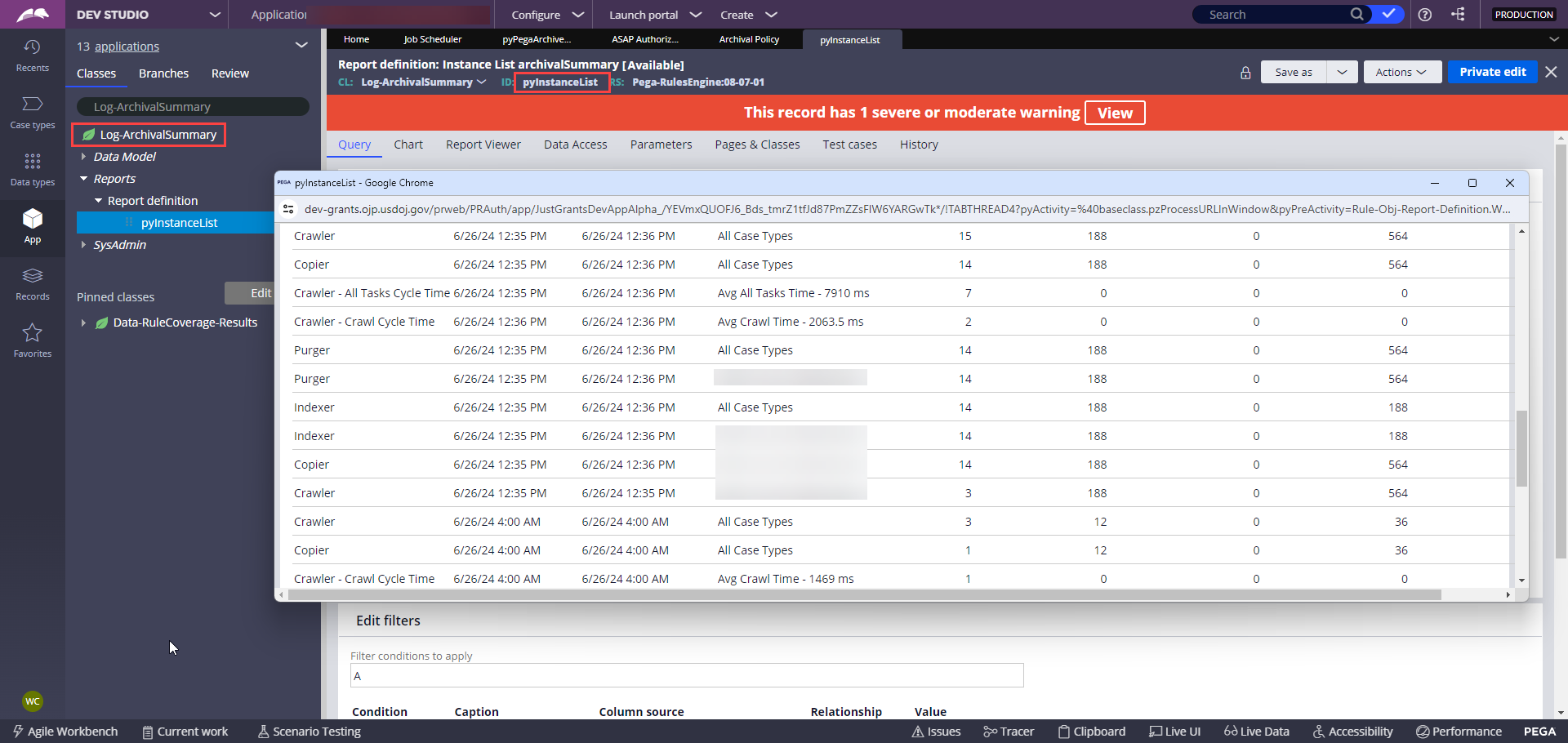
Validate 2 - Go to the Log-ArchivalSummary class and run the pyInstanceList report definition to verify.
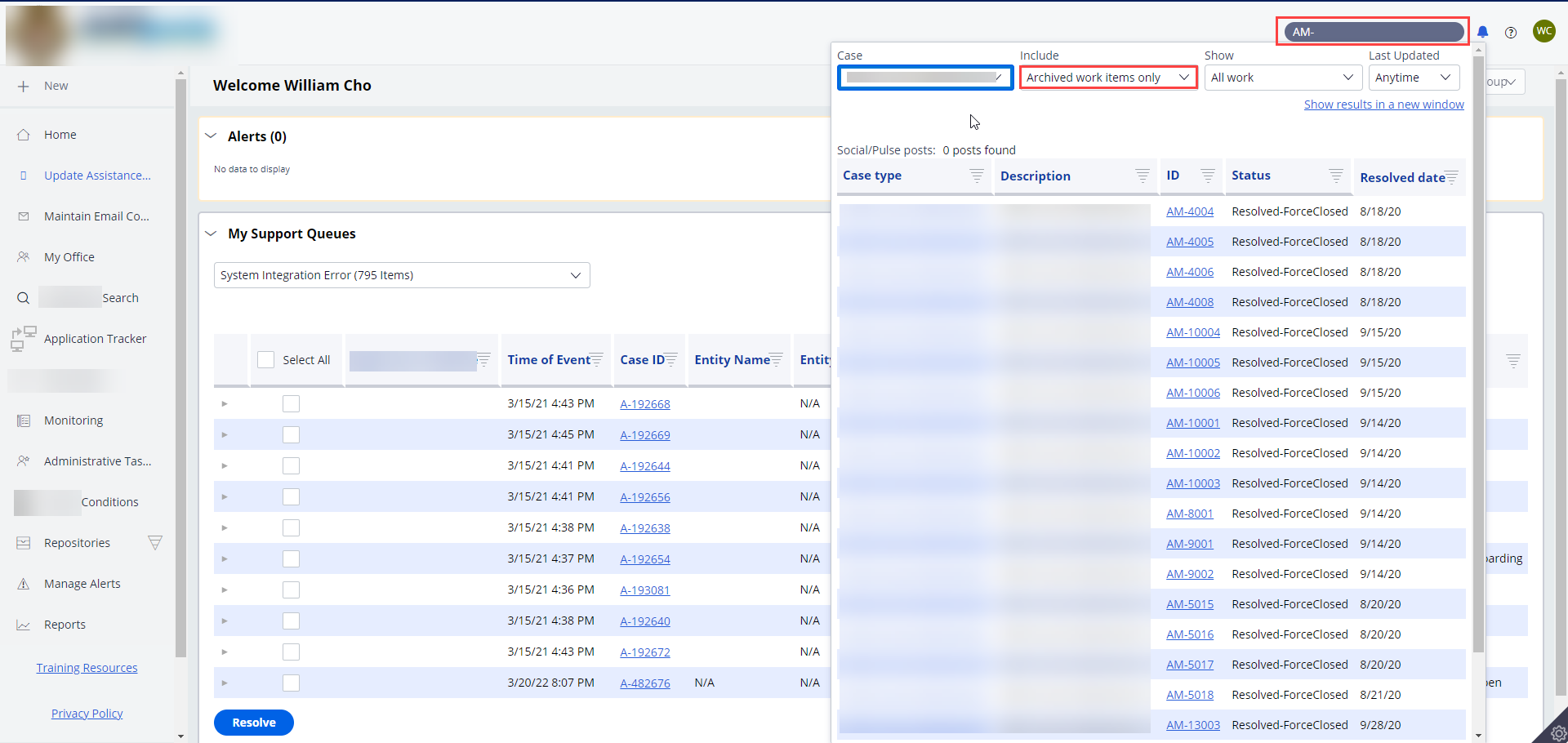
Validate 3 - Search the archived cases using the OOTB case search.
Select Archived work items only in the Include dropdown.
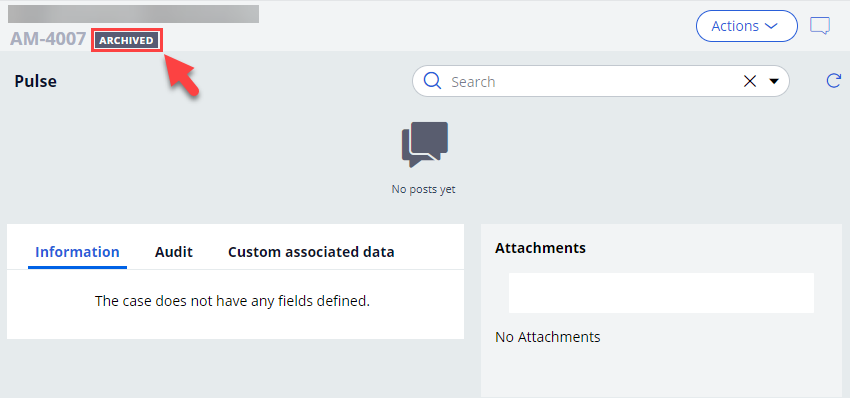
Open the archived case and verify the ARCHIVED status.
Validate 4 - Ask Pega Cloud administrator to verify that an archive sub-folder is created in the Pega Cloud File storage and contains the archived zip file.
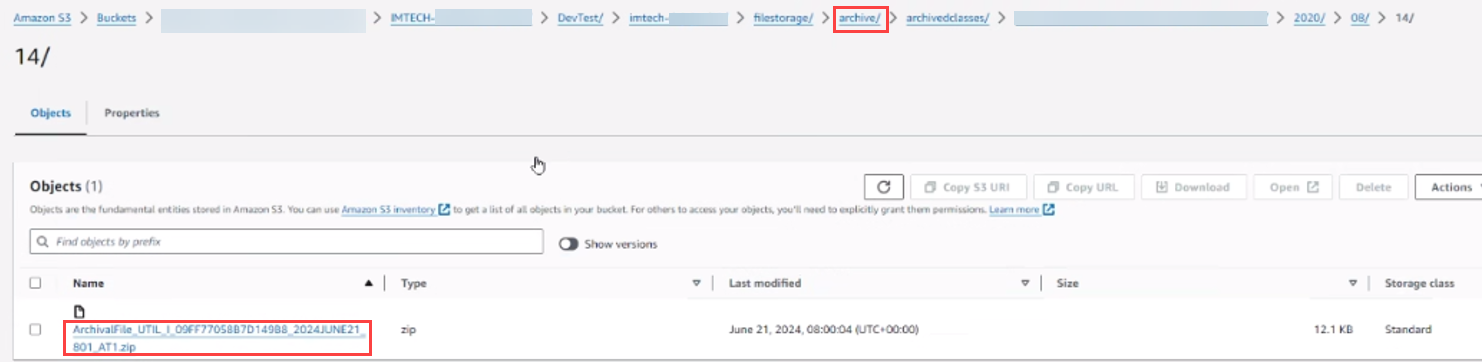
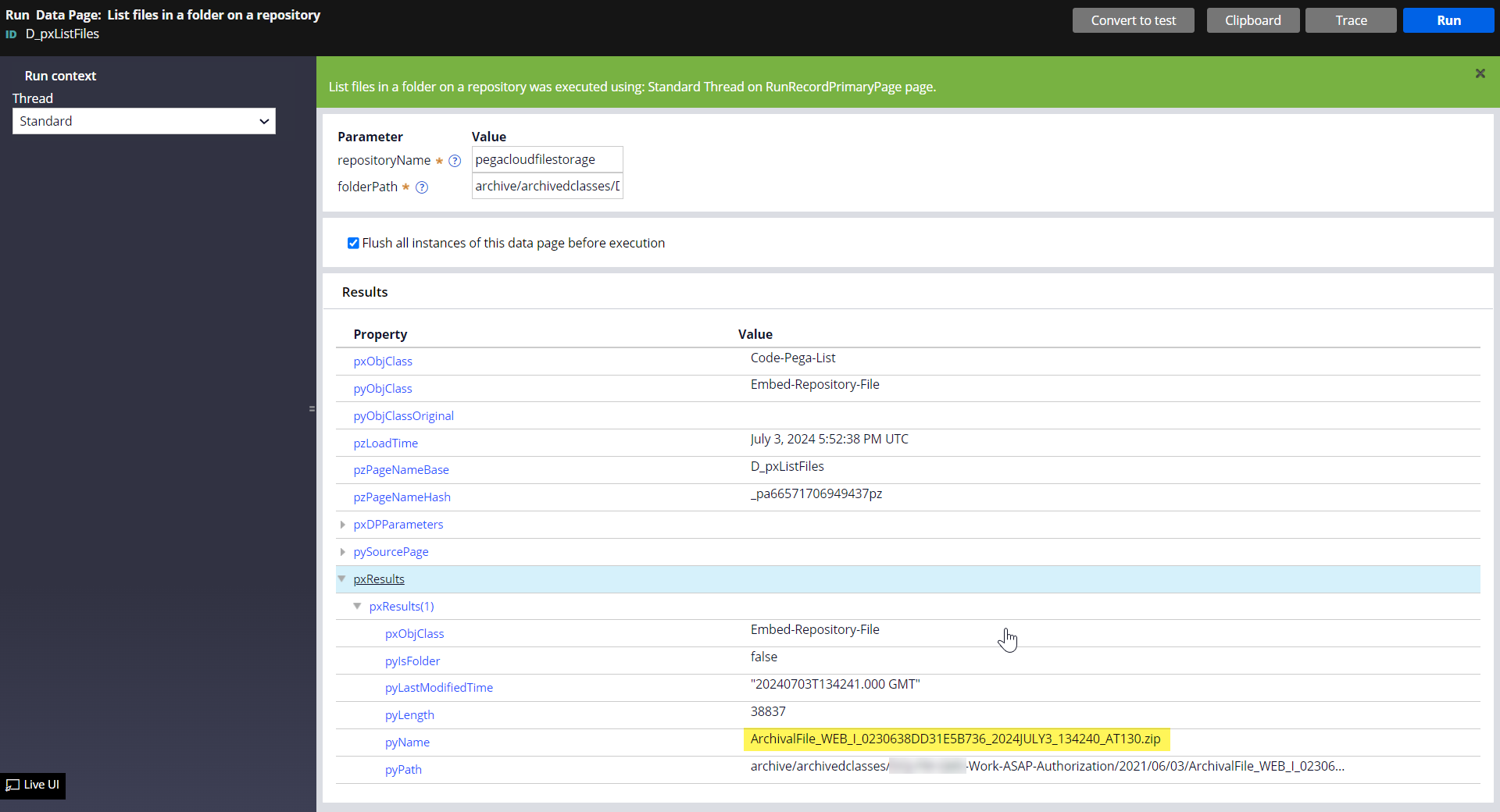
Alternatively, we can run a data page (D_pxListFiles) to verify that the archived zip file is successfully created in the file storage.
- E.g. parameters:
- repositoryName="pegacloudfilestorage"
- folderPath="archive/archivedclasses/XXXXX-Work-ASAP-Authorization/2021/06/03/"
Archiving cases with custom resolution status
By default, Pega archives resolved cases with 'Resolved-*' status only. But sometimes, client may have resolved cases with a custom resolution status that is different from 'Resolved-*'. The OOTB behavior can be customized to archive cases with a different resolution status.
To accomplish this, save the following OOTB pyDefault data transform to your application ruleset and update the value of .pyFilterValue property.
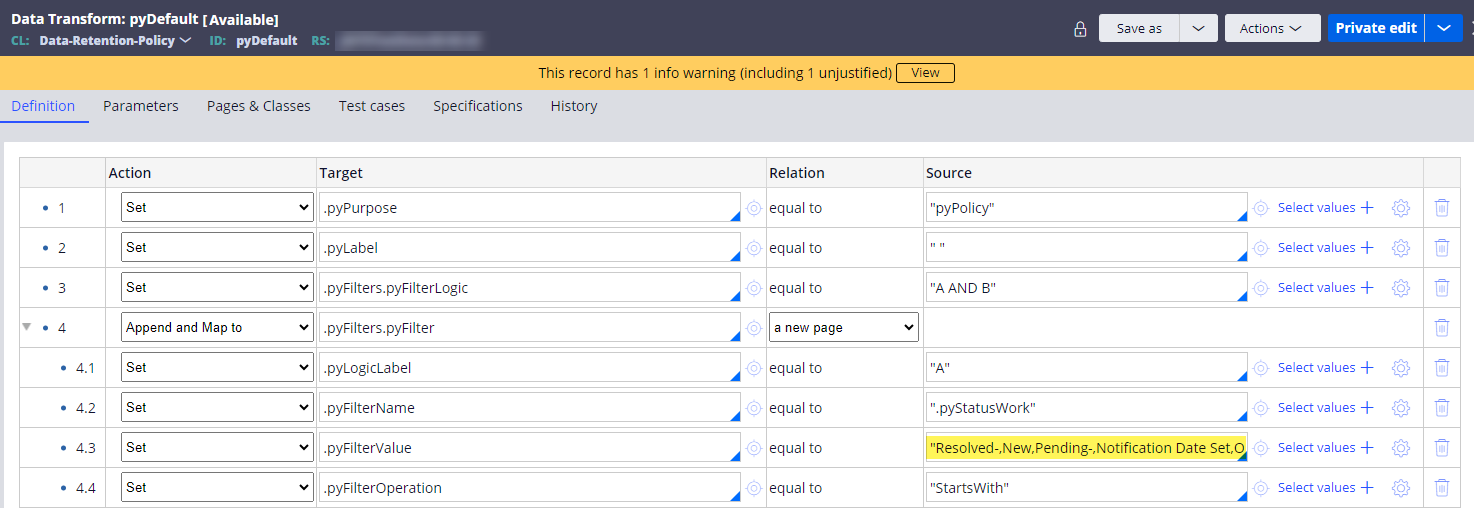
In our example, we set it to:
.pyFilterValue = "Resolved-,New,Pending-,Notification Date Set,Open"Caveat: to change the resolution status for a Case Type that already has an archival policy, we have to delete the existing Data-Retention-Policy records for the Case Type (after customizing the pyDefault data transform above) and then configure the archival policy again.
Note: make sure that the case still has a valid .pyResolvedTimestamp value.
Read more on Configurating custom resolution status.
Additional notes
- The archival process also archives certain artifacts within a case, such as child cases, work history, attachments, pulse replies including link attachments, declarative indexes, etc. Refer to this Pega docs article for more information.
- One challenge of archiving old cases in lower environments (such as DEV, QA and Stage) is that many old cases are left unresolved, which is not eligible for archival. Cases must be first resolved before being archived. To achieve this, we wrote an activity using pxForceCaseClose activity API to bulk close all unresolved cases older than a timestamp (passed as a parameter) with pyStatusWork=Resolved-ForceClosed. Then, in the next archival job, they would be archived.
- When bulk closing a very large number of cases, consider executing the pxForceCaseClose activity using Queue-For-Processing in the background processing nodes (instead of web nodes used by front-end users). This can help to distribute the processing overhead across multiple nodes to increase the throughput and also avoid the requestor locking for the user.
- When forcing to close an old case, the case may fail to resolve due to error. One reason could be that the old case is not processing correctly in the latest rules. In our project, one case threw this error and won't force resolve. For such, we'll need to resolve case by case before the next archival job can archive it.

- To read Pega docs on case archiving and purging - click here
Updated: 2 Jul 2024 8:59 EDT
Pegasystems Inc.
GB
Pegasystems Inc.
US
@SHAND Thanks for the question. For this project, we saved the OOTB job scheduler (pyPegaArchiverUsingPipeline) to our application ruleset (Implementation-level ruleset) and enabled it. Updated the documentation above as well.
Nationwide Building Society
GB
Very nice content, thanks!
If we are not using the new In Memory pipeline model then we have to save all 3 individual JS instead of pyPegaArchiverUsingPipeline.
- pyPegaArchiver
- pyPegaIndexer
- pyPegaPurger
Regards,
Guhan
Accenture plc
IT
@Will ChoHi and thanks for you support.
For client business requirements, we need to Archiving cases and its associated artifacts by using also the capability OOTB Pega Archival Excluded Cases.
We need to archive some of the work items with status Resolved* and not all work items with status Resolved*, so we need to exclude some of this by business logic.
Do you know how to use the additional functionality OOTB Pega Archival Excluded Cases?
Because we are try to use it but we have some issues.
We work with:
- Pega Platform 8.8.3
- Our application is Built on Theme-Cosmos version 02.01 application
Thanks for your time, Maurizio
Pegasystems Inc.
US
@ViscusiMaurizio we haven't had this requirement yet, but this document explains the exclusion process in the latest Pega 24.1 version - https://docs.pega.com/bundle/platform/page/platform/system-administration/case-archival-expunge-excluding.html
pzAddCaseExclusionFromArchival - When you place the hold on an unresolved or resolved case using this activity, you exclude the case from the pyPegaArchiver, pyPegaIndexer, and pyPegaPurger jobs which would otherwise archive the case data, purge it from the database, and copy it to an external repository.
pzReleaseCaseExclusionFromArchival - Releases a stand-alone case or case hierarchy from its exclusion status, and permits the case to run through the normal archiving, purging, and expunging process.
Accenture plc
IT
@Will Cho thanks for your quick response.
Yes we studied this document of exclusion process. We implemented our solution like explain in this document, using the activity pzAddCaseExclusionFromArchival to exclude the work item in the archiver process and pzReleaseCaseExclusionFromArchival to add work item in the archiver process, but we have some issues because some cases excluded by pzAddCaseExclusionFromArchival are archived also if excluded.
Thanks for your support.
Maurizio
Updated: 16 Jul 2024 10:39 EDT
Pegasystems Inc.
US
@ViscusiMaurizio Thanks for the finding. I would suggest to raise an incident ticket with Pega Support to verify the behavior of pzAddCaseExclusionFromArchival activity.
Nationwide Building Society
GB
When opening the child archived case, it doesnt populate the parent archived case in pyWorkCover page by default.
The OOTB activity used to open any archived case (Parent or Child) is pzOpenArchivedWorkObject. This doesnt have any logic to populate pyWorkCover and this is Final rule which can not be modified.
Is this the expected behaviour?
Thanks!
Guhan
Pegasystems Inc.
US
@GuhanathanV4521 That is the behavior i'm also seeing. I don't see pyWorkCover after opening a child archived item.
pxCoverInsKey is still there to identify the parent ins key.
Pegasystems Inc.
US
@GuhanathanV4521 What is the Pega ruleset name where pzOpenArchivedWorkObject is saved?
Tata Consultancy Services
GB
Hi @Will Cho,
can you also suggest the options we have to handle the data retention when we have multiple applications hosted on the same environment and having individually different time frames needing different schedule of jobs.
Thanks
Pegasystems Inc.
US
@Pragadeesh Archiving policies are defined in each case type and pyPegaArchiverUsingPipeline job scheduler will run at a specified time to archive them. If you are asking to set up multiple schedules of pyPegaArchiverUsingPipeline JS, we haven't done it. You may want to post the question to the Pega Community/Question page.
Nationwide Building Society
GB
@Will Cho We have implemented archiving on-Prem. We have created a File Repository in our background processing server as secondary storage. The challenge is the archived data is available in background processing server only and unable to access from WebUser node. We are planning to sync the data into WebUser nodes. Is there any better way to achieve this? How this logic works in Cloud?
Thank You!
Guhan
Pegasystems Inc.
US
@GuhanathanV4521 i don't have the insight into the Pega Cloud architecture unfortunately. I'd suggest to reach out to your Pega account manager and arrange a meeting with Pega Cloud team.
Capgemini
FR
@Will ChoHey !
We have a use case where we need to set a different retention period for every resolution status in the same case type. i.e ; if pyStatusWork == Resolved-Paid then rentention period is 30 days, if pyStatusWork = Resolved-Rejected then retention period is 10 days. Is this possible to achive through the pyDefault data transform ? thank you
Pegasystems Inc.
US
@AhmedAttiawe haven't come across such ability to set different retention period per status in the current platform version we are using 23.1.3. What we know to date is that we can set a retention period per case type.
Evonsys
US
@Will Cho Configured Archival Policy for Case type available at workgroup(XXX-XXX-Work-Int) and it creates a retention policy for the same. JS(pyPegaArchiverUsingPipeline) does not pick up eligible instances available at classes ( call, web) extended from workgroup(XXX-XXX-Work-Int-Call,XXX-XXX-Work-Int-Web). we dont have casetype rule available at Call or web classes. Does each object need casetype rule at corresponding pxobjclass for archival purpose ?
Pegasystems Inc.
US
@RamVembu That is a good question. So far, i have tried to archive only work objects with case types defined. And in each case type, the archiving policy is defined. I've been also wondered if this OOTB archiving would work with any work/data objects that do not have case types defined. Have you manually tried to create Data-Retention-Policy.pyPolicy instances for the XXX-XXX-Work-Int-Call,XXX-XXX-Work-Int-Web classes and see if they would be archived by the pyPegaArchiverUsingPipeline job scheduler? I'm also curious about the result.
Evonsys
US
@Will Cho I created Casetype for each pxobjclass(XXX-XXX-Work-Int-Call,XXX-XXX-Work-Int-Web ) and created pyPolicy for Call & web respectively. Later deleted pyCasetype for Call & Web. pyPegaArchiverUsingPipeline (JS) picks up and archived eligible cases as defined in Policy. Based on results we are planning to create pycasetype for pxobjclass which was not available in system and move only policy instances to higher env. Let me know if any other better approach for implementation.
Regards,
Ramkumar Vembusekaran
US
@Will Cho I don’t see any timestamp-related parameters on pxForceCaseClose. Could you clarify which parameter you’re referring to for passing a timestamp, so cases only resolve after that time? Thanks
Pegasystems Inc.
US
@SairohithT17629295That's correct. pxForceCaseClose doesn't have a timestamp param. We use Obj-Browse to fetch all open/pending cases whose last commit timestamp (.pxCommitDateTime) to database is older than one year. Then loop through the results to open each case and set its .pyResolvedTimestamp property to the last commit timestamp so that they can be archived in the next job run (assuming the archive policy of the case type is older than 365 days).
US
Currently, we use pxRetrieveSearchData to get the list of archived cases, but this approach is limited to returning only up to 1,000 records. We need to know the total number of cases archived to date. Is there a rule or method to retrieve the exact archived count?
Additionally, we want to compare that archived count with the total number of cases in the work table for this environment—specifically, how many of those have been archived so far. Please suggest any reliable ways to obtain these counts and perform the comparison. Thanks
Pegasystems Inc.
US
@SairohithT17629295 That is an interesting question. I'm not aware of OOTB rule to retrieve the exact archived count. I normally export the latest case list (using a report definition) to Excel, and then after the archival, export another case list to Excel to compare using Excel features. Regarding pxRetrieveSearchData activity, Step 9 sets the max record. Perhaps you can private checkout the activity and modify .pyMaxRecords to >1000 and retry.
Updated: 14 Jan 2026 9:45 EST
Evonsys
IN
Looking for some clarity on a data archival scenario in Constellation (SI AAA Framework) and would appreciate your guidance.
-
We have two case types: DISP and ORCH in OOTB Frame Works
-
These case types are parallel and do not have a parent–child relationship
-
DISP creates ORCH, and there is a dependency between them
-
The requirement is that DISP should be archived only after the related ORCH case is resolved
From my understanding:
-
Pega handles archival dependency automatically only for parent–child case types
-
For parallel case types, business-condition–based retention options are available in the archival policy
-
However, I’m not clear how this approach is intended to handle archival dependency between parallel case types, since there is no built-in relationship like parent–child
I’m trying to understand what the expected or recommended approach is for this kind of scenario in Pega, especially within Constellation / SI AAA Framework.
Any clarification or guidance would be really helpful. Thanks!
Pegasystems Inc.
US
@GopalakrishnanIyyavu From my understanding, Pega OOTB archival mechanism enforces the archival dependency only when they have parent-child relationships. Parent case can be archived only when its child cases are resolved. Your scenario above may not be possible using the Pega OOTB archival job. If possible, consider parent-child relationship if this archival dependency is a must-have requirement.
Updated: 18 Feb 2026 16:03 EST
US
@Will Cho Is there any way to change a field value after a case has already been archived?
We have scenarios where updated information comes in after a case is resolved, and that information needs to be added later. Since the case is already archived at that point, I wanted to check whether it can still be updated.
My understanding is that archived cases cannot be updated directly. If that’s correct, what is the best approach for handling scenarios where new information must be added to an already archived case? Any suggestions or best practices you can share would be greatly appreciated. Thanks!
US
If we add a new column to the BIX extract and run a full load, BIX will include that field and send the data to the reporting database for all cases. But after a case is archived, BIX can no longer extract the archived data correct?
If that’s true, does it mean we should add all required columns to the BIX extract before archiving, so the reporting database already has all the information that might be needed for future reports?
Is that the right approach, or do you recommend another solution?
Updated: 20 Feb 2026 6:26 EST
Pegasystems Inc.
US
@SairohithT17629295 My understanding is that once a case is archived, BIX cannot extract it anymore because BIX extracts data from live Pega tables. In general, you should extract all required data before archiving them.
@Will Cho - To modify the JS settings, we need to Save As the OOTB Rule into an open Application RuleSet. This can mean either two things, the JS must be saved into a RuleSet common to every applications stack in your system so that archival works for every Application, or you can Save As per application and use the Access Group setting to set the "scope" of the Cases to include. Can you comment on these statements please?