Applies to Pega Platform™ versions 7.3 through 8.3.1
For information related to Pega Platform versions later than 8.3.1, see these prerequisite articles, Third-party externalized services FAQs and External Hazelcast in your deployment.
This document is one in the series that includes the following companion documents:
Managing clusters with Hazelcast (prerequisite)
Split-Brain Syndrome and cluster fracturing FAQs
To troubleshoot Hazelcast cluster issues, learn to recognize symptoms that are not related to cluster management. Then understand the basic informational system messages and the common error messages.
Differential root cause analysis
Common exceptions and error messages
Differential root cause analysis
Most Hazelcast errors are a symptom of another issue. Therefore, when troubleshooting an error on one node, you often have to look at another node's logs based on the IP address mentioned in the error.
Be aware of problems that, at the outset, might appear to be Hazelcast cluster management issues but are caused by something else.
Hazelcast Exceptions that are misleading
Cannot start nodes because Hazelcast fails. Whenever a node is restarted, Hazelcast fails. (Pega 7.2.1)
Reason: com.hazelcast.spi.exception.WrongTargetException: WrongTarget! Causes auto shutdown (Pega 7.2.1)
Nodes are cycling (not clustering) and randomly shutting down
Agent running but the activity is not picked up (Pega 7.2.2)
Search node not available on landing page (Pega 7.4)
Hazelcast cache reading exception: InvalidCacheConfigurationException in production logs for multiple users (Pega 7.3.1)
SOAP Connection for SMA Remote fails on JBoss: Failed to retrieve RMIServer stub: javax.naming.CommunicationException (Pega 7.1.8)
Hazelcast logs clog the server space at a rapid pace, triggering error every few milliseconds: com.hazelcast. core.OperationTimeoutException (Pega 7.2.2)
com.hazelcast.map.impl.query.QueryPartitionOperation clogging logs, blocking work (Pega 7.3.1)
System Pulse inconsistent across environments causing rule propagation issues (Pega 7.4.1 LA Release)
com.hazelcast.core.OperationTimeoutException: QueryPartitionOperation invocation failed to complete due to operation-heartbeat-timeout in logs (Pega 7.3.1)
queue: Pega-RulesEngine #4: System-Status-Nodes.pyUpdateActiveUserCount java.lang.OutOfMemoryError: Java heap space (Pega 7.3.1)
Hazelcast Exceptions that are misleading
For certain cases reported, the following Hazelcast Exceptions were determined to be rooted in other causes.
|
Hazelcast Exception |
Actual Root Cause |
Solution |
|---|---|---|
|
OperationTimeoutException Single node having issues communicating with the rest of the nodes in the cluster |
Blocked thread. Invoking PRRandom requires entropy to generate a random number. The entropy pool is empty; therefore, this thread is blocked waiting for more entropy to be generated. |
Increase the entropy pool |
|
OperationTimeoutException (Pega 7.4) |
One node had general connectivity issues communicating with some, but not all, nodes in the cluster. This caused widespread communication issues in the cluster. (Pega 7.4) |
Configuration issue resolved by specifying Tomcat Data Source to use JDBC connection pooling instead of DBCP Connection pooling
|
|
MemberCallableTaskOperation |
Blocked thread in the Stream service |
Resolved in Pega 8.1.4, 8.2, and 8.3 The introduction of distributed event logging used to facilitate data flow troubleshooting in Pega 8.1 created a negative impact on performance for extremely large clusters (greater than 15 DF nodes). To resolve this, the distributed logs have been removed and the system saves events in the database instead.
|
|
Hazelcast complains about lost connection (Pega 8.2) |
Deadlock in threads on startup |
Resolved in Pega 8.2.1 |
Cannot start nodes because Hazelcast fails. Whenever a node is restarted, Hazelcast fails. (Pega 7.2.1)
Reason: com.hazelcast.spi.exception.WrongTargetException: WrongTarget! Causes auto shutdown (Pega 7.2.1)
Actual root cause
Pega temp directory was misconfigured. All nodes were sharing the same directory.
Root cause analysis reveals two reasons for this problem:
- The Pega temp directory was accidentally removed from the configuration of the nodes. Therefore, the nodes defaulted to using the default directory. Consequently, the nodes shared the same temp directory. When this condition is detected, the system sends a message in the logs indicating that this is not allowed and automatically shuts down a node. This error is clearly displayed in the logs.
- The Pega temp directory issue described above was missed by system administrators when they reviewed the logs. Therefore, they assumed that the issue was a clustering issue.
Apparently, a variable string was used to set the temp directory. (This is one part of the generated Node ID.) Even though each node would have had a different temp directory defined for it, because the users used the same variable for every node, the generated Node IDs were the same.
Solution
Explicitly set the Node ID.
Perform the following local-change:
- Rolling restart resolves the split-brain cluster configuration.
- Remove the explicittempdir entry from the prconfig.xml file on all nodes. Although this entry is not being used, it is causing confusion about the explict temp directory being used.
- Add the JVM argument -Didentification.nodeid=<your_uniqueNODE_ID> and restart.
Nodes are cycling (not clustering) and randomly shutting down
Cycling is when nodes quickly join and leave a cluster.
Actual root cause
Root cause analysis reveals an inadequate number of IP addresses allocated on the subnet.
Too few IP addresses on the subnet were allocated to the Cloud systems. That is, the Classless Inter-Domain Routing (CIDR) range was too small. Therefore, after a few were restarted, the pool of IP addresses ran out, causing new nodes to fail. Once a full restart took place and the addresses were freed up, the nodes were able to obtain IP addresses and correctly formed a cluster. For example, when a node restarted, it temporarily reserved two IP addresses: the one it was using and the one it is going to use. There were only four (4) extra IP addresses. Subsequently, after the four nodes were restarted at the same time, no new IP addresses were available.
Solution
Cloud administrators increased the number of available IP addresses so that new nodes have an adequate number of IP addresses to choose from when starting.
Agent running but the activity is not picked up (Pega 7.2.2)
Actual root cause
Root cause analysis reveals that the Agent fails because its lock was left in the distributed map after failing its previous execution.
Solution
Perform the following local-change:
- Create a copy of the Agent with a different name to prevent it from being blocked by the stale lock and allow it to run successfully.
- Restart the entire cluster to clear all the locks.
Search node not available on landing page (Pega 7.4)
Actual root cause
Sporadically the Search node becomes unavailable and the Search landing page takes a long time to load. This normally happens after a restart of PegaAppTier node. It seems that the Search node on the Util tier falls out of the cluster when the AppTier is restarted. App tier nodes were restarted, but the Util tier was not restarted. The logs show Hazelcast exceptions.
After months of sporadic reports like this one, the issue was able to be reproduced and determined to be a search initialization issue. The root cause is that Elasticsearch was relying on the Hazelcast APIs to check on the search node during startup. However, in some cases, this was happening before Hazelcast initialized.
The problem can occur in on-premises and cloud environments when search nodes are left online while others are restarted.
Solution
For Pega 7.4, obtain and install HFix-50360.
For Pega 7.3.1, obtain and install HFix-51377.
For Pega 7.3, obtain and install HFix-50885.
Hazelcast cache reading exception: InvalidCacheConfigurationException in production logs for multiple users (Pega 7.3.1)
Actual root cause
A Hazelcast construct used for caching was intended to be created only once, but Pega code was creating it multiple times.
Solution
Apply HFIX-47879 for Pega 7.3.1 to correct the Pega-provided HazelcastCacheBuilder.
SOAP Connection for SMA Remote fails on JBoss: Failed to retrieve RMIServer stub: javax.naming.CommunicationException (Pega 7.1.8)
Actual root cause
A questions about Apache Struts led to discovery that SOAP is not a supported protocol for JBoss.
Solution
Apply Pega 7.1.8 HFix-47358, which provides Apache Struts 2.3.35 to address CVE-2018-11776 for System Management Application (SMA).
Hazelcast logs clog the server space at a rapid pace, triggering error every few milliseconds: com.hazelcast. core.OperationTimeoutException (Pega 7.2.2)
Actual root cause
A defect in Pegasystems’ code or rules
Solution
Apply HFix-47749 for Pega 7.2.2 to run with Hazelcast Enterprise Edition 3.10.4. The Pega 7.2.2 hotfix is the better alternative to the local change that required shutting down all nodes and restarting the application server.
com.hazelcast.map.impl.query.QueryPartitionOperation clogging logs, blocking work (Pega 7.3.1)
Actual root cause
A defect or configuration issue in the user’s operating environment whereby memory leaks in the application led to nodes running out of memory, which caused numerous Hazelcast exceptions.
Solution
Pega GCS addressed the memory issues to stop the Hazelcast exceptions and provided the an in-depth Hazelcast exception analysis of the logs.
System Pulse inconsistent across environments causing rule propagation issues (Pega 7.4.1 LA Release)
Actual root cause
EventQueue overloaded message reported primarily in Development environments caused by a rogue node with Hazelcast on it that was bringing down the cluster. The environment used Nessus for security and vulnerability scans. Usually nodes blacklist other nodes that are creating interference. For some reason, this did not happen, leading to the overload.
Solution
Pega 7.4.1 LA release provides a socket interceptor to kill socket connections to explicitly blacklisted IP addresses.
See Managing clusters with Hazelcast, the section Hazelcast interceptor.
com.hazelcast.core.OperationTimeoutException: QueryPartitionOperation invocation failed to complete due to operation-heartbeat-timeout in logs (Pega 7.3.1)
Actual root cause
A defect or configuration issue in the operating environment: The pyOnBeforeWindowClose activity cleans up requestors when a user closes the browser window instead of logging out. When the user closed the browser, the session state cannot be updated within Hazelcast because the Hazelcast threads are timing out. This can happen if there are nodes frequently joining and leaving the cluster. These timeouts are not causing any functional impact. There is another daemon running in the background to mark these closed sessions as disconnected.
Solution
Ignore the OperationTimeoutExceptions that sporadically occur from the pyOnbeforeWindowClose activity.
queue: Pega-RulesEngine #4: System-Status-Nodes.pyUpdateActiveUserCount java.lang.OutOfMemoryError: Java heap space (Pega 7.3.1)
Actual root cause
A defect was detected in Pegasystems’ code or rules.
The Out-of-Memory (OOM) error is caused by a problem with HTML-to-PDF generation, used in the Email Listener, which reads email messages and later converts the email messages to PDF.
Solution
- Apply HFix-45601 and the latest PD4ML JAR file.
- Create the following Dynamic System Setting (DSS):
Short Description: UseCompactStylesforPDF
Owning Ruleset Name: Pega-UIEngine
Setting Purpose : UseCompactStylesforPDF
Informational messages
Messages from Hazelcast that simply provide information require no action from you.
Hazelcast Enterprise expiration date
Hazelcast SSL is enabled
Signature
INFO - [*.*.*.*]:5701 [e83b4b98164ca63538dbf29ce9152e0b] [3.10] SSL is enabled
What it means
Encryption has been successfully enabled on this system
What to do
Nothing. Encryption started successfully.
Hazelcast Enterprise expiration date
Signature
INFO - [*.*.*.*]:5702 [31f3a859d53842b4f3f131c4a28631c1] [3.10] License{allowedNumberOfNodes=9999, expiryDate=05/14/2021, featureList=[ Security, Continuous Query Cache ], No Version Restriction}
What it means
This message provides the terms of the license such the number of allowed nodes, the expiry date, and feature list
What to do
This is only an informational message.
Common exceptions and error messages
During the normal operation of a cluster, you may see exceptions originating from Hazelcast from time to time. The list below identifies common exceptions and error messages, what they mean, and what to do when you see them.
Certain Nodes Cannot See One Another
Hazelcast Cache Not Exists Exception
Hazelcast Enterprise License Could Not Be Found
Hazelcast Instance Not Active Exception
Hazelcast Partition Lost Listener
Hazelcast Serialization Exception
Member Callable Task Operation
Member Left Exception
No Such Field Error: Config
Operation Timeout Exception
Operation Timeout Exception: RegistrationOperation invocation failed to complete due to operation-heartbeat-timeout
Retryable IO Exception
Target Not Member Exception
Wrong Target Exception
WARNING: Hazelcast member startup in Java 11 or later modular environment without proper access to required Java packages
Certain Nodes Cannot See One Another
In highly-available clustered environments, you might notice that certain nodes in your cluster cannot see one another. One node appears as if it is the one and only active node. The cluster management page does not show all the nodes in your Pega deployment. Upon inspection, you determine that some nodes are in a separate cluster. This error condition is sometimes referred to as Split-Brain Syndrome or cluster fracturing.
Read Split-Brain Syndrome and cluster fracturing FAQs to understand what causes Split-Brain Syndrome and what you can do to fix this error condition.
Hazelcast Cache Not Exists Exception
Signature
com.hazelcast.cache.CacheNotExistsException: Couldn't find cache config with name StaticContentAGCache.
Description
When checking the distributed map for a particular cache at startup, it was unable to be found.
What it means
A bug was identified by the Hazelcast support team and Pega subsequently issued a hotfix for it across Pega 7.3.1 and later releases of the Pega Platform.
What to do
If you are experiencing this issue, upgrade to the latest hotfix or Pega Platform Patch Release that is available.
Hazelcast Enterprise License Could Not Be Found
Signature
FATAL - [ Proprietary information hidden]:5701 [4b9f55b8e0dbffef8b3748de8d6c9993] [3.10] Hazelcast Enterprise license could not be found!
Description
The Hazelcast license could not be found.
What it means
When the Hazelcast license was requested, it could not be found.
What to do
If this error occurs at the time that a node shuts down, ignore it. The Hazelcast cluster might not have access to the license after shutdown.
If this error occurs in another context (such as at startup), contact GCS immediately.
Hazelcast Instance Not Active Exception
Signature
com.hazelcast.core.HazelcastInstanceNotActiveException: State: SHUT_DOWN Operation: class com.hazelcast.map.impl.query.QueryPartitionOperation
Description
This occurs when a Hazelcast member does not shut down gracefully. Because the QueryPartitionOperation proxy is bound to the Hazelcast instance, any operations on the queue will throw a HazelcastNotActiveException if the instance was killed.
What it means
The Hazelcast instance has been shut down, most likely ungracefully, and Hazelcast operations on this instance can no longer be processed.
What to do
Assuming the node was ungracefully terminated but was done purposely, this message can be ignored. (This should be the root cause in most cases.) If not, Hazelcast crashed for an unknown reason. Examine the logs to find the root cause of the failure.
Hazelcast Partition Lost Listener
Signature
(HazelcastPartitionLostListener) WARN - Node [ Proprietary information hidden]:5701 indicated that partition 189 was lost. The lost backup count is 0.
Description
Partition data from a node was lost, most likely the result of a node shutting down ungracefully.
What it means
A node was shut down ungracefully and Hazelcast did not have the time needed to migrate the distributed data it owned to other nodes. In nearly all cases, this message is benign because all distributed maps have multiple backup copies stored across the cluster. If this message is displayed, a backup copy is nominated as the new owner, new backup copies are established, and the cluster repartitions the data to once again prevent data loss from occurring. Both the node that shut down ungracefully and the partition that was lost are identified in the message. The last piece of information provided is the count. The count is equivalent to how many backups were lost. A count of 0 means that the owning node lost the data. A count of 1 means that the owning node and a backup were lost. A count of 2 means that the owner and two backups were lost and so on. All maps have at least two backups, and some maps are replicated on all nodes. How the data is distributed between the nodes is not known; therefore, there is no definitive way to check what data was held onto by what node.
What to do
Nothing. This message only indicates the possibility that data was lost as the result of a node leaving before the cluster could migrate the data. The only time this message is actionable is if multiple nodes have crashed or have been shut down ungracefully. The higher the number of nodes that are taken out of the cluster, the higher the likelihood that all the copies of a partition have been lost, this time, resulting in data loss.
Hazelcast Serialization Exception
Signature
DMAP [default#com.pega.platform.executor.jobscheduler.scheduler.JobRunTime] Operation [put(aKey,aValue)] failed on key [PZPURGEPRSYSSTATUSNODES:PEGA_WEB.1.19CW] com.hazelcast.nio.serialization.HazelcastSerializationException: java.lang.SecurityException: Resolving class com.pega.platform.executor.jobscheduler.scheduler.internal.JobRuntimeInfoImpl is not allowed.
Description
When attempting to deserialize <class>, the operation was not allowed.
What it means
For the protection of your clustered environments, Pega implemented Hazelcast Untrusted Deserialization Protection. This prevents malicious packets from being injected and deserialized by Hazelcast. If the class is trusted, it has not yet been added to the trusted whitelist.
What to do
This error should only occur in development environments. If this error occurs and the class can be trusted, add the class to the class or package whitelist contained within ClusterInfo.java. If you need to modify the whitelist, contact GCS.
Member Callable Task Operation
Signature
java.util.concurrent.TimeoutException: MemberCallableTaskOperation failed to complete within 30 SECONDS
Description
This occurs when a node does not receive a response in time from a remote operation.
What it means
A failed operation is usually the result of an ungracefully shut down node, a failed node, or a hung node. The MemberCallableTaskOperation usually has an identified target node (see the OperationTimeoutException examples) that should be investigated for root causes. In one case, the target node failed due to a lack of IP addresses available at startup.
What to do
Get the information of the target node from the log message and check that node for root causes.
Member Left Exception
Signature
com.hazelcast.core.MemberLeftException Member [ Proprietary information hidden]:5701 - f84f23ef-f436-4dfa-8383-85b4e38f5794 has left cluster!
Description
A member has left the cluster.
What it means
The member noted in the message has left the cluster in an ungraceful way.
What to do
If the member was explicitly removed, ignore this message. If this message was unexpected, inspect the logs for the node in question to understand why the member left. Then take whatever action might be needed.
No Such Field Error: Config
Signature
Caused by: java.lang.NoSuchFieldError: config
at com.hazelcast.instance.EnterpriseNodeExtension.beforeStart(EnterpriseNodeExtension.java:150) ~[hazelcast-enterprise-3.10_1.jar:3.8]
at com.hazelcast.instance.Node.<init>(Node.java:199) ~[hazelcast-3.8_1.jar:3.8]
Description
The field of the given Hazelcast class could not be found, indicating a class loading problem.
What it means
Both Hazelcast 3.8 and 3.10 have been loaded by the system and the byte code is conflicting between the versions.
What to do
In this case, the older Hazelcast JAR files (3.8) should have been removed from the system before Hazelcast 3.10 was added.
To resolve the issue, run the following query on the database in question and restart the node:
(Only Hazelcast 3.10 code is loaded.)
delete from rules.pr_engineclasses where pzjar like '%hazelcast%3%8%' or pzclass like '%hazelcast%3%8%';
Operation Timeout Exception
Signature
com.hazelcast.core.OperationTimeoutException …(long list of descriptors)
Description
An operation to the Hazelcast cluster has timed out.
What it means
Operations sent to the cluster are expected to be serviced in a reasonable amount of time, usually two minutes by default. When not serviced in time, the operation timeout exception is thrown with many other details. Details of interest are shown below with example data provided:
QueryPartitionOperation invocation failed to complete due to operation-heartbeat-timeout.
Current time: 2018-10-30 12:24:39.531.
Start time: 2018-10-30 12:22:18.002.
Total elapsed time: 141529 ms.
Last operation heartbeat: never.
Last operation heartbeat from member: 2018-10-30 12:24:32.581.
Invocation{op=com.hazelcast.map.impl.query.QueryPartitionOperation{
invocationTime=1540927358578 (2018-10-30 12:22:38.578),
name=com.pega.pegarules.cluster.internal.presence.PresenceAttributesHazelcastHeadNode
},
target=[ Proprietary information hidden]:5706,
connection=Connection[id=179, / Proprietary information hidden:5712->/ Proprietary information hidden:37609, endpoint=[ Proprietary information hidden]:5706, alive=false, type=MEMBER]}
Important details include the connection (IP address), target or endpoint (who was being communicating with), invocation name (what was being performed), start, current, or elapsed time and the last operation heartbeat (time period of interest). By analyzing these pieces of information, you can know where to look next, for example, the node’s log being communicated with, the time period). Then you can home in on the root cause. You will need to perform further analysis to understand why the operation timed out.
What to do
Gather the information from the OperationTimeoutException as noted above and further analyze the points of interest from that information. Continue performing analysis as required to find the root cause. You might need to examine multiple OTEs to get a full picture of what happened in time across the cluster. Pega’s analysis consists of finding a root cause and then getting a second and third piece of evidence to confirm or reject the hypothesis. For example, if an OTE seems to have been caused by one node, other nodes in the cluster should also report the same error.
Operation Timeout Exception: RegistrationOperation invocation failed to complete due to operation-heartbeat-timeout
The following scenario was reported as a Comment to Managing clusters with Hazelcast by Suman Gumudavelly on 25July2023.
This problem was first observed with Pega Platform™ versions 7.1.9 through 7.3.1. With a Hazelcast version upgrade to Hazelcast EE in Pega Platform version 7.4 and after backporting the Hazelcast EE hotfixes for Pega Platform version 7.3.1, the problem was temporarily resolved. But each time peak load was reached or application usage increased, the problem returned until the uLimit values were increased.
On Pega Platform version 8.6.4, after applying all hotfixes, gracefully shutting down all nodes, and verifying that the Nodes Status table is accurate, you see the following exception first in AES and then in PDC:
Caused by: com.hazelcast.core.OperationTimeoutException: RegistrationOperation invocation failed to complete due to operation-heartbeat-timeout
To resolve this problem, update the uLimit values in your WebSphere Application Server environment:
pending signals -1 192099 max locked memory (kbytes, -1) 64 max memory size (kbytes, -m) unlimited open files (-n) 100000 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes <-u) 192099 virtual memory (kbytes, -v) unlimited file locks <-x) unlimited
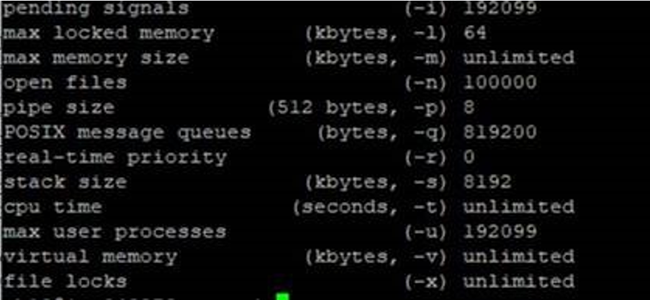
For more information, see ulimit()--Get and set process limits and Guidelines for setting ulimits (WebSphere Application Server).
Retryable IO Exception
Signature
com.hazelcast.spi.exception.RetryableIOException Packet not sent to -> Address[ Proprietary information hidden]:5701
Description
Hazelcast retryable input/output failed to complete.
What it means
Internally to Hazelcast, there is locking in place for input and output transactions. When partitions are migrating or lost and the unlock operation fails, transactions might fail, leading to a retryable IO exception.
What to do
This error should not normally occur. If it does occur, the error suggests partitioning issues, which primarily occur when the cluster is fractured and in a Split-Brain state. If this issue occurs, investigate the cluster for root causes of a Split-Brain state. See Split-Brain Syndrome and cluster fracturing FAQs.
Target Not Member Exception
Signature
com.hazelcast.spi.exception.TargetNotMemberException Not Member! target:Address[ Proprietary information hidden]5701, partitionId: -1, operation: com.hazelcast.map.operation.QueryOperation
Description
An operation was attempted against a member that was not actually a member of the cluster.
What it means
This node attempted to perform an operation against a node that was no longer in the cluster. This occurs when a node leaves the cluster just prior to an operation taking place. This typically occurs when a remote node is shut down. It also frequently occurs when the cluster has fractured into a Split-Brain state.
What to do
If this issue occurs once, the likely cause is that a node left the cluster as an operation was taking place. If the issue occurs frequently, the cluster might be fractured and in a Split-Brain state. Further analysis is required in this case because the cluster is in a bad state. See Split-Brain Syndrome and cluster fracturing FAQs.
Wrong Target Exception
Signature
com.hazelcast.spi.exception.WrongTargetException: WrongTarget! this: [ Proprietary information hidden]:5702, target: null
Description
When the target is null, this message means that the specified member does not have the owner set for a specific partition. As a result, the member did not get its partition table updated in time; that is, a request was made before the system was informed where the data lives in the grid.
What it means
In a healthy cluster, this error should rarely occur because Hazelcast has delivered a fix in past releases that prevents the race condition between looking for data and getting the updated partition table information. In a Split-Brain situation, when the cluster is fractured into many smaller clusters, partitions are lost because some partitions might only have existed on nodes that are no longer part of a splintered group of nodes. Also, frequent fracturing and merging causes the partition tables to experience delayed updates.
What to do
In a healthy cluster when this error occurs one time, ignore it. If you see the error multiple times, it might indicate that the cluster is experiencing fracturing. In this case, examine the logs to find the root cause of the fractured cluster. See Split-Brain Syndrome and cluster fracturing FAQs.
WARNING: Hazelcast member startup in Java 11 or later modular environment without proper access to required Java packages
Description
When Hazelcast is started in a Java modular environment, Java 11 or later versions, you see the following warning in the PegaCLUSTER.log file during Hazelcast member or client startup:
WARNING: Hazelcast is starting in a Java modular environment (Java 11 and later) but without proper access to required Java packages. Use additional Java arguments to provide Hazelcast access to Java internal API. The internal API access is used to get the best performance results.
What to do
To overcome this warning, take the following actions:
- When Hazelcast is started in embedded mode, pass the JVM arguments shown below to the Pega servers.
- When Hazelcast is started in client-server mode, pass the JVM arguments shown below to both the Pega servers and the Hazelcast servers.
--add-modules java.se --add-exports java.base/jdk.internal.ref=ALL-UNNAMED --add-opens java.base/java.lang=ALL-UNNAMED --add-opens java.base/java.nio=ALL-UNNAMED --add-opens java.base/sun.nio.ch=ALL-UNNAMED --add-opens java.management/sun.management=ALL-UNNAMED --add-opens jdk.management/com.ibm.lang.management.internal=ALL-UNNAMED --add-opens jdk.management/com.sun.management.internal=ALL-UNNAMED
For more information, refer to Hazelcast IMDG, Getting Started, Running in Modular Java.
See also the Pega Platform Support Guide.
Related content
Enabling encrypted communications between nodes
Deploying Hazelcast Management Center
Managing Hazelcast client-server mode for Pega Platform
Configuring client-server mode for Hazelcast on Pega Platform