Question
ANZ
AU
Last activity: 22 May 2018 14:30 EDT
Get Adaptive model responses
Pega 7.2.1 decisioning has a limitation that it will update all the adaptive model with the same context even if the Adaptive model is not referred in a Strategy. To overcome this issue we have included a new model identifier.
We have models already learnt in production and we need to copy that data to the new model with new model context. Pega has a wizard to train the model by uploading existing customer data in CSV format(https://community.pega.com/products/platform-adm-uploading-responses-tsk.htm). Is there a way to download the existing adaptive model responses from Pega.
***Edited by Moderator Marissa to update SR Details***
Accenture
AU
You can get the responses from the following table:
Data-Decision-ADM-ModelSnapshot and Data-Decision-ADM-PredictiveBinningSnapshot.
Pegasystems Inc.
NL
I need to correct the above statement. Responses are NOT stored in those tables. These two ADM Datamart tables contain snapshots with aggregate information about the models. These two tables drive the ADM Monitoring graphs. They contain counts like the total number of positives/negatives per model (and over time), but not the individual responses.
Pega does not store the individual responses explicitly. This is by design, and is also the reason why Adaptive models use an (adaptation of) Naive Bayes as the classifier algorithm.
Accenture
AU
Thanks Otto for your response. In that case where does Pega have the individual responses. In my mind , even for generating the classifiers based on the Naive Bayes algorithm you need the data.
Also how do these tables get generated. I know internally Pega runs two data sets in those two classes. Correct my understanding.
Pegasystems Inc.
NL
Indeed, if you change model identifiers, you effectively get new - empty - models. You are also correct that this "subset learning" can be confusing, which is why this has been deprecated in later releases. Is upgrade an option?
One other possibility I can think of is to create the new models, put them in the execution path of the strategies so they start learning, but keep the old ones for a while. Keep using the old ones until the new ones have gained enough evidence, then drop the old ones. Would that be an option for you?
ANZ
AU
This might work for us. But our worry is the combined learning from the beginning and replacing it recent learning makes much difference.
Accenture
AU
Hi Otto,
What we have done here, is we have modified the values of Channel model context to some other value. Let's consider previously for all the skill areas we set as "Call Center", however, now it has modified to "Call Center - Skill Area", and if there are multiple skill areas, different Channel values will be considered when models are getting created.
Also could you please elaborate on "Subset Learning"?
On your second point , we have thought about it . Quick question, can we champion challenge so that new model starts learning but the recommendation from old model prioritizes the outcomes based on learning lets say 80% of times.
Would be very happy to hear your expert advice here.
Pegasystems Inc.
NL
Hi NabenduP,
If you want to keep using the old models until enough responses have been collected by the new model you can use the 'Evidence' returned by the model. You can use a Join component that returns properties for propensity and evidence for both the old and the model. If the evidence of the new model > 1000 then the new propensity would be used, this can be done in a following Set Property. [note: this doesn't work with a Switch component]
But please beware that the old model still needs the 'old' values for channel (before modification) as input when executed, whereas the new model uses the new modified values. You can arrange this in your strategy. Let me know if you need any help, we can always plan a call,
Regards,
Ivar Siccama - Product Manager Predictive Analytics
P.S. In a Strategy, open the adaptive model component, go to the Output mapping tab to make sure the component returns the evidence
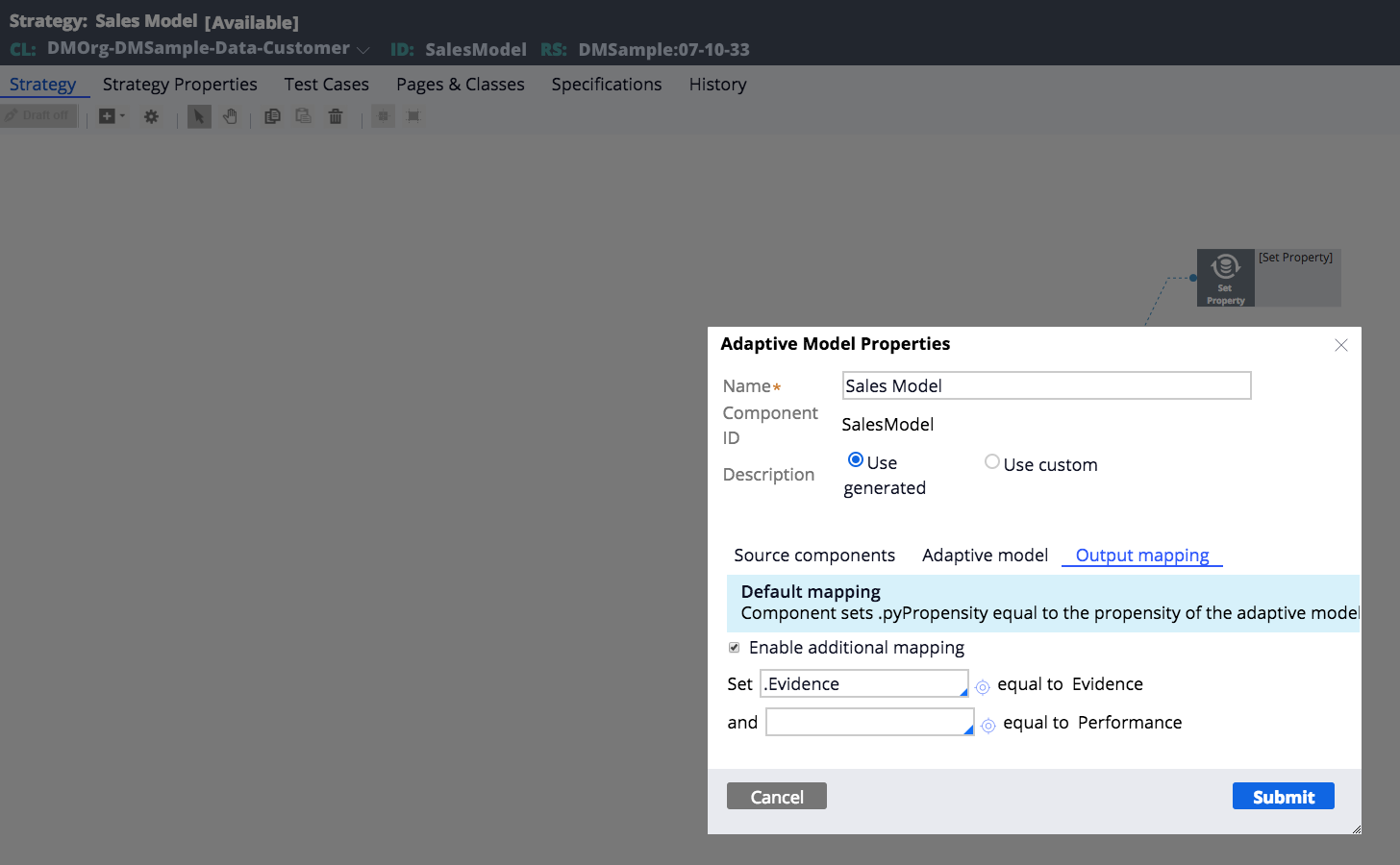
Hi NabenduP,
If you want to keep using the old models until enough responses have been collected by the new model you can use the 'Evidence' returned by the model. You can use a Join component that returns properties for propensity and evidence for both the old and the model. If the evidence of the new model > 1000 then the new propensity would be used, this can be done in a following Set Property. [note: this doesn't work with a Switch component]
But please beware that the old model still needs the 'old' values for channel (before modification) as input when executed, whereas the new model uses the new modified values. You can arrange this in your strategy. Let me know if you need any help, we can always plan a call,
Regards,
Ivar Siccama - Product Manager Predictive Analytics
P.S. In a Strategy, open the adaptive model component, go to the Output mapping tab to make sure the component returns the evidence
Accenture
AU
Thanks for the response Ivar, We can try the Evidence thing in our Adaptive Model. However, in terms of using the Old Adaptive Model, it seems to be tricky use the existing Channel value as there only we are changing the values so that new model learns differently based on the skill area.
As an example , current models have learnt as CallCenter as Channel irrespective of skill area in different Adaptive Models. However it seems and as Pega Product team has confirmed that all models will tend to learn as long as the context is same even if they are executed in different strategy contexts in Pega Marketing 7.2.1 but that seems to be resolved in 7.3. However we don't know whether Customer is ready to move to 7.3.
As a result , we have introduced new channel values such as CallCenter-SKillArea so that in different skill areas it learns differently. In that respect, we have observed there is only one place where we can modify the Channel values namely pyDefault of PegaOMF-ON-Data-InteractionDetails. Hence, I am not sure how to still feed the existing Channel values. We are happy to have a call if that is easy to explain and understand. let me know.
Accenture
IN
Please try below, test with good amount of data before putting in production
- Create/use new adaptive model with low memory settings (quick learner) with same predictors as existing adaptive model, only keep the “memory responsiveness” as low value and “run data analysis after” value to low
- Use both old (slow learner) and new (quick learner) adaptive models in the strategy, all proposition will go to both the models.
- Join the output of the both models output using a Group By aggregation component with selected remaining properties as highest by model performance. Group by will by Propositin name or pxidentifier of the proposition
- Then apply Pega suggested standard smoothing propensity calculation (mentioned below)
- Then prioritize based on smoothing propensity as suggested offers.
This will balance the impact of newly introduces offer/proposition.
[suggested propensity smoothing calculation:
(@divide(.StartingEvidence, (.StartingEvidence + .ModelEvidence+1.0),3) * .StartingPropensity) +
(@divide(.ModelEvidence, (.StartingEvidence + .ModelEvidence+1.0), 3)*.pyPropensity)
]
Pegasystems Inc.
NL
@ShankaC Alternatively you could also use a Switch component (instead of the Group By Aggregation component) in the fast/slow learn use case you describe. You would then switch on a condition of highest performance. I would also take into account the evidence as the performance (AUC) may still have a large error when the evidence is low.
But for the original question I would recommend just switching on evidence as you want to move to the new model.