Archiving and expunging Case data
We are trying to Archive and expunge our app's Case data using In-memory pipeline by configuring all required settings. We enabled the job and we saw the case data were archived to secondary storage and then purged. Then we try to retrieve archived cases by searching the portal using Archived work items only option, pega is bringing the case using pyReviewArchivedCase harness showing some of the details. Question from our business is there a way to bring in the exact case data(like import done with legacy Purge/Archive Wizard)? Or Pega only brings in the exposed case property that were indexed during the Archival process? Can someone please provide more information on how can we restore the exact case data for archived ones?
Pegasystems Inc.
GB
@Jey2705 ⚠ This is a GenAI-powered tool. All generated answers require validation against the provided references.
Below we can provide some insights on the differences between the current archiving system and the legacy Purge/Archive Wizard.
In the current Pega case archiving system using the In-memory pipeline, when cases are archived to secondary storage and then retrieved using the "Archived work items only" option with the pyReviewArchivedCase harness, the system primarily restores only the indexed properties rather than the complete case data. This is different from the legacy Purge/Archive Wizard, which had more comprehensive data restoration capabilities.
The current archiving process preserves essential case data such as the case's resolution status and associated artifacts that were specifically configured for archiving. However, unlike the legacy Wizard's import functionality, the current system does not have a built-in method to restore the complete case data with all properties.
When cases are archived using the current system:
@Jey2705 ⚠ This is a GenAI-powered tool. All generated answers require validation against the provided references.
Below we can provide some insights on the differences between the current archiving system and the legacy Purge/Archive Wizard.
In the current Pega case archiving system using the In-memory pipeline, when cases are archived to secondary storage and then retrieved using the "Archived work items only" option with the pyReviewArchivedCase harness, the system primarily restores only the indexed properties rather than the complete case data. This is different from the legacy Purge/Archive Wizard, which had more comprehensive data restoration capabilities.
The current archiving process preserves essential case data such as the case's resolution status and associated artifacts that were specifically configured for archiving. However, unlike the legacy Wizard's import functionality, the current system does not have a built-in method to restore the complete case data with all properties.
When cases are archived using the current system:
- Only properties that were indexed during the archival process are readily available when retrieving the case
- The pyReviewArchivedCase harness shows a limited view of the case details
- The complete case data with all properties is not fully restorable in the same way as with the legacy Purge/Archive Wizard
For your specific business requirement of restoring exact case data, you have a few options:
- Ensure that all critical case properties are properly indexed before archiving to make them available during retrieval
- Consider implementing a custom solution that captures and stores additional case data before archiving if complete restoration is essential
- Review your archiving strategy to potentially keep cases in the primary database longer if full access to all properties is frequently needed
If you need to restore complete case data with all properties similar to the legacy Wizard's functionality, you might need to work with Pega Consulting to explore custom solutions or alternative approaches specific to your implementation.
References:
- Archiving and expunging Case data
- The Case archiving and data expunging processes
- Retrieving archived Case data
CSC
US
Thanks @MarijeSchillern for your response. When you say "Ensure that all critical case properties are properly indexed before archiving to make them available during retrieval" , you mean to update the "Custom Search Properties" rule instance? But when i opened the case using the "Archived work items only" option with the pyReviewArchivedCase harness, I see the pyWorkPage holding all data but then pyCaseInformation is not showing details like non-Archived case because of some when rule on our layer blocking it. So still trying to understand what is indexed as you said "critical case properties"?
Also D_pzArchivedCaseAttachments is not pulling Data-WorkAttach-File details which we need to show some details in pyArchivedCaseAttachments. Is there a way to pull that?
Pegasystems Inc.
GB
@RameshSangili would this, by any chance, be something you could help with?
Updated: 10 Apr 2025 4:10 EDT
Pegasystems Inc.
CA
Please find my inline comments,
Question from our business Is there a way to bring in the exact case data(like import done with legacy Purge/Archive Wizard)?
No, there is no option to import.
Pega only brings in the exposed case property that were indexed during the Archival process?
That's correct. It's important to optimize the relevant search properties before the Archival process.
During archiving, only exposed properties are indexed by default. To search archived Cases by embedded page-list properties, you must first enable each embedded page-list property for indexing.Please refer to the documentation below.
Can someone please provide more information on how can we restore the exact case data for archived ones?
I hope not. @MarijeSchillern -
@Chetan.Chaudhari is there are ways to restore for the archived one?
CSC
US
Thanks @RameshSangili. That helps to understand how Search works for Archived cases. Trying to understand how the case details are rendered in pyReviewArchivedCase harness. I see 4 columns in the csv file in archived zip file. Does pzPVStream holds the actual blob reference that pulls the pyWorkPage information from the elastic indices? Can you please shed some light on that part.
Also D_pzArchivedCaseAttachments is not pulling Data-WorkAttach-File details which we need to show some details in pyArchivedCaseAttachments. Is there a way to pull that?
| pzInsKey |
| pxObjClass |
| parentInsKey |
| pzPVStream |
| ConcatenatedColumn |
Updated: 10 Apr 2025 5:01 EDT
Pegasystems Inc.
GB
Regarding your specific questions:
- pzPVStream and pyWorkPage information: pzPVStream contains serialized blob data that references the pyWorkPage information stored in the elastic indices. The four columns you see in the CSV file (pzInsKey, pxObjClass, parentInsKey, pzPVStream, ConcatenatedColumn) seem to be the structure used to store and retrieve this information but are not relevant for the archiving process.
- D_pzArchivedCaseAttachments and Data-WorkAttach-File details: For retrieving attachment details in pyArchivedCaseAttachments, you might need to implement a custom solution. The standard D_pzArchivedCaseAttachments is not be pulling the Data-WorkAttach-File details you need.
The section Archived data in our main documentation The Case archiving and data expunging processes explains the product's priorities:
- Simpler implementation
- Higher performance
- Improved resiliency
- Maximum performance out of the box
After the system completes the archiving job, you can still search and review Cases in the secondary repository, but the data is deleted from your primary Pega database. The following diagram illustrates the Case archiving process:
Regarding your specific questions:
- pzPVStream and pyWorkPage information: pzPVStream contains serialized blob data that references the pyWorkPage information stored in the elastic indices. The four columns you see in the CSV file (pzInsKey, pxObjClass, parentInsKey, pzPVStream, ConcatenatedColumn) seem to be the structure used to store and retrieve this information but are not relevant for the archiving process.
- D_pzArchivedCaseAttachments and Data-WorkAttach-File details: For retrieving attachment details in pyArchivedCaseAttachments, you might need to implement a custom solution. The standard D_pzArchivedCaseAttachments is not be pulling the Data-WorkAttach-File details you need.
The section Archived data in our main documentation The Case archiving and data expunging processes explains the product's priorities:
- Simpler implementation
- Higher performance
- Improved resiliency
- Maximum performance out of the box
After the system completes the archiving job, you can still search and review Cases in the secondary repository, but the data is deleted from your primary Pega database. The following diagram illustrates the Case archiving process:
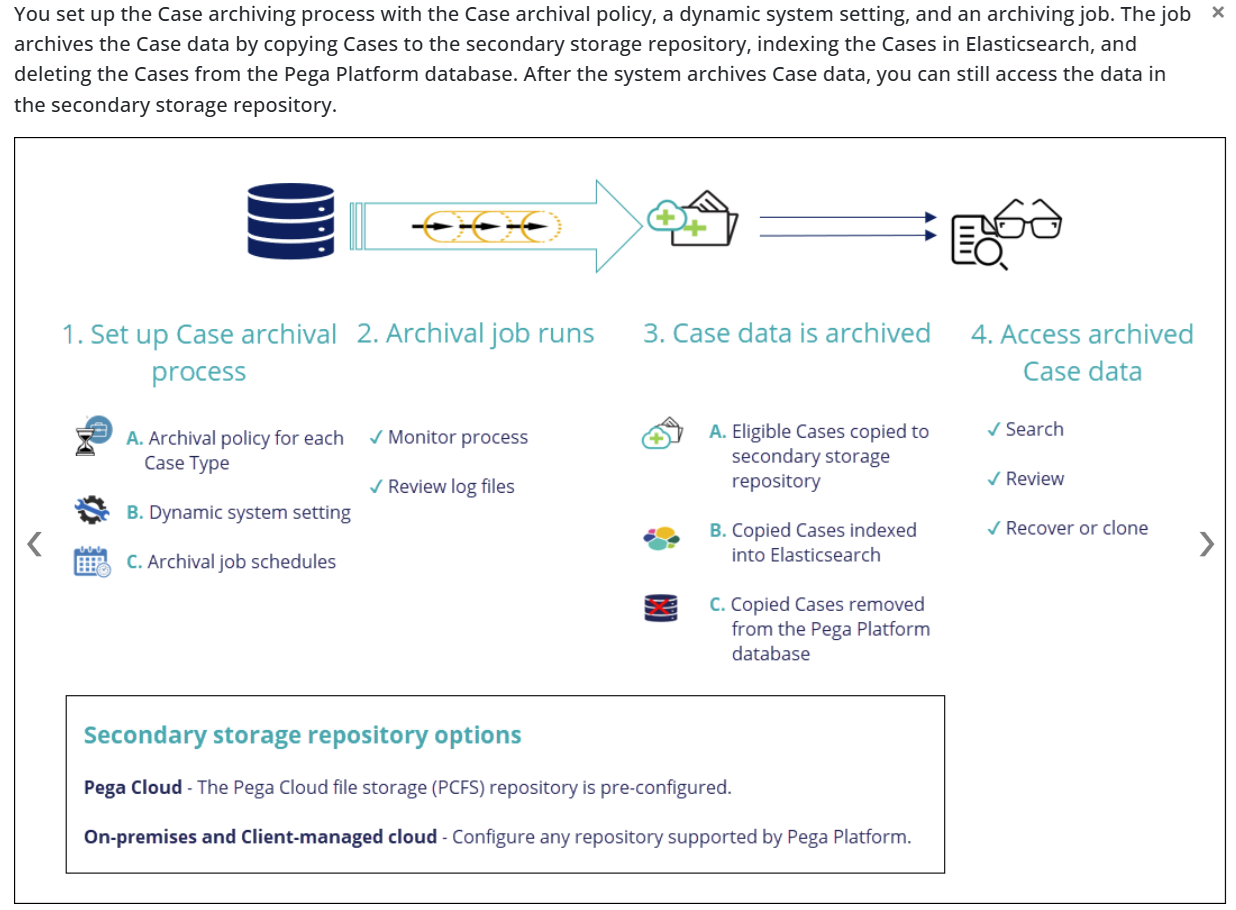
We have a support document which goes into more detail:
---> What is your business purpose for restoring the exact case data for archived ones? This does not sound right. @Chetan.Chaudhari ?
As per the documentation,
Recovery Window for Deleted Archived Data:
- For Pega Cloud clients, there is a 30-day window to recover deleted archived case data after it has been removed from the Pega Cloud File Storage (PCFS).
- This recovery process requires opening a service request via the My Support Portal.
- Important limitation: This recovery only applies to data that was deleted from PCFS, and the recovered data remains in PCFS - it cannot be imported back into the Pega Platform database.
Archiving and expunging Case data
Potential Workarounds: Since there's no direct equivalent to the legacy Purge/Archive Wizard's import functionality, you might consider these alternative approaches, though they would require custom development:
- Case Cloning: Creating new cases based on the archived case data by manually cloning the necessary details from archived cases into new active cases.
- Data Migration Tools: Utilizing data migration tools within Pega Platform to facilitate the transfer of data from archived storage back to the active database.
- BIX (Bulk Import Export): If available, extracting archived case data and then importing it back into the Pega Platform database, though this requires proper configuration and understanding of the data structure.
- Custom Activities: Developing custom activities that can read from the archived data and write back to the active database, ensuring data integrity is maintained.
These approaches would require technical expertise and custom development, as they're not standard out-of-the-box features in Pega 24.1.2.
Regarding Data-WorkAttach-File details: the documentation lists which artifacts are archived:

CSC
US
Thanks @MarijeSchillern for your response. Regarding below, since the PC_DATA_WORKATTACH is cleaned up as well after the archiving process, how to retrieve the information for custom solution? D_pzArchivedCaseAttachments and Data-WorkAttach-File details: For retrieving attachment details in pyArchivedCaseAttachments, you might need to implement a custom solution. The standard D_pzArchivedCaseAttachments is not be pulling the Data-WorkAttach-File details you need.
Regarding below, I think we can ignore this.I misspoke on my initial question by just looking at pyReviewArchivedCase harness information. Since pyWorkPage has most of the information, we are planning to customize pyCaseInformation section to render the required information that business is looking for. @Chetan.Chaudhari
What is your business purpose for restoring the exact case data for archived ones? This does not sound right.
Pegasystems Inc.
US
@Jey2705 , yes, clients have to customize the pyReviewArchivedCase Harness, as the OOTB harness only shows some OOTB properties and exposed properties; but the clipboard has every property (including embedded). Please use required Data Pages and customize the harness.
Updated: 11 Apr 2025 8:12 EDT
CSC
US
Thanks @Chetan.Chaudhari for your response. Regarding below, since the PC_DATA_WORKATTACH is cleaned up as well after the archiving process, how to retrieve the information for custom solution? Is there any Data Page that can help retrieve the Data-WorkAttach-File details that i can pull based on pzInsKey and pxLinkedRefTo filters? Thanks!
D_pzArchivedCaseAttachments and Data-WorkAttach-File details: For retrieving attachment details in pyArchivedCaseAttachments, you might need to implement a custom solution. The standard D_pzArchivedCaseAttachments is not be pulling the Data-WorkAttach-File details you need.
CSC
US
Hi @Chetan.Chaudhari @MarijeSchillern @RameshSangili. Can you please help with my above query? Appreciate your help!
Pegasystems Inc.
CA
My recommendation is to migrate the attachments to Pega Cloud flileStorage to save your database space.
Then work on Purge and Archive ... This will have the same reference location once after purge and archieve.
CSC
US
Thanks @RameshSangili for your response. We already store the document base64 in Documentum and use a reference id given by Documentum for retrieval. That reference id is stored in Data-WorkAttach-File instance so need a way to bring that reference id into Clipboard of Archived case so that we can call Documentum to retrieve the document.
CSC
US
Hi @RameshSangili @Chetan.Chaudhari @MarijeSchillern , Any update on my question specific to retrieve Data-WorkAttach-File instance for a archived case? I can go ahead and submit a support request if needed. Thanks!
Updated: 2 May 2025 6:13 EDT
Pegasystems Inc.
GB