Question
Hsbc Software Development India Pvt Ltd
IN
Last activity: 16 Oct 2018 12:03 EDT
HTML Tags getting parsed in the Incoming Email Body
Hello ,
We are using MS Outlook V2013 and Pega 6.1 SP2 Version .
We have email intigration with Outlook where we are facing issue on the parsed inccoming email into the message Body .
Its showing as HTML Tags as shown below .
|
<html>
I had raised an SR-B65838 but the person has asked to refer to below article . https://community.pega.com/support/support-articles/incoming-email-parsed-raw-html However this hasn't solved our problem . we still facing the issue . Could you please advise on this as this is showstopper issue ?
|
**Moderation Team has archived post**
Hello ,
We are using MS Outlook V2013 and Pega 6.1 SP2 Version .
We have email intigration with Outlook where we are facing issue on the parsed inccoming email into the message Body .
Its showing as HTML Tags as shown below .
|
<html>
I had raised an SR-B65838 but the person has asked to refer to below article . https://community.pega.com/support/support-articles/incoming-email-parsed-raw-html However this hasn't solved our problem . we still facing the issue . Could you please advise on this as this is showstopper issue ?
|
**Moderation Team has archived post**
This post has been archived for educational purposes. Contents and links will no longer be updated. If you have the same/similar question, please write a new post.
Accepted Solution
Tech Mahindra
IN
Hi,
We raised an SR for the same and Pega provided following solution for that:
We need to customize the OOTB function pzUnescapeHTMLSpecialChars into your application ruleset (with a different name as this is a final rule) and add code like:
HTML_TO_TEXT.put("#43", "+");
We can add similar code for other characters also. We used this function along with filterRichText and we are able to get the proper email content.
Pegasystems Inc.
US
So you made both recommended changes from that article and are not seeing any difference in behavior?
Do you have new debug output after making the exchange server changes?
I'm not sure if it will make a difference, but on your service email rule, what have you set "Handle HTML content" to for the email body message data?
Hsbc Software Development India Pvt Ltd
IN
Content-Type recommendation pertains to Exchange 2010 Server but we are using 2013 version Further Our Outlook SME reluctant to make any changes on Exchange Server since setting will be applicable on all other application based on same server .
Can't we do anything from Application Side ?
I'm using Inline -Prefer Text option in Handle HTML Conetent . Infact i have all tried all the three option mentioned over there
Pegasystems Inc.
US
Where is it "showing HTML tags?"
If the message that arrived in the Pega system had only an HTML part, this is the expected result, as Email Listener simply maps data from incoming emails. It does not transform the data.
Shell
IN
Hello Sanket,
I suspect that you are including an RTE property in your correspondence rule. If yes, you need to follow below step to include the RTE property in a correspondence. ( Contents of RTE always get stored with HTML tags to retain their styles)
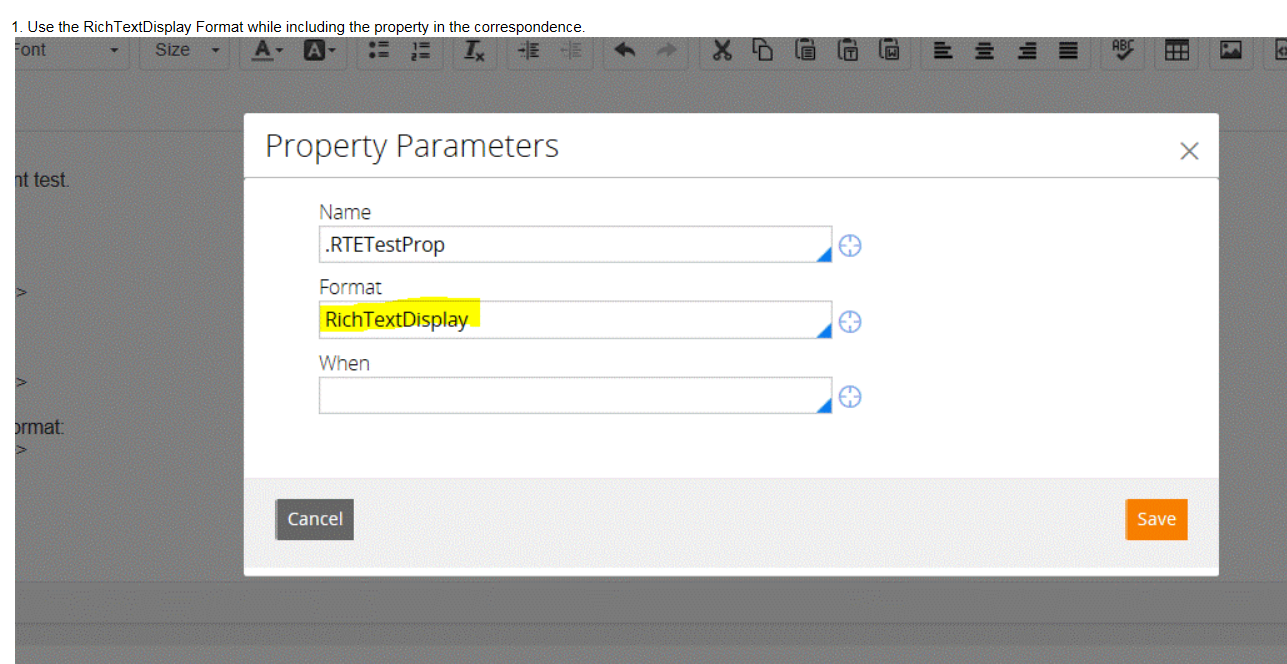
Please let me know if my understanding is wrong or if you still face issues.
Hsbc Software Development India Pvt Ltd
IN
Is there anyway to extract the plain Text from HTML Tags ?
I'm using replaceAll("\\<.*?\\>","") function but looks like it has his own limitation .
Tech Mahindra
IN
Please try using "filterRichText" function along with replaceAll function. We tried this approach. It worked for us. However, we faced an issue with this function. The function "filterRichText" is converting some special characters (@, +, = and &) in email body to html content. Other than that, it is working fine.
Please let us know if you have implemented any other approach.
Hsbc Software Development India Pvt Ltd
IN
Hi ,
Thanks for the reponse . Any Out of the Box solution for this ? Have you followed any other approach .
Accepted Solution
Tech Mahindra
IN
Hi,
We raised an SR for the same and Pega provided following solution for that:
We need to customize the OOTB function pzUnescapeHTMLSpecialChars into your application ruleset (with a different name as this is a final rule) and add code like:
HTML_TO_TEXT.put("#43", "+");
We can add similar code for other characters also. We used this function along with filterRichText and we are able to get the proper email content.
Bits in Glass
CA
How I handled the above situation:
1. created data-transform and used regular expression to remove the <meta> tag
2. created parse-xml rule and mapped the <body><p> tag
worked fine for me...