Discussion
Pegasystems Inc.
NL
Last activity: 8 Jan 2026 7:12 EST
Document Analysis: Pega Doc AI vs. OCR + NLP
Is this the end of the OCR pipeline?
Introduction
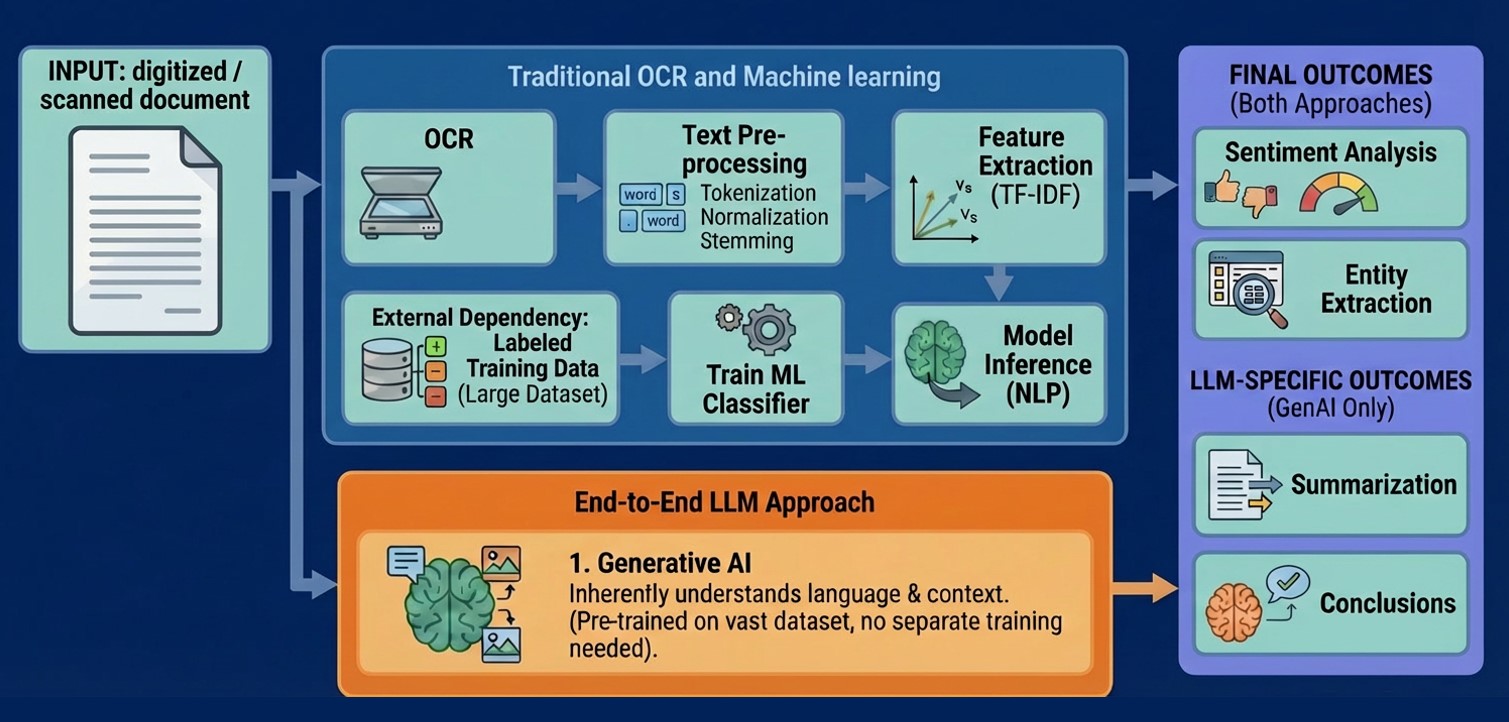
For years, analyzing scanned documents required a rigid, multi-stage pipeline. You needed Optical Character Recognition (OCR) to extract text, followed by data cleaning, and finally, specialized Natural Language Processing (NLP) models to interpret the content.
Pega Doc AI™ disrupts this paradigm. By leveraging multi-modal GenAI models, you can now integrate a single GenAI Connect step into your Case Lifecycle that handles everything from character recognition to sentiment analysis and beyond.
Both approaches have merit for different situations, and it is important to think about this choice (or combination) when designing your applications. The choice between Pega Doc AI and traditional OCR + NLP is a strategic choice between flexibility and predictability.
This article details how to think about the choice between these two approaches, how they can be combined, and how to deploy different patterns for using the Pega Doc AI approach.
The architectural challenge
Consider these common requirements:
- Sentiment Analysis: A hotel chain collects feedback from customers using handwritten feedback cards, and want to know if customers are happy about their stay.
- Complex classification: A legal firm has scanned contracts that need to be grouped based on the types of clauses in the contract.
- Entity Extraction from multiple document types: A user uploads different documents to support their insurance claim, and key details need to be extracted.
In traditional architecture, these require training specific models for each task, with the use of pre-labeled training data. With Doc AI, the approach shifts from training models to refining prompts.
Selecting the right approach for your use case
Even though I am convinced that in many situations, using the GenAI route will be quicker to set up because there are less steps involved and training data is no longer needed, there are some situations in which traditional OCR + NLP approach is the right choice.
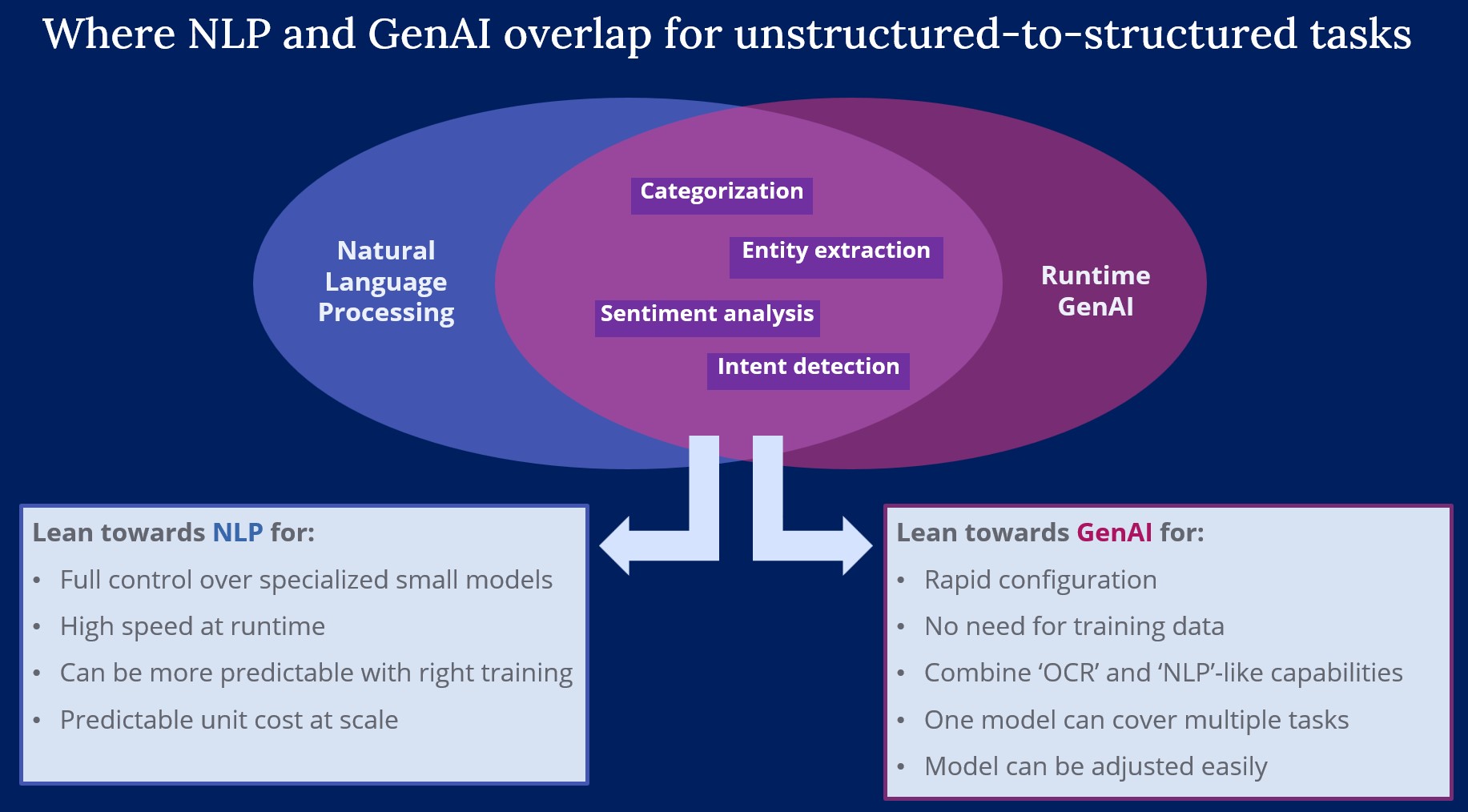
Reasons to choose an OCR + NLP approach:
- Niche precision: For highly specific tasks, such as reading ancient historical texts or custom industrial codes, a custom-trained model may outperform a general-purpose model
- Cost at scale: If you expect to process millions of simple, standardized documents and need to keep per-page processing costs to an absolute minimum.
- Deterministic outcomes: If you operate in an industry where you must be able to prove why a decision was made and need perfectly repeatable, deterministic results. The more traditional method will yield the same outcome with the same inputs every time until model retraining.
Reasons to choose a Multi-Modal LLM approach:
- Setup speed: An LLM provides a powerful, all-in-one tool without the need to collect data, train an OCR model, and then train a sentiment model. It drastically reduces complexity and time-to-market.
- Contextual understanding: Documents can contain nuance, sarcasm, industry jargon, or complex phrasing. The LLM can understand the intended meaning rather than just relying on keywords, leading to more accurate results.
- Multi-tasking: With the same LLM call, you can also summarize the document, extract key entities, translate it, or answer questions about its content, providing much more value from a single step.
- Robustness: Inputs might be photos from a phone, include handwriting, have complex layouts like tables and forms, or contain visual elements (charts, diagrams). An LLM can interpret this holistic context where a rigid OCR process would fail.
- Functional Agility: Business requirements evolve. If you need to, for example, refine a broad sentiment score into granular metrics (e.g., separating "food" from "service" quality), traditional NLP demands model retraining with new labeled data. With GenAI, simply adjust the prompt and map the new output fields.
Hybrid Architectures
Because of the different strengths of the two approaches, we can also consider patterns where the OCR + NLP approach and the LLM approach are combined.
Patter 1: The "Bridge-to-Scale" Strategy
Start with GenAI for speed, switch to NLP for scale.
Start with an LLM based approach, which is quick to implement and means your use case can start adding value rapidly.
- Phase 1 (Launch): Use GenAI to handle all document processing. This allows you to deploy immediately without weeks of model training.
- Phase 2 (Optimize): As the application runs, it processes thousands of documents.. Especially if you initially use a human-in-the-loop approach, you are effectively building a high quality labeled dataset
- Phase 3 (Scale): Once volumes reach a tipping point, use your accumulated history to train a specialized OCR + NLP model. You can then swap the processing logic with zero disruption to the user experience.
Pattern 2: The "Confidence-Based" Router
Use OCR for the standard, use GenAI for the exception.
In many workflows, 80% of documents are standard (e.g., official forms), while 20% are messy exceptions (e.g., mobile photos or non-standard layouts).
- Step 1: Run the document through a low-cost OCR + NLP pipeline first.
- Step 2: Check the Confidence Score. If the model is confident (e.g., >90%), process the data.
- Step 3: If the confidence is low, or if the document type is unrecognizable, automatically reroute the item to the GenAI Connect step.
This architecture gives you the predictable low cost of traditional OCR for the bulk of your work, while using the "intelligence" of GenAI to handle the complex edge cases that previously required human intervention.
Real world implementation with Pega Doc AI™.
Now that we’ve discussed when this type of data extraction using Doc AI would make sense, let’s look at how to set this up
Technical considerations for using Doc AI.
- Prerequisites: Available from Pega Infinity 25.1. Requires Pega Cloud 3 and GenAI enablement.
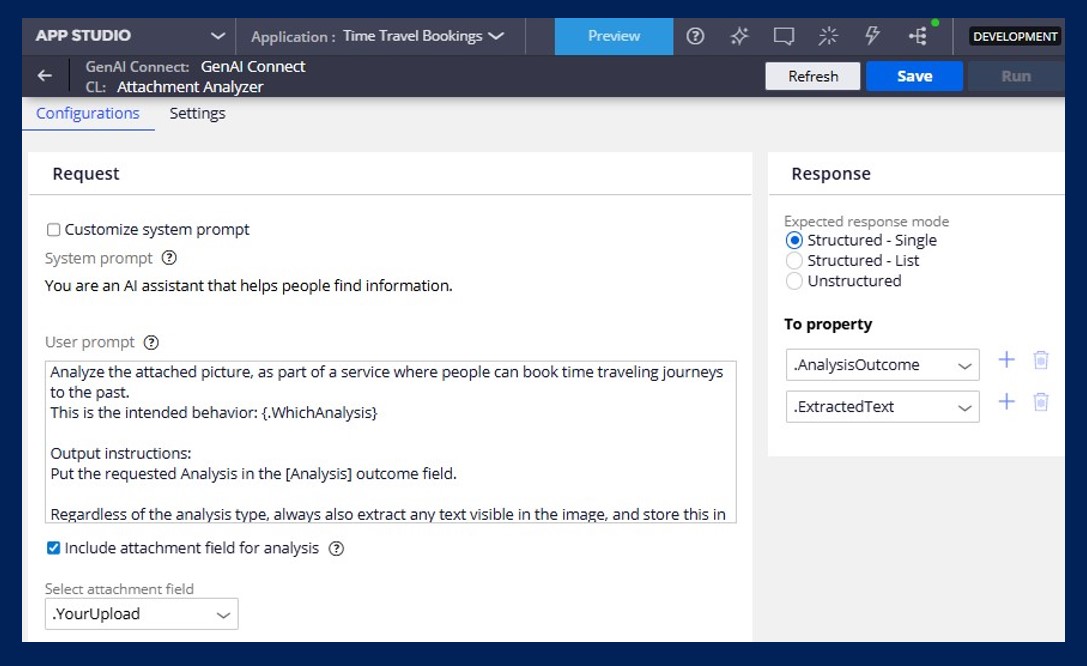
- Configuration: Configured via the Connect GenAI step by mapping an attachment field as an input.
- Model selection: The types of files you can process depend on the capabilities of the multi-model LLM you use. For standard PDFs, GPT-4o works well. For complex image formats like HEIC, consider Gemini models. See this page for more details: Creating GenAI Connect Rules in Dev Studi
- Security: If users upload documents manually, ensure file type restrictions are enforced at the attachment mechanism level to prevent errors in processing unsupported file types.
Patterns
Handwritten text, Sentiment analysis + Multi-task in single step
Use Case: A hotel chain collects feedback from customers using handwritten feedback cards, and they want to do sentiment analysis on the feedback.
Without LLM use, this workflow would require a complex daisy-chain of services. A specialized OCR engine to decipher handwriting, a separate NLP model to score the sentiment, and finally, a human agent to read the text and compose a reply.
Using a single GenAI Connect step, you can prompt the multi-modal model to perform four distinct actions in one pass:
- Validation: It verifies that the uploaded image is actually a feedback card and not an irrelevant photo.
- Transcription: It extracts the text, accurately interpreting cursive or messy handwriting that standard OCR might struggle with.
- Analysis: It classifies the feedback category (e.g., "Room Service," "Cleanliness") and calculates a sentiment score.
- Response: It drafts a personalized email to the guest addressing their specific positive or negative points, which is then routed to a manager for final approval.
Semantic Classification (Contextual Understanding)
Use Case: A legal firm needs to audit a massive archive of scanned contracts to identify which ones contain "Force Majeure" (liability exemption) clauses.
Lawyers draft clauses differently in every contract. A traditional NLP model relies heavily on keywords. If a contract describes the concept of an "unforeseeable event preventing performance" but never explicitly uses the phrase "Force Majeure," a standard keyword-based model will likely miss it, creating legal risk.
The multi-modal model reads for intent, not just syntax. Because it understands the semantic context of the document, it can identify that a specific paragraph functions as a Force Majeure clause, even if the terminology is non-standard. This allows the firm to accurately tag and group contracts based on their legal meaning rather than their exact wording. While this example focuses on a single document, this pattern easily scales to cycle through an entire repository of archives.
Conclusion
The true power of Pega GenAI Connect lies in how it transforms document analysis from a rigid engineering project into a flexible configuration task.
By bringing multi-modal intelligence directly into the Case Lifecycle, you remove the friction between "seeing" a document and acting on it. You are no longer constrained by the limitations of predefined OCR templates or the lead time required to train new NLP models. If your business requirements change, your solution can adapt instantly.