Discussion
Pegasystems Inc.
JP
Last activity: 21 Oct 2024 1:53 EDT
Case ID generation mechanism
Hi,
In this post, I am sharing case ID generation mechanism and how it can be customized.
First of all, case ID consists of three parts - [prefix]-[integer]-[suffix] as shown below.
| No | Example | Prefix | Sequence # | Suffix |
|---|---|---|---|---|
| 1 | C-100 | C- | 100 | |
| 2 | 15378-DR | 15378 | -DR | |
| 3 | MORT-763-K4 | MORT- | 763 | -K4 |
You can use either prefix, or suffix, or both along with sequence #. "Suffix" is blank by default and most of customers don't use it in my experience but you can use it if it's preferred. "Prefix" is added to your application rule automatically (the initial letter of the case type by default) when you define a case type.
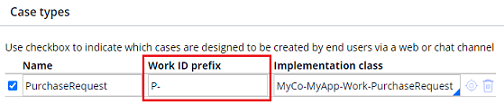
1. How to customize it
There are three approaches to change it. Try it in the order of 1, 2, 3. If what you're trying is not possible in the approach, try next one. FYI, if you update all of them, precedence is 3 > 1 > 2.
| No | Approach | Comments |
| 1 | Application rule | You can update prefix in the application rule. Only prefix is changeable and suffix can't be configured. You can only enter static string value (expression is not allowed). |
| 2 | pyDefault data transform | You can set .pyWorkIDPrefix (prefix), and .pyWorkIDSuffix (suffix) in the pyDefault data transform. You can use expression to set dynamic value. |
| 3 | Work-.GenerateID activity | You can override Work-.GenerateID for greater flexibility. Prefix, suffix, or sequence # (*) can be customized. |
* In my experience, very few customer wants to customize sequence # generation logic. Although it is technically possible, I would not recommend it as it is a bit risky and may cause unexpected issues. For example, one of my customer couldn't use Package Work wizard, which migrates work object from one environment to another, because they customized sequence # and it is not supported by this wizard. If you really need to do this, make sure the ID is always unique and also there is no performance problem in a multi-node environment.
2. Sequence # generation mechanism
There has been a change in 8.3.1. Let me explain old / new mechanism and why it was changed. Be noted, this new mechanism was introduced only in PostgreSQL and it is not available for other database for now. However, we are planning to extend it to Oracle and Microsoft SQL Server from 8.7. For DB2, we don't have any plans at moment.
(1) Old mechanism (~ Pega 8.2)
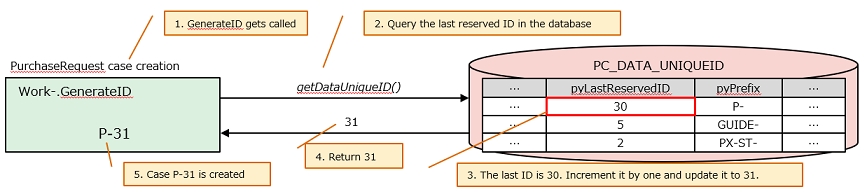
The latest ID is maintained in the database table (PC_DATA_UNIQUEID) per case type. Every time case gets created, system calls Work-.GenerateID and it queries and updates the value in the table. The ID is incremented by one and returned to app node.
(2) New mechanism (Pega 8.3.1 ~)
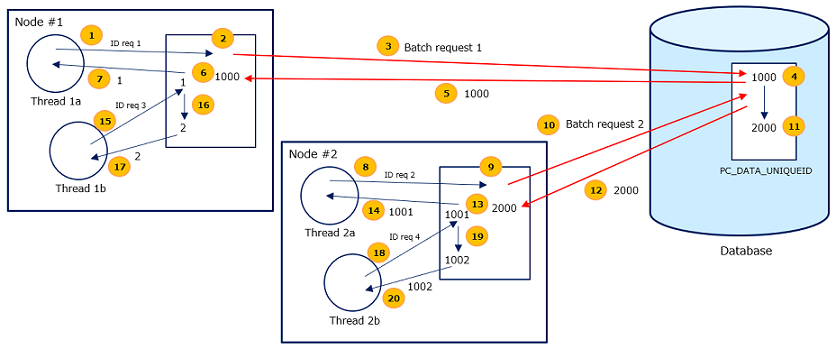
The latest ID is maintained in the app node. Database table (PC_DATA_UNIQUEID) is still used, but it only holds the chunk of scope (called "batch size"). For example, when the very first case is created, app node queries the batch size in the database. Since there is no entry in the table, system updates it to 1000 (by default). App node is assigned with 1-1000 scope. Hence the 1st case's sequence ID becomes 1. When next case is created on the same app node, it won't hit the database anymore and 2 is assigned immediately since the latest ID is maintained at app node (not database). This continues until either the app node exhausts the assigned scope (1-1000), or restarts. Be noted, this process happens per app node. For example, if app node #2 comes up, it is assigned with the next chunk (1001-2000). Hence, even if the latest ID in the app node #1 is in the middle of scope, app node #2 will start with 1001 regardless.
* Why it was changed
The old mechanism largely relied on database and performance was bad. Communication between app node and database is costly. Actually, the half of case creation process time was this ID generation. So, bottleneck issues were sometimes reported in a high load environment. More importantly, in a multi-node environment, the case generation can happen at the same time between nodes, and it could cause contention as the row is shared for all nodes. New mechanism reduced the number of communication between app node and database and increased the performance. Now ID generation takes only less than 5% of its case creation process time.
* Business impact
As a side effect of this new mechanism, now the sequence ID jumps around between nodes or every time you restart the system. Prior to 8.3, the case was pretty much sequential - 1, 2, 3, 4, 5...etc. Now, it goes like 1, 1001, 2, 2001, 3001, 3, 4, 3002... etc. This is all caused by technical reasons. However, for some customers or business type, sequence # is important. So I would recommend you to consider with business people the balance - if, the sequence # is more important than performance, you can change the batch size. Or if you don't get bothered by sequence #, you can keep the default.
* Batch size update
The default value is 1000, but you can change it by Dynamic System Settings. For example, if you update it to 1, system will behave like old version. Be noted performance gets slower in that case.
- Dynamic System Settings: idGenerator/defaultBatchSize
- Owning ruleset: Pega-RULES
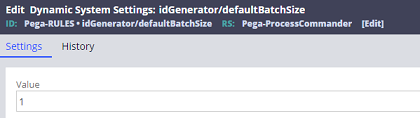
- If you want the batch size to differ per case type, you can create another Dynamic System Settings (ex. idGenerator/P-/batchSize). Be noted, this is case sensitive and if you type "BatchSize" instead of "batchSize", it won't take effect.
- If you plan to update batch size, I would advise you to do so before you create the first case. This is because, if you update Dynamic System Settings after case creation, pyLastReservedID is updated to 1000 anyways, and when the app node is restarted or user connects to other node, system will create 1001 regardless of the value in Dynamic System Settings. This is one step behind, and customer may feel the change is not reflected immediately. Usually this should be okay because the Dynamic System Settings is included in the R-A-P and imported to production environment before the very first case is created. But if you care sequence ID even in Dev, I would suggest to do so before defining a case type to avoid unnecessary confusion.
* Utilizing PC_DATA_UNIQUEID table for non-work
I have also written up an article about how to utilize this PC_DATA_UNIQUEID table to get the next auto-increment ID for non-work (ex. Data Type). Please see https://collaborate.pega.com/discussion/how-get-next-auto-increment-id-pega.
Thanks,
WellsFargo
IN
Capgemini
IN
Great insights on Case ID generation @BraamCLSA.
ING Bank
NL
Excellent Post!!
CVS Health
US
Fantastic approach explained on the Case ID generation in V83 and later. I understood the bottleneck and the process improvement in the product. Nice post.
Thanks,
Ravi Kumar Pisupati.
Morgan Stanley
IN
Awesome explanation!!!
Centene
US
Excellent Post and thank you!
SolvenTech
IN
Its Very Useful article. I have one question.
In Appnode1 -- 1000 and appnode2 1001 -- 2000. on Each node 500 cases processed and next I restarted my app Server nodes.
So it would be incremented to next batch i.e. 2001 to 3000 on node 1 and 3001 to 4000 on node 2
or it will use old batch number as it is not exhausted.
Please explain me.
Pegasystems Inc.
JP
Hi,
In the new mechanism, as I explained, allocating the next batch size process occurs either when the app node exhausts the assigned scope, or system restarts. In your example, whichever node starts first will take 2001 - 3000 and the latter node will take 3001 - 4000 (*).
* Technically speaking, allocation is not triggered by restart itself. It is triggered by case creation after system restart. For example, assuming that you have one app node and someone created the first case (W-1). Then if you restart the system 10 successive times (without creating any cases), will the next case ID be W-10001? Nope, W-1001.
Thanks,
ASB Bank
NZ
@KenshoTsuchihashi With this approach, if few cases were created in the initial batch size for a node and the node is restarted, does it ignore the id's in the old batch size ?
ex: C-1 to C-100 are created on node 1 with batch size 1000.
after C-100 is created, node is restarted. As you said, the next case creation on the node after it is restarted will take next batch size, i.e. next case id will be C-1001.
Does it mean all the 900 ID's in initial batch are ignored and no longer used ??
Pegasystems Inc.
JP
That's correct. Once system is restarted and ID is moved up by batch size, the skipped IDs are lost - there is no chance that these not-exhausted IDs will be used by system any more.
Updated: 28 Jul 2021 2:17 EDT
Barclays Global Service Centre Private Limited
IN
@KenshoTsuchihashi How to generate Case Id starting from 1000000. For example C-1000000 then C-1000001...
Updated: 31 Jul 2021 6:15 EDT
Pegasystems Inc.
JP
Hi,
This is an odd requirement and I don't know what kind of business value it creates, but if I were asked to do this task, I would probably update PC_DATA_UNIQUEID table rather than overriding Work-.GenerateID activity. This way, it doesn't need any rule implementation. Here are the steps.
1. Create a very first case (C-1).
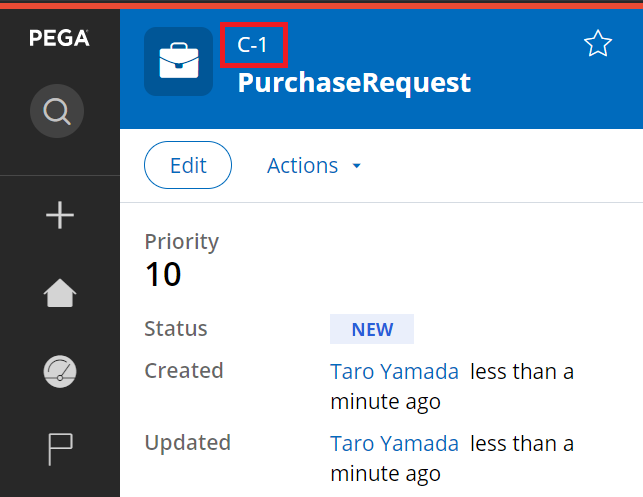
2. A new record is inserted into PC_UNIQUE_ID table as below. As explained, pyLastReservedID is filled with "1000" initially.
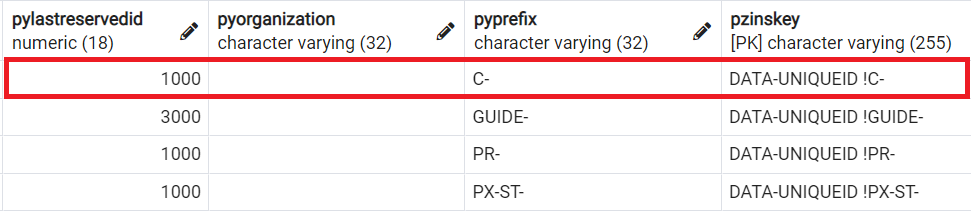
3. Create an activity as below. Run it to update pyLastReservedID with "999999".
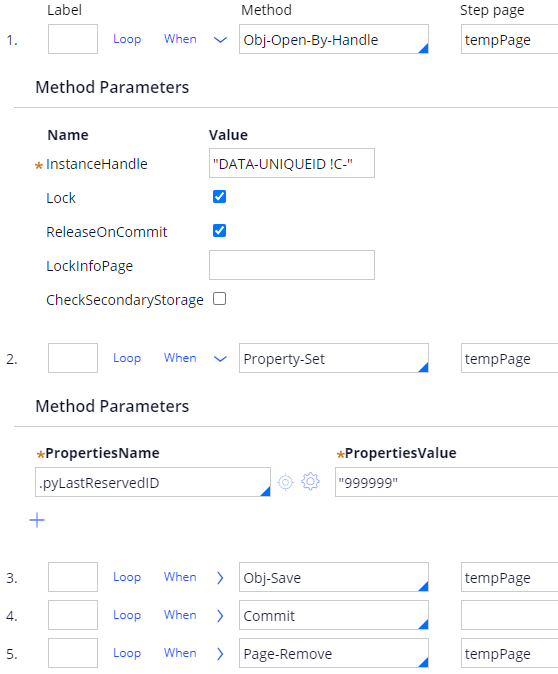
4. Delete work object you just created from Work-, History-Work, and Assign- mapped table. These tables should be sufficient unless you added derived objects such as Workparty, Attachment, Pulse, etc.
5. Reboot all app nodes.
Hi,
This is an odd requirement and I don't know what kind of business value it creates, but if I were asked to do this task, I would probably update PC_DATA_UNIQUEID table rather than overriding Work-.GenerateID activity. This way, it doesn't need any rule implementation. Here are the steps.
1. Create a very first case (C-1).
2. A new record is inserted into PC_UNIQUE_ID table as below. As explained, pyLastReservedID is filled with "1000" initially.
3. Create an activity as below. Run it to update pyLastReservedID with "999999".
4. Delete work object you just created from Work-, History-Work, and Assign- mapped table. These tables should be sufficient unless you added derived objects such as Workparty, Attachment, Pulse, etc.
5. Reboot all app nodes.
That's it. Now if you create a case, ID becomes "C-1000000". It goes like 1000000, 1000001, 1000002... until 1000999 as long as you are on the same app node.
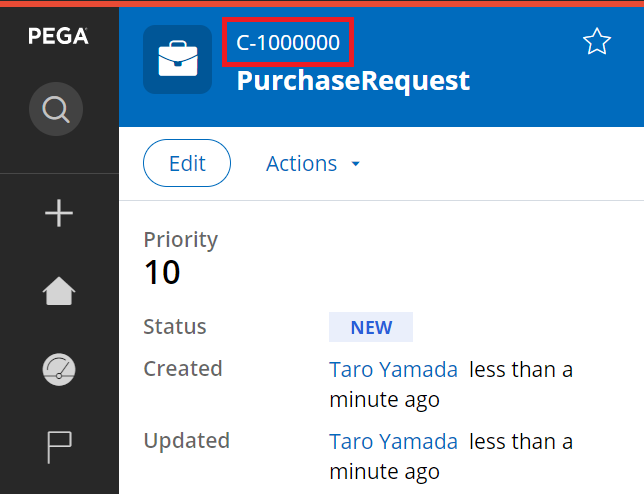
If you reboot the app node, or if you connect to other app node and create a case, then ID becomes "C-1001000".
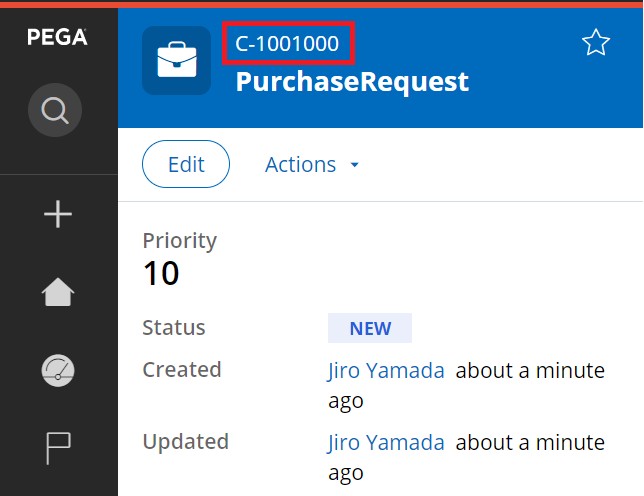
Thanks,
Pegasystems Inc.
US
@SyedHasanZ , can you shed some light on why do you need to start at 1,000,000? There's a way but it's not a good practice, so would like to get proper context.
Atos
GB
@KenshoTsuchihashi Excellent !! I was looking for this answer since last few months and finally I got it here. Thanks a lot.
TECHMAHINDRA
IN
@KenshoTsuchihashiVery well explained kensho San
Inovar
SA
Contention issue is resolved , which is a great achievement i can say. But sequence is also very important for some customers.
I think we should think of solution for sequence as well.
TalentSprint
IN
@KenshoTsuchihashi Thank you for this post
Accenture
AU
Very useful post and great explanantion.
Capgemini Nederland B.V.
NL
Hi @KenshoTsuchihashi ,
This was really a great explanation...!! Thank you..!!
Looking forward for an update which can address the sequence issue we have with this new mechanism.
Thanks.
Maantic Inc
US
We are in pega SCE framework with V8.5.1, it uses old approach to generate unique.
Currently the issue, what we are facing, when multiple queue processor, trying to create a work object, PC_DATA_UNIQUEID stuck in deadlock.
This application in prod. Without impacting current prod data, how to move the unique id generation from old approach to new one.
database : aws postgres aurora
Knowledge Expert
FR
Maybe its time to move to not so user frendly, but blazing fast and reliable UUID?
Ford Motor Company
US
@KenshoTsuchihashi Thank you for the detailed explanation.
UBS
IN
@KenshoTsuchihashiCritical information. Thanks for sharing. But have serious doubt on this design change and the motivation behind this. Not buying the new mechanism of ID generation specially in cloud architecture where pods creation and deletion is more too often.
TD
CA
@KenshoTsuchihashi Thank you for the detailed explanation on this topic! You mentioned this was initially only effective for PostgreSQL DB and was planned for Oracle and MS SQL from Pega 8.7. We have recently upgraded to Pega 8.6.4 (Azure MS SQL MI) and seeing the new ID generation mechanism has kicked in. Could you confirm exactly in which Pega version this has been introduced for MS SQL ?
Thanks!
Updated: 14 Jul 2022 20:22 EDT
Pegasystems Inc.
JP
@trina_r @Chetan.Chaudhari
I've just checked with product engineering team and I learned that new case ID generation mechanism was backported to 8.5.6 and 8.6.3 for both MS SQL Server and Oracle. In summary, the version for all DBMS that applied this mechanism is shown in the table below.
| No | DBMS | Pega version that introduced new case ID generation mechanism |
| 1 | PostgreSQL | 8.3.1~ |
| 2 | MS SQL Server | 8.5.6~ & 8.6.3~ & 8.7.0~ |
| 3 | Oracle | 8.5.6~ & 8.6.3~ & 8.7.0~ |
| 4 | DB2 | N/A (we don't have any plans to extend to DB2) |
Thanks,
TD
CA
@KenshoTsuchihashi Many thanks Kensho San! Great information.
Thanks
Pegasystems Inc.
US
This is a very helpful post
Paul Hartmann AG
DE
So much informative and useful post!!Thanks for sharing.
Paul Hartmann AG
DE
If we have already implemented it in prod without changing DSS settings to 1, will it be possible to change it then and make it sequential? What will be the impact on already created cases in PROD
Pegasystems Inc.
JP
As I wrote in my original post, if you want to change BatchSize DSS, do so before the very first case is created to avoid unnecessary confusion. You are given sufficient time during development period before Go-Live. Having said that, if customer has already created cases in production system with default BatchSize (1000), and they want to change it from now on, you can still do so. I've outlined how things work in sequential order based on your scenario.
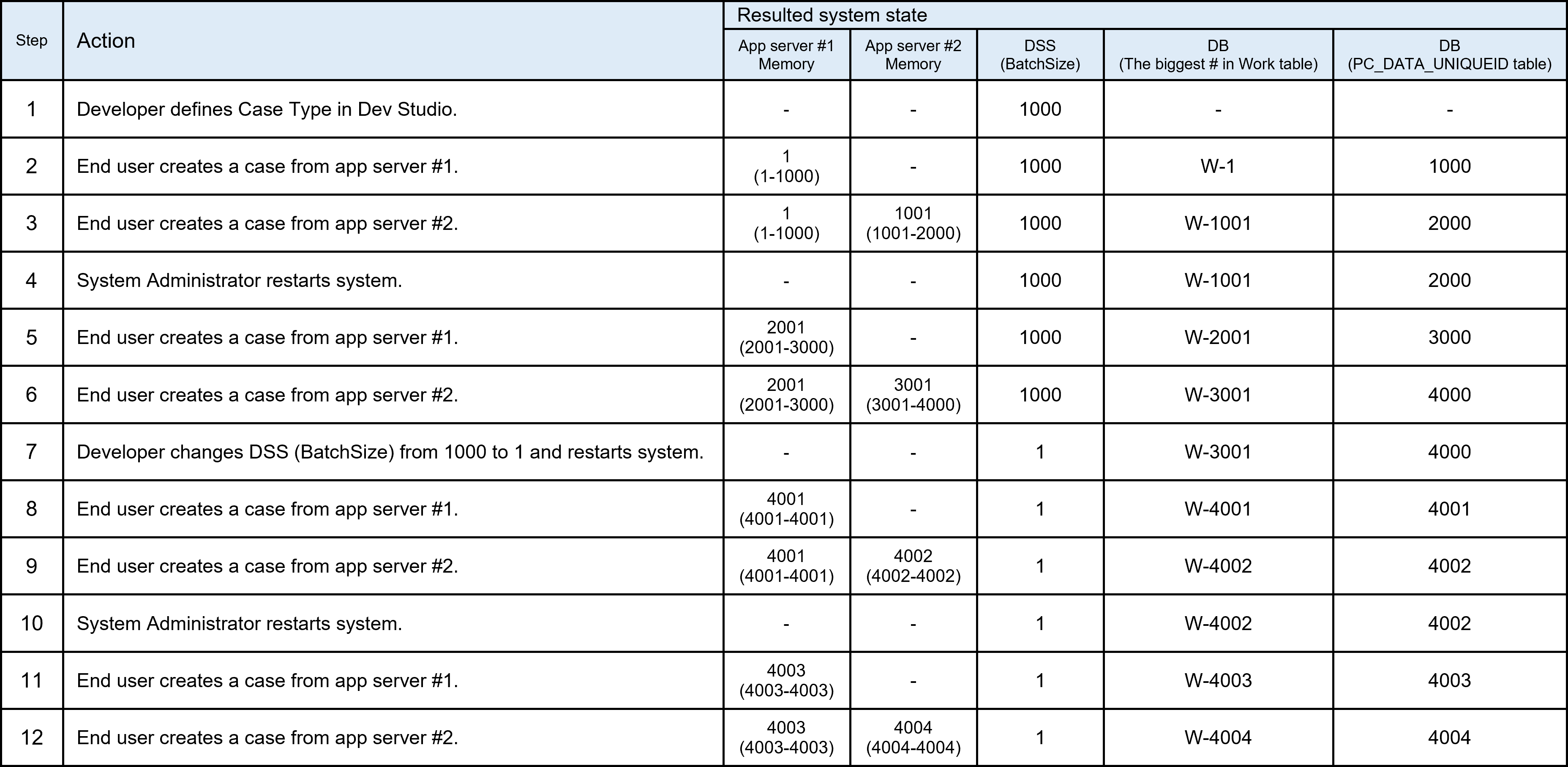
In step 8, you can see case ID jumps to 4001 from 3001 although BatchSize DSS was already updated to 1 in prior step 7. This is because DSS update does not get reflected until system is restarted. Hence, this first jump can't be avoided. However, once system is restarted, case ID increments by one onwards just like old case ID generation mechanism. Hope this clarifies your question.
Thanks,
Paul Hartmann AG
DE
@KenshoTsuchihashi Thanks for sharing. Also suppose we have 4 PEGA application in organization and i want to implement this change to only one application , is it possible?
Because by default owning ruleset is PEGA RULES for this dss. I tried changing to application ruleset as owning ruleset and save, but it is not working
Updated: 5 May 2023 6:29 EDT
Pegasystems Inc.
JP
First of all, case ID generation mechanism is shared across applications as PC_DATA_UNIQUEID table is common within a single Pega instance. For example, suppose you have two applications that happen to use the same case ID prefix "P-", as shown in the diagram below. If the first case is created from MyApp1, "P-1" is created. Then, if the second case is created from MyApp2, "P-2" is created. You can't individually assign the same case ID for multiple applications. Similarly, if you create a Dynamic System Settings rule "idGenerator/defaultBatchSize" and set it to 1, the change is applied to both MyApp1 and MyApp2.
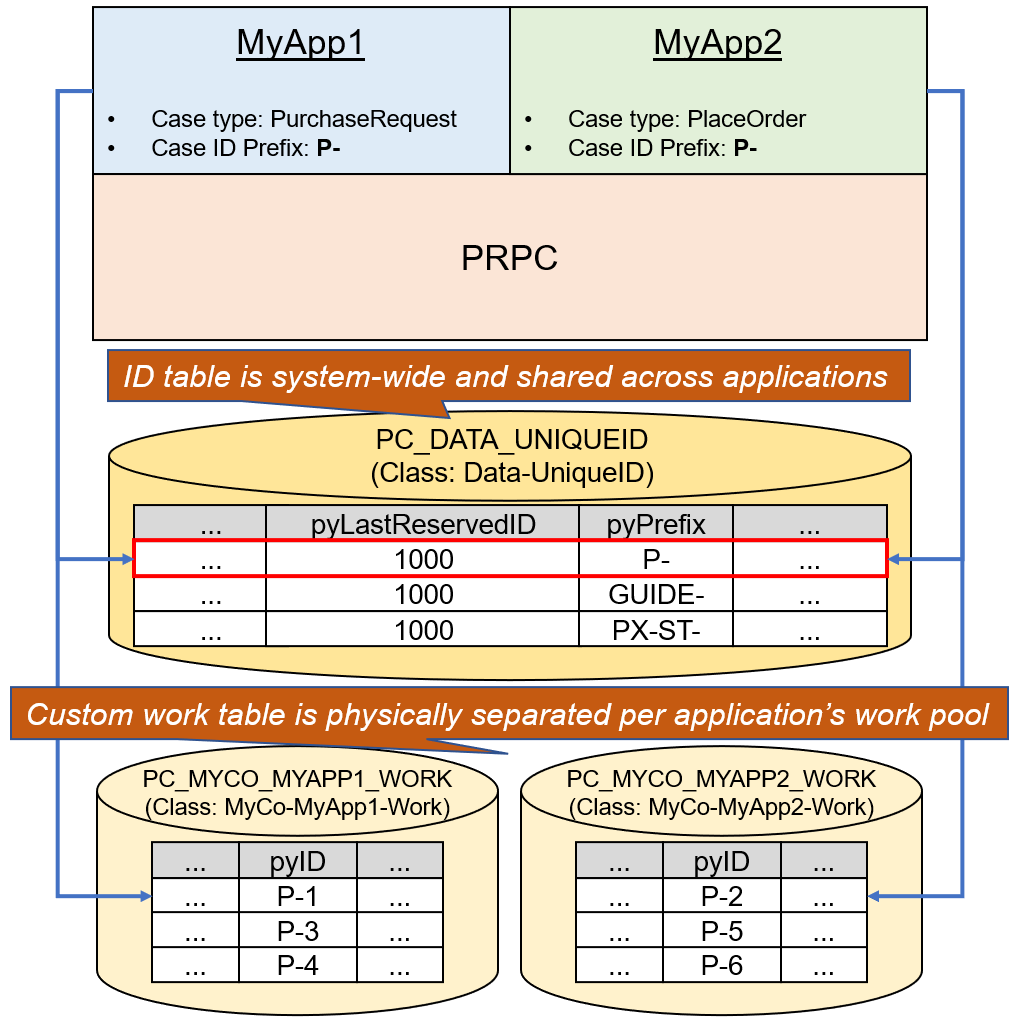
First of all, case ID generation mechanism is shared across applications as PC_DATA_UNIQUEID table is common within a single Pega instance. For example, suppose you have two applications that happen to use the same case ID prefix "P-", as shown in the diagram below. If the first case is created from MyApp1, "P-1" is created. Then, if the second case is created from MyApp2, "P-2" is created. You can't individually assign the same case ID for multiple applications. Similarly, if you create a Dynamic System Settings rule "idGenerator/defaultBatchSize" and set it to 1, the change is applied to both MyApp1 and MyApp2.
Now, if case ID prefixes are all separate across multiple applications, which I think is a better practice anyways to avoid confusion, you can still control it by creating an individual Dynamic System Settings rule, "idGenerator/X-/batchSize". For instance, assume that you define PurchaseRequest case ID prefix as PR- in MyApp1 and PlaceOrder case ID prefix as PO- in MyApp2. If you want only PR- prefix to be incremented by one, you can create "idGenerator/PR-/batchSize" Dynamic System Settings rule and set it to 1. This way, other case type including PO- keeps the default behavior. Hope this clarifies your question.
Thanks,
IT Solution Service
SG
Thanks for the info. I have a question. If the same case ID can't be assigned across multiple applications, does that mean we cannot rely on case numbers? Also, some of the OOTB work object prefixes are defined by product. Can't that be sometimes problematic?
Regards,
Updated: 7 May 2023 6:41 EDT
Pegasystems Inc.
JP
That is correct, you can't rely on case ID for numbers even if you make case ID increment by 1 by creating DSS, and even if you have only one application in your Page instance. Case ID does not count cases as it is not guaranteed to be always sequential. Although every case has a unique ID, your application might include gap in case ID sequencing. For example, if a Commit method fails and a Rollback occurs after case ID W-6788 is assigned, the case is not created and the number is never reused. This results in a gap between W-6787 and W-6789. It is important to understand the nature of Pega's case ID.
Regarding out-of-the-box case ID prefix, the same rule applies. For example, when developer in MyApp1 launches REST Connector integration wizard, system creates a work object "pxDataSource-1". When another developer in MyApp2 does the same operation, "pxDataSource-2" is created, instead of "pxDataSource-1". Most of the time, this is not problematic because these are internally created on background and case ID is not exposed to end users / developers.
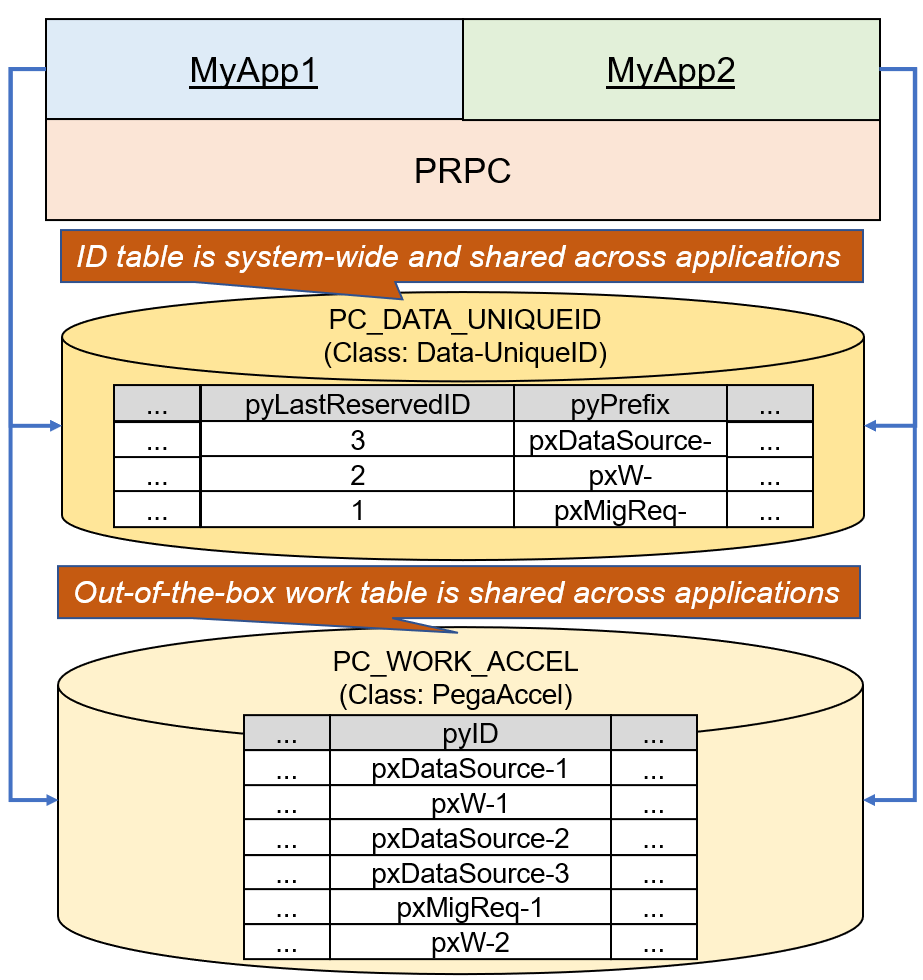
That is correct, you can't rely on case ID for numbers even if you make case ID increment by 1 by creating DSS, and even if you have only one application in your Page instance. Case ID does not count cases as it is not guaranteed to be always sequential. Although every case has a unique ID, your application might include gap in case ID sequencing. For example, if a Commit method fails and a Rollback occurs after case ID W-6788 is assigned, the case is not created and the number is never reused. This results in a gap between W-6787 and W-6789. It is important to understand the nature of Pega's case ID.
Regarding out-of-the-box case ID prefix, the same rule applies. For example, when developer in MyApp1 launches REST Connector integration wizard, system creates a work object "pxDataSource-1". When another developer in MyApp2 does the same operation, "pxDataSource-2" is created, instead of "pxDataSource-1". Most of the time, this is not problematic because these are internally created on background and case ID is not exposed to end users / developers.
Another scenario is, Pega also defines some business case IDs that are used by end users during work process. For example, when user likes or comments on someone else's pulse post, system creates a Notification work object whose case ID prefix is "N-". The first comment in MyApp1 is "N-1", and the next comment in MyApp2 is "N-2". These case IDs are not shown explicitly in the end user portal, but if you create a report that lists the Notification cases, the ID will look skipped randomly. In summary, the same case ID can't be issued across applications, and this is the limitation of the current shared ID table.

Thanks,
IT Solution Service
SG
I knew about Notification work object, but did not know the prefix is "N-" until now. I thought all OOTB case ID prefix is very specific like "pxDataSource-", "pxW-", "pxMigReq-", etc. This one-letter naming is very generic and I guess some customers may use it by coincidence. Can we use "N-" prefix for our own work type? If yes, doesn't that cause confusion as both custom work type and Notification use the same prefix?
Regards,
Pegasystems Inc.
JP
You can define "N-" for your own work type, too. System won't throw any exceptions or warnings at both design time and runtime when it conflicts with out-of-the-box work object prefix. As a matter of fact, one of our customers had defined "N-" without knowing it's used by product, and they realized that created case ID is skipped randomly because Notification work objects also take the sequence #. Although I explained to customer that case ID is not guaranteed to be always sequential because when Commit method fails the ID will be skipped, I agree this is unnecessary confusion. The possibility that Commit method fails is very rare, and I understand that many customers would expect the ID is pretty much sequential at least most of the time. In that sense, I would recommend that customer avoid prefix that product uses.
Thanks,
Updated: 7 May 2023 7:09 EDT
IT Solution Service
SG
Understood, thanks for the clarification. However, if it is recommended to avoid OOTB prefixes that product uses, I think it is Pegasystems' responsibility to provide the list, which I can't seem to find over the Internet. Is it public somewhere?
Regards,
Updated: 27 Apr 2024 12:46 EDT
Tata Consultancy Services
IN
Hi @CloeW938
As you can see, I have attached a list of the prefixes that are used by Pega Defaulty, and these are the instances of the Data-UniqueID Class. (Community Edition: INFINITY-23.1)

Hi @KenshoTsuchihashi ,
Could you please let us know: What is the purpose of the above prefixes, apart from M, C, and W? and please let us know any other prefixes as well.
Thanks,
Ashok
Paul Hartmann AG
DE
@KenshoTsuchihashi Thanks !!! Your explanations and descriptions using diagrams are really awesome and gives better clarity..
Pegasystems Inc.
IN
Thank you for this wonderful explanation. But i have a question on re-populating the app server with next set of allocation before any restart to the system or any changes to the DSS happens.
For the sake of simplicity, lets say i have a single node system and my default batchSize is 1000 so my cases are starting from C-1, C-2. If i continue so till C-1000 and during this time my system was never restarted and neither was any change done to the batchSize DSS limit, will the pylastreservedid in PC_DATA_UNIQUEID table get updated with 1000 or my app server will continue to create the cases beyond C-1000 with no update to the table.
Because in this case if the system is restarted post the C-1001 series then since the pylastreservedid is still 1 so the app server might by mistake the take the next in series from 1000 AGAIN which will be an issue to the ID generation, right?
Maybe you have covered this in your explanation that i might have missed, please direct me to the appropriate header in your explanation if its covered. Otherwise i would appreciate your response on this.
Pegasystems Inc.
JP
Communication between app node and database happens only when app node exhausts the assigned chunk of ID scope, or system restarts. Please see below steps. The assumption here is a single app node and Batch size DSS is the default (1000).
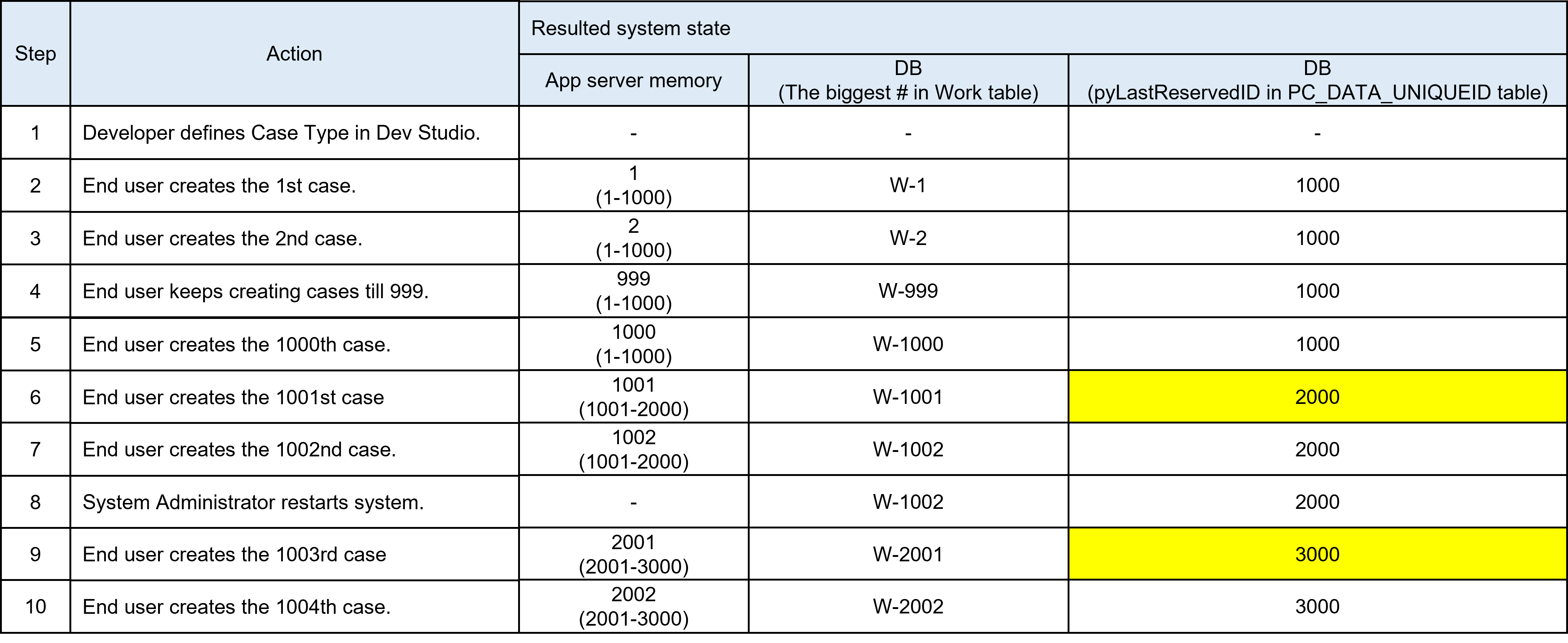
Thanks,
Wells Fargo
IN
@KenshoTsuchihashi , Thanks for Very helpful information, I have a question!
If there is a upgrade from 8.4 to v23, here we are directly jumping from Old to New GenID mechanism,
what are the consequences if we reset the batch DSS to 1 after a month of Upgrade,
and do we need to restart the servers after DSS change?
Thanks,
Harsha K
UNUM Group
US
@KenshoTsuchihashi How to reset the case id in App Node Memory , ex : we have a requirement where we are creating dummy case for testing and delete those later (via App Studio Delete Cases) , now how to reset the case id counter back to start from 1
Awesome post and good insights on what's changed at the engine side. Please keep posting similar kind of posts , I doubt even Pega help does not provide the insights your provide.
Thanks a lot.