Applies to Pega Platform version 7.3
Learn why reindexing of Rules, Data, and Work is important after you update your deployment of the Pega platform.
Learn the approaches to reindexing to determine which approach meets your needs.
Symptom
After updating to Pega 7.3, you notice that Search does not work as expected and that the Index queue of Scheduled items is extremely high. For example, more than 54,000 Scheduled items are in queue.
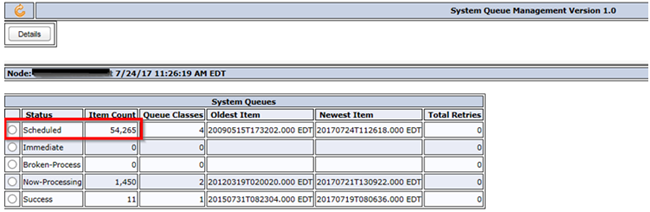
Investigation
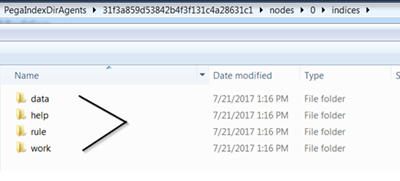
When checking the folder contents to make sure that files are being written properly, you discover that there are many folders that do not comply with the standard structure, shown in the following image:
Then you check System > Settings > Search > Agent Information and notice over 54,000 items in the Queue with the longest item in queue being more than two (2) weeks old. Online help also suggests truncating the pr_sys_queue_ftsindexer table and starting fresh to fix this issue and avoid getting caught in a race condition while reindexing and requeuing the backlog.
Explanation
Pega 7.2.2 introduced two new Dynamic System Setting (DSS) instances to disable automatic indexing after an update to the Pega platform. If you have post-update steps that are required before indexing and these steps require nodes to be restarted, you cannot restart the nodes until indexing finishes. This condition delays the update process and is a best practice that is recommended prior to updating to Pega 7.3.
The practice of reindexing the Rules and Data after a platform update has been in place since Pega introduced the server-side indexing with Lucene and now with Elasticsearch. The reason for this practice is that, during the update, the rebuilding of indexes is disabled unless you set the flag to build the indexes after the updated Rules and Data are applied to the database. Keep in mind that the engine startup process for the update is not the same as having the JVM process running Pega (PRPC). Its sole purpose is to query the database tables; identify which rules need to be inserted, updated, removed, and so on; and then apply the changes, knowing that the indexing on the server will not take place during this time. Even if the update had the option to Rebuild Indexes enabled, the rebuilding of the indexes takes place after the update finishes. This can take many hours to complete. Therefore, doing this in any High-Availability (HA) environment is not recommended.
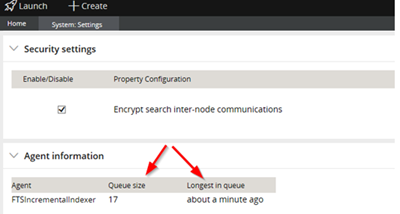
Now all items are indexed properly, and the queues are where they should be.
Best Practices
There are three ways to rebuild indexes:
- If you do not have any post-update steps that require a node restart, the settings listed below can be set to true. When the first indexing node starts (preferably before any other node in a cluster), it will begin rebuilding the indexes.
- If you choose, you can rebuild the index as part of the update process, but it will extend the outage period until all the indexes are built.
- If you have post-update steps that require a restart, add the settings below before updating to Pega 7.3 or later release and then manually initiate the re-indexing after the update process.
Dynamic System Settings
Pega-SearchEngine indexing/distributed/rebuild_indexes_onupgrade
A blank value tells the Pega system not to run the indexing job on the first node starting up after an update.
Pega-SearchEngine indexing/distributed/autonodecleanupandreindex
A false value tells the Pega system not to delete all indexes after an update and to recreate them automatically when any node in the cluster is unavailable.
In other words, if you start the non-indexing node first, the Pega system assumes that all index files are available, so it deletes them all and begins to create them again if the first DSS is set to true or false (but not set to blank).
Check the Queues
Check the Data, Help, Rule, and Work queues to make sure that they are current, do not have a large queue showing as Scheduled, or a folder structure that is incorrect.
If the queues exhibit any of those problems, complete the Solution steps.
If the queues look good, you need to rebuild the Rules and Data indexes only after an update process finishes. Rules and Data change. Work does not change as part of any update; therefore, Work does not typically need rebuilding.
Suggested Sequence
- Perform the rules update, and then perform the dataOnly portion of the update (which assumes a split-schema environment).
- After the post-update steps are finished, rebuild the Data indexes, then rebuild the Rule indexes.
Source of Confusion
You do not have to complete either the Data or the Rules indexing before users log in to the application. This has always been a source of confusion. The impact here is Search. If the indexes are in the process of being updated, some Rules or Data, or both, might not be found until the indexing process finishes. All the nodes in the cluster can be up and available to users during re-indexing.
Timing
The process can take many hours, depending on the size of the three indexes being rebuilt.
Here’s one example that took seven (7) hours: Indexes had to be rebuilt for Rules, Data, and Work, including replicating and indexing across four (4) servers in the cluster.
| Index | File Size | Instance Count |
| Rules | 956 MB | 764,331 |
| Data | 5.2GB | 243,426 |
| Work | 6.7GB | 2,856,639 |
Related Content
Troubleshooting Search indexing failures
Troubleshooting Elasticsearch issues in Pega 7.1.7 through 7.4
Pega Platform Upgrade Guide for Pega Platform version 7.3