Real time data flow consumes Kafka or Stream Data set to read existing and new records
We currently use real time data flows that consume Kafka or Stream data set information. These DFs are configured to read only new records that arrive (Only read new records).
The problem with this configuration is that Pega does not process those records that have been arriving during the time in which the data flow was stopped, it means that we lose them.
The other configuration option is to process the records that already existed and the new records. This way we would not lose these records that are sent while the data flow is stopped, but we run the risk of processing the same record several times. Before we consider changing the configuration option we need to be clear about how this second configuration option works:
- Is it possible to process records that are 2 years old? Is there any criterion applied to reprocess these records or is absolutely everything processed regardless of the date of sending?
Pegasystems Inc.
IN
Hello Raquel,
What Pega Platform version are you using ?
In your current Data Flow setup how are you consuming only the new records , is it based on a filter condition in data flow ?
Vodafone
ES
Hello Abhijit,
Pega Platform Version is 8.2.5
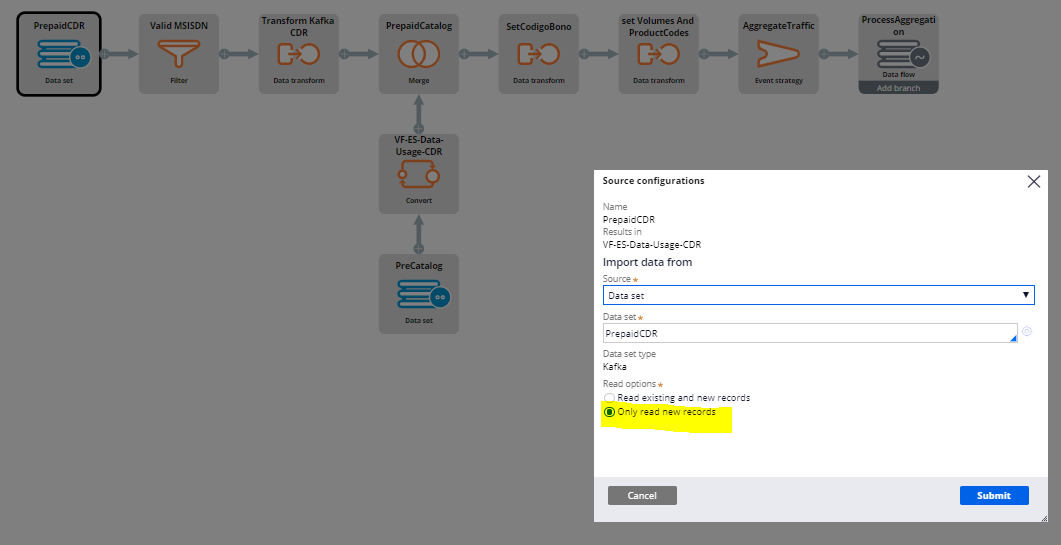
Consuming only new records configuration is set in de first component of the Data flow concretly in the Kafka Data set or Streaming Data set, in Source configurations:
Barclays
GB
Hi,
Never STOP the data flow. Always PAUSE the data flow if you want to process the record that is queued to stream data set when data flow is not running.
the advantage is
if in the stream data set if you have selected process new record, During the DF PAUSE time the events will be queued to the Stream data set. Once you resume the data flow it will process the unprocessed record.
That said it will process the records that are queued to the Kafka during the pause period.
However, if you stop the data flow then you will lose the events.
In the stream data set, there is settings for the Retention period. Though personally I have not tried that to keep 2 yrs old record.
Thanks,
Rakesh