Discussion
Pegasystems Inc.
JP
Last activity: 17 Oct 2023 9:38 EDT
Understanding Pega Blob and UDF
Hi,
In this post, I will share what I know about Pega Blob technology and UDF. If you find anything incorrect, please let me know I will revise it.
- This article was written back in Pega 8.5 days and some of the contents are old. Please see "Update" at the bottom for UDF support.
1. What is Blob?
Blob (Binary Large Object) is a data type that stores binary data. It is typically an image, audio or other multimedia object that therefore often requires significantly more space than most other data types such as integers, characters, and strings. These are classified as unstructured data. The other classification is semi-structured data such as XML files, and Pega takes this approach. Both of unstructured, and structured data are generally not interpretable by the DBMS. An application must create and edit the content, while the DBMS merely stores it.
2. How does Pega use Blob?
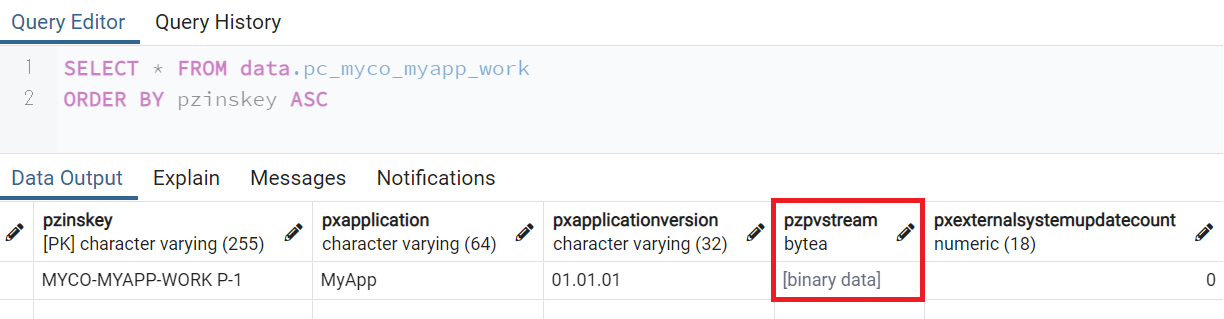
In Pega, there are few tables that do not have Blob column, such as Declare Index table, or Data Type table in the CustomerDATA schema. However, most of the tables have Blob column and it is one of the key technologies that supports Pega's data management. The name of Blob column is "pzPVStream".
Below is the process when Pega stores data into the database.
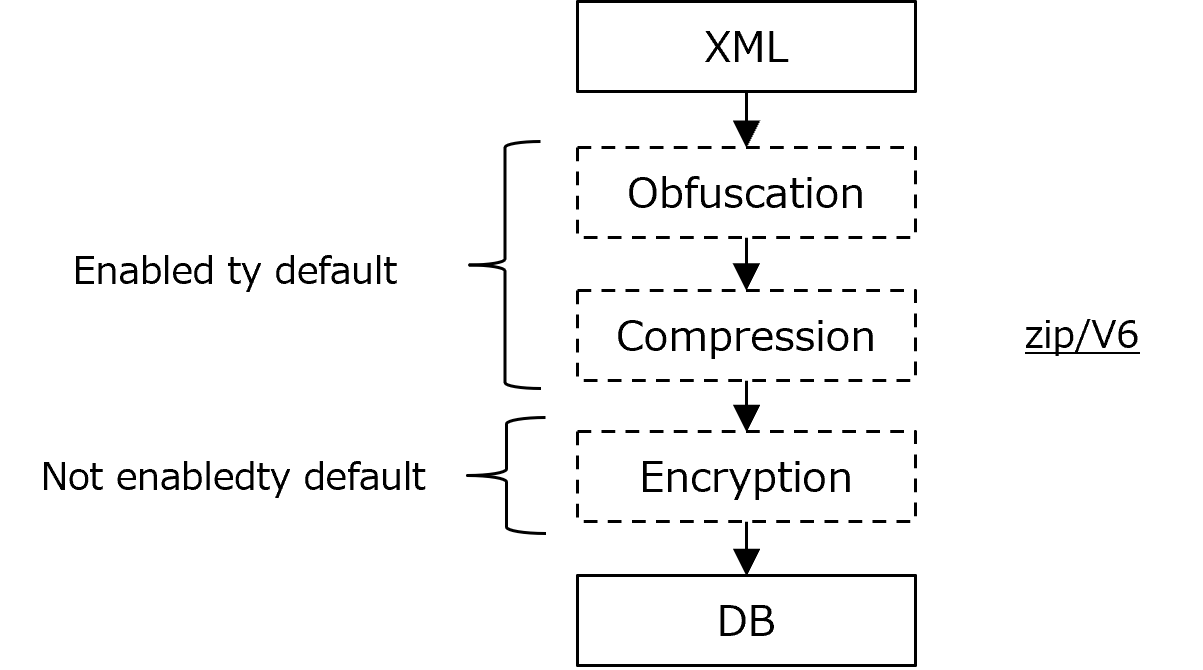
1. Obfuscation
First, Pega data (XML representation) is obfuscated and gets hard to understand for the reader. In general, "obfuscation" is a data masking technique to obscure its meaning, providing an added layer of security protection. It is similar to "encryption" but doesn't require any secret key and it provides no serious level of security like "true" encryption would (a hacker should be able to de-obfuscate it). The obfuscation algorithm is proprietary to Pega and it is not disclosed.
2. Compression
Next, Pega compresses data by using the java.utils.ZIP libraries, which can reduce Blob size by a third or more. Compression is enabled in the DeflateStreams settings by default, but it is also possible to disable it from Dynamic System Settings if you want to.
3. Encryption
Blob encryption is not enabled by default, but you can do so by using a platform or custom cipher. I've created a How-to document in a separate article. Please see https://support.pega.com/discussion/database-encryption.
The advantages of using Blob are the following:
- Compressed Blob lowers storage overhead
- No size constraint
- Ease of managing complex / Nested structures
- Doesn't need DBA to make complex changes to the database schema
- Fast single-object access
- Allows object model to evolve
- "Only needed" columns are mapped relationally, eliminates need for large amount of SQL construction
- Delivers agility
At the early stage of a project, developers are more focused on business requirement in DCO and initial data structure design may change as you get a bigger picture of application architecture. UDF supports developers' fast development without having to pay much attention to the physical database layer. It is more efficient to optimize the properties once application framework gets solid in the later phase.
3. What is UDF?
Starting in PRPC6.2 SP2, we have introduced a set of UDFs (User-Defined Functions), a.k.a. "Blob reader" or "DirectStreamReader", to provide functionality to retrieve scalar property values directly from Blob in the database. This feature is only available for use in Report Definition. There are three UDFs installed in the database:
(1) pr_read_from_stream
(2) pr_read_int_from_stream
(3) pr_read_decimal_from_stream

These functions are identical, except for the data type of the value returned (String, Int, Decimal). They are installed in both the rules and data schemas. The UDFs are defined and loaded differently in each of our four supported databases. They are implemented using Java on Oracle, PostgreSQL, and DB2 LUW/ZOS, and using C# on Microsoft SQL Server. These are the first UDFs we ship, and this is our first time running Java (to say nothing of C#) in the database.
4. How to use UDF
4-1. Prerequisites
To install UDF, Java must be enabled on the database for Oracle, PostgreSQL, and DB2. For Microsoft SQL Server, CLR (Common Language Runtime) must be enabled.
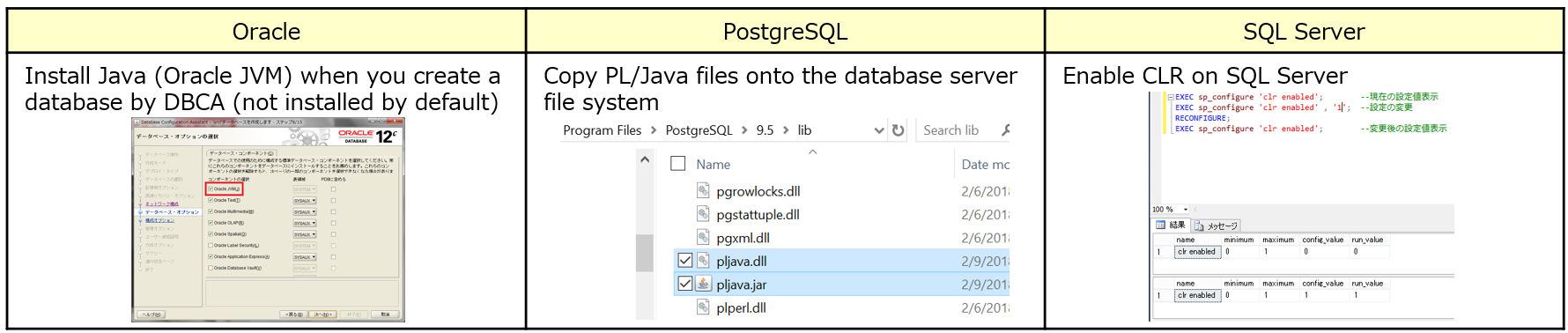
4-2. Installation
It is installed automatically as part of the standard installation and upgrade processes. If you do not want to install UDF, you need to edit setupDatabase.properties in the ./scripts directory of the distribution media. The default value is blank, which is interpreted as false and UDF is installed. Set it to true to bypass UDF installation. This file is applied not only for command-line installation but also GUI (IUA) installation. UDF is not mandatory to install and all other functionalities work completely fine without UDF. If you have any issues with UDF installation on Windows / PostgreSQL 11+, please see https://support.pega.com/discussion/how-set-sqlj-schema-udf-postgresql-11-windows.

* Update
From Pega 8.8 onwards, the default value is set to true. So, UDF is not installed by default and there is no need to modify the file to skip UDF installation.

4-3. Parameters for UDF
- ref: a property reference indicating the scalar property to return. The property specification must start with a "." (period).
- insKey: the handle (pzInsKey) of the instance whose value you wish to obtain, or NULL.
- stream: the Blob column name (pzPVStream).
4-3. Sample Query using UDF
SQL> select my_schema.pr_read_from_stream('.SomeProperty', pzInsKey, pzPVStream)
from {Class: MyCo-Task}
where pxObjClass = 'MyCo-Task';You can run the following sample query to check if three UDFs are working or not.
5. What is optimization?
Optimization is to expose a property as a dedicated database column. This eliminates the need to extract data from Blob by UDF and you can significantly improve reporting performance. Technically speaking, it might slow insert and update operations, so make sure you optimize the only properties that are used in the Report Definition (do not optimize unnecessary ones). Also, be noted that you can't optimize properties in classes mapped to pr_others table.
There are two patterns in optimization – Single Value property and Page List property. If you optimize a Single Value property, the column is simply added in the same table. If you optimize a property in Page List property, a new Index table is created and the column is added in there. Please see below for the sample image.

In Dev, optimization is typically done by optimization wizard from Dev Studio. In Prod, if you are on Pega 8+, importing R-A-P takes care of it. The details are explained in the next #6 and #7.
6. How to optimize a property in Dev
6-1. Optimization wizard
You can simply right-click the property and launch optimization wizard from Dev Studio. Below is for Single Value property, but the process is the same for Page List property as well.
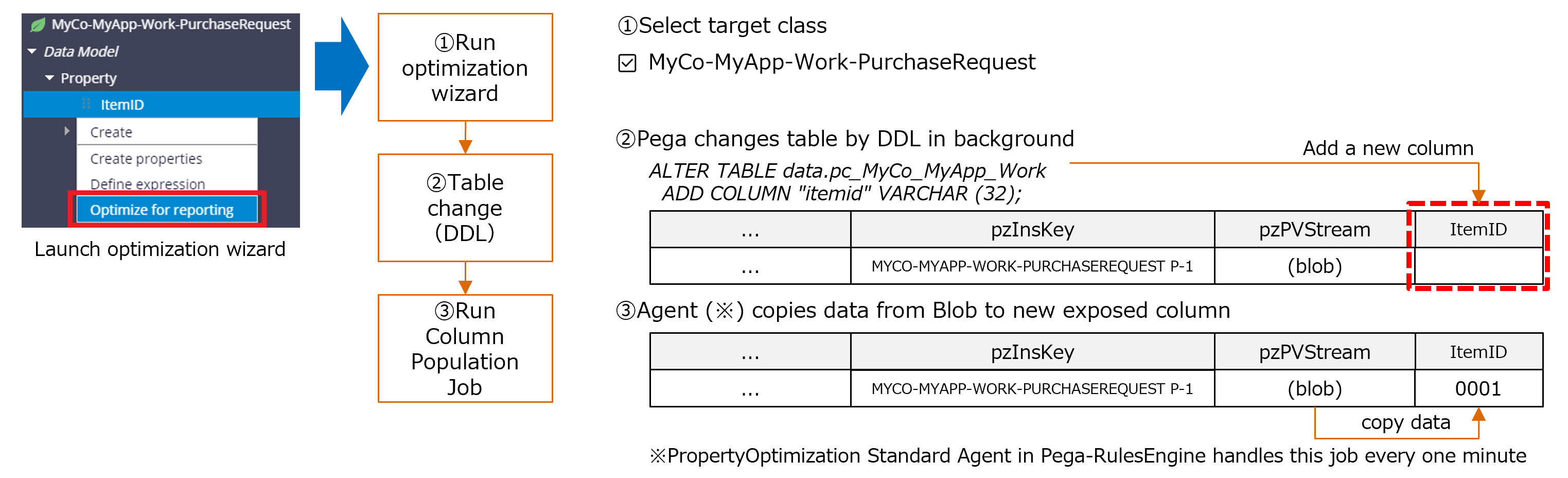
6-2. Prerequisites for optimization wizard
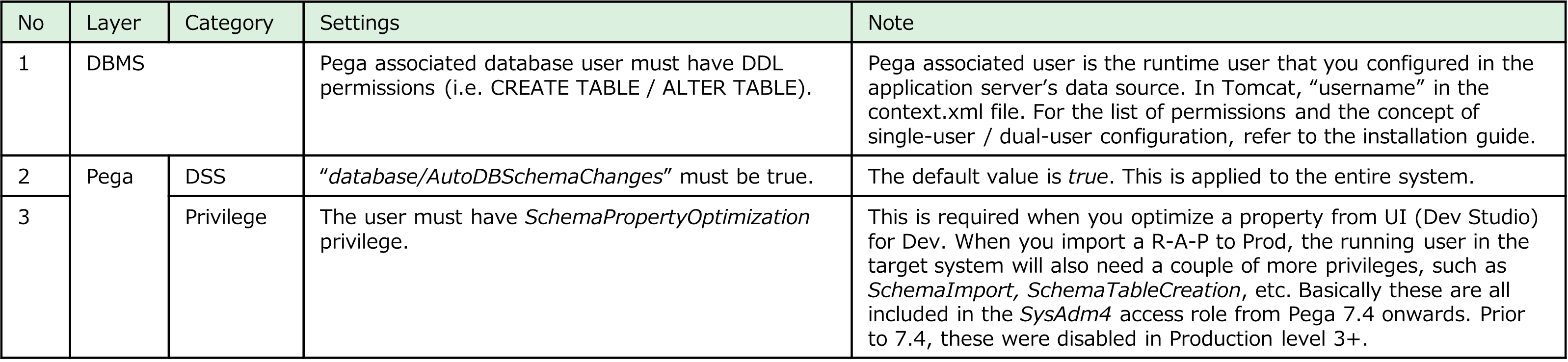
There are a couple of prerequisites for developer to be able to use optimization wizard in Dev Studio.
7. How to optimize a property in Prod
I have created a separate article for this topic. Please see https://support.pega.com/discussion/how-optimize-properties-production-environment.
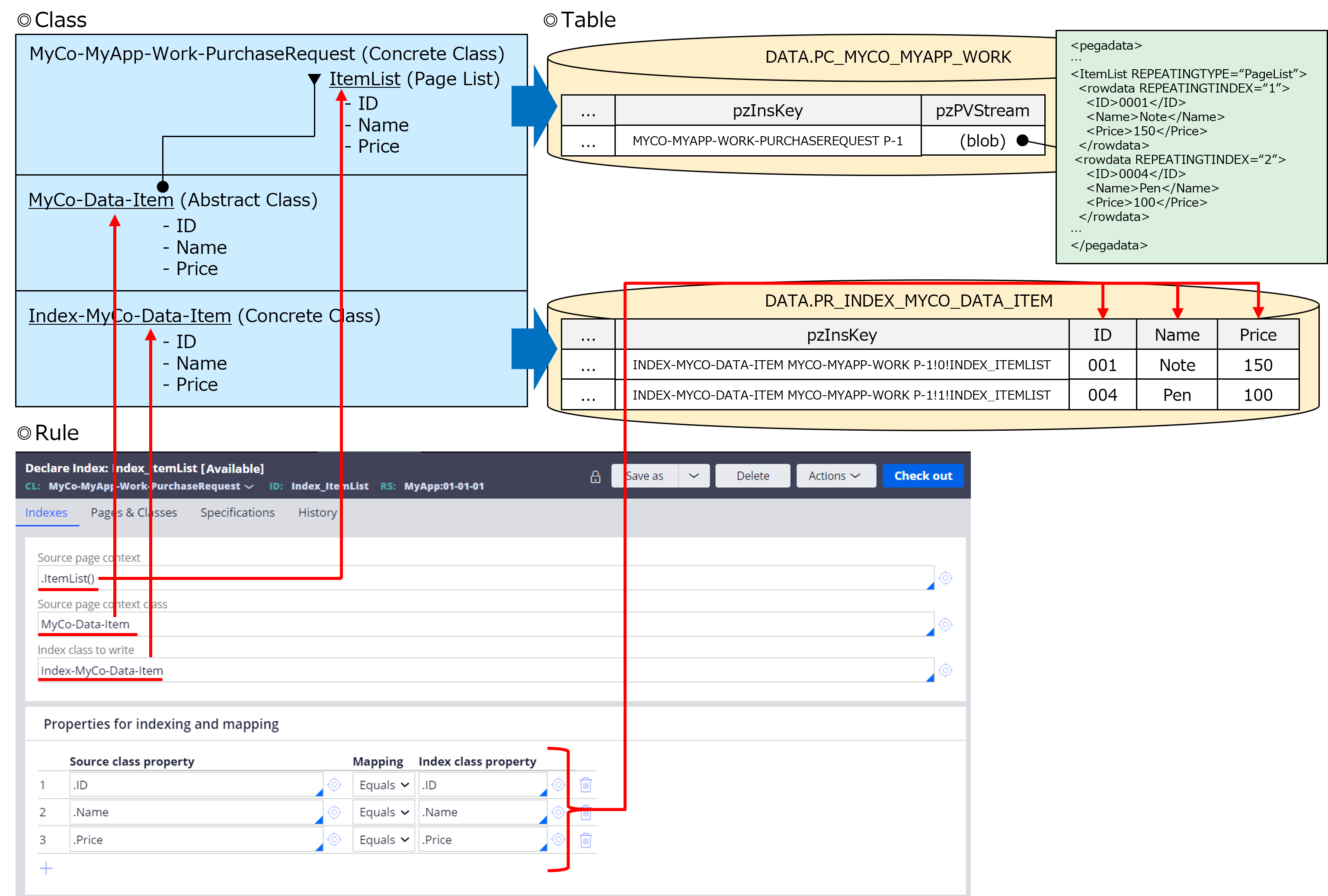
8. Declare Index
When you optimize properties in Page List property, system creates Declare Index rule and some more objects. For your reference, below are the artifacts created for PurchaseRequest sample application earlier.
(1) Declare Index rule: "Index_ItemList"
(2) Index class: "Index-MyCo-Data-Item"
(3) Property rule in Index class: "ID", "Name", and "Price"
(4) Physical table in the database: "PR_INDEX_MYCO_DATA_ITEM"
9. How to unoptimize a property
If you optimize a wrong property which you shouldn't have, or Report Definition requirement is gone and the property doesn't have to be optimized anymore, you may want to revert the optimization for clean-up.
9-1. Dev
9-1-1. Single Value property
The easiest way is to drop the column directly from DBMS, and restart the system (or resave Data-Admin-DB-Table instance). This approach works for all version. Be noted, unless you restart the system, you can't resave the work object (you'll get FATAL pyCommitError), nor can you re-optimize the same property.
9-1-2. Page List property
It is a bit more complex than Single Value property as there are more objects involved. If you want to remove one property and leave others, you can take the similar approach as Single Value property. If you want to remove all the properties and entire Declare Index, you can clean up all the artifacts system had created - in this particular example, all the properties in Index-MyCo-Data-Item class, Index-MyCo-Data-Item class (all the records have to be deleted in advance), physical database table, and Declare Index rule. In this case, system restart is not required as deleting Index-MyCo-Data-Item class will also delete Data-Admin-DB-Table instance and that makes engine know the changes. You can resave the work object or re-optimize the same Page List property right away.
9-2. Prod
If the property is already optimized in Prod and end users are using the application, the first question is whether the risk is worth taking. You have two options - one is to unoptimize it, and the other one is to just keep it as is. The disadvantage of keeping it is that insert and update operations might get slower. If it is just one or few properties, the overhead is probably negligible, but if there are many such properties, you may want to clean up the mess.
In case of optimization, importing Data-Admin-DB-Table instance propagates the optimization state from Dev to Prod. How about the reverse process, unoptimization? If we drop the column in Dev, create a product file and import it into Prod, will PRPC detect the table structure changes and run DDL (DROP COLUMN) to synchronize it? The answer is No, PRPC import process adds columns, but doesn't drop columns. So, for the Single Value property, take the same approach as Dev - drop column from DBMS directly and restart the system. For Page List property, if you want to remove all the properties and entire Declare Index, you can't physically delete these rules because Declare Index and property are rule instances and they are already locked in Prod. What you can do is, withdraw Declare Index rule (and also property rule) in Dev, and import R-A-P to Prod. Make sure new record doesn't get inserted into the Index table anymore.
10. UDF and performance
Probably you've already heard many times UDFs severely degrades the reporting performance, but how bad is it? It is different per version and DBMS type, but just to get a sense of it I have conducted a benchmark test on my local PC.
(1) Environment
- Hardware: Lenovo T460s laptop PC x 1
- Software: Pega Platform 7.4, Tomcat / PostgreSQL, Windows 10 Pro
- CPU: Intel® Core™ i7-6600U CPU @ 2.60GHz
- RAM: 20GB (heap size is 16GB)
(2) Scenario
- Read a single property by Report Definition. Measure elapsed time before and after optimization (UDF vs non-UDF).
(3) Number of rows
- 4 patterns - 1,000, 10,000, 100,000, and 1,000,000
Retrieving a single property value from 1,000,000 rows with UDF takes 114.719 secs while the same query against optimized property without UDF takes 1.789 secs. 114.719 / 1.789 makes more than 60 times differences. Please take this as my personal reference, not Pegasystems official one.
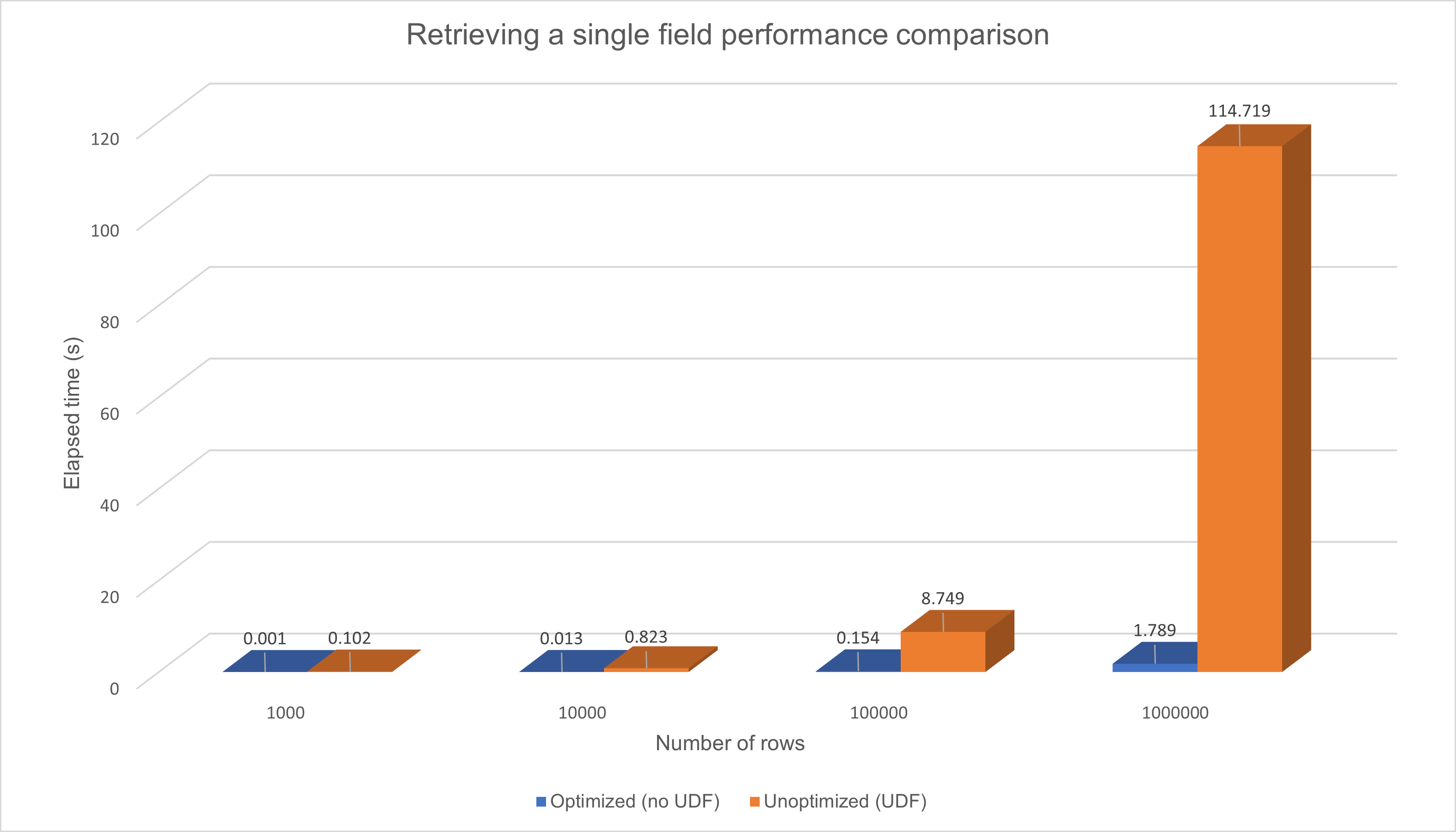
With simple queries, using the UDF to extract a property from the Blob on the database is :
- about 25% shorter in elapsed time than returning the entire Blob to the app server
- about 60 times slower in elapsed time than reading an exposed column
11. How to eliminate unoptimized Report Definitions
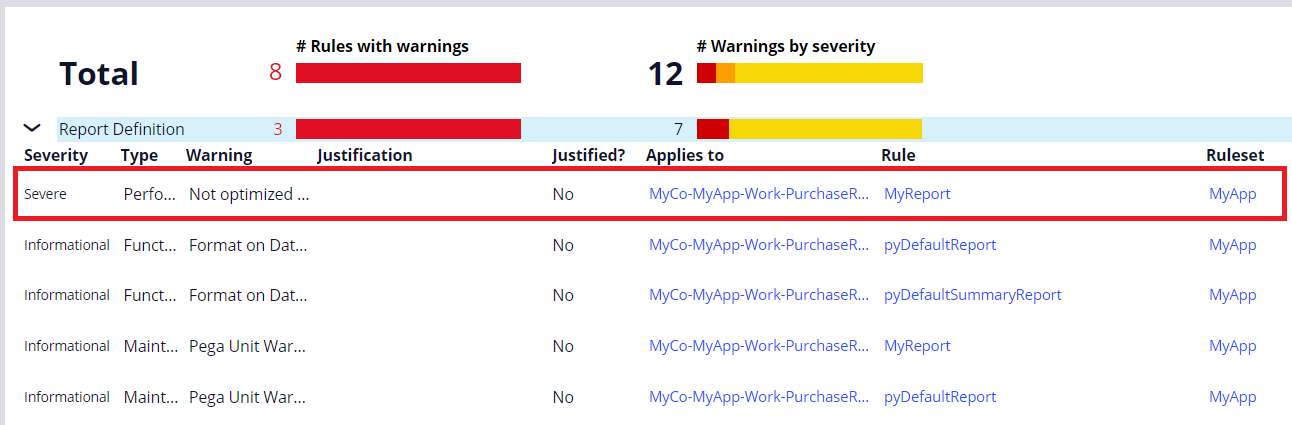
Now we understand that all the properties in the Report Definition should be optimized. However, the property rule form doesn't tell us whether it's optimized or not. How can we make sure we have no such Report Definitions?
The easiest way would be to check Guardrails. Referencing unoptimized properties is Severe warning, and it comes on top. So you should be able to navigate to the problematic Report Definitions easily. If your environment doesn't have UDF installed, these reports will fail at runtime. Make sure you have zero such reports.
12. UDF support
12-1. Cloud
If you are on-premise, you have full control over your infrastructure and probably you don't have much issues with setting up UDF. If you are on cloud, since UDF is heavily tied to its environment, depending on the cloud type, UDF can or cannot be installed. For example, if you choose Amazon RDS, UDF can't be installed because Java is not supported (In PostgreSQL, you need to copy PL/Java files on to the database server's filesystem, but accessing to operating system is not allowed in RDS). The same restriction applies to other cloud vendors such as Microsoft Azure or Google Cloud Platform. On the other hand, if you are using Amazon EC2, you can install UDF because EC2 gives you the same level of flexibility as on-premise, and you can freely set up anything on your own. If you are on customer-managed cloud, check if Java is supported in their database.

12-2. PL/Java and PL/V8
As mentioned above, Amazon RDS does not support PL/Java, but Pega Cloud supports UDF. This is achieved by PL/V8, which is a JavaScript language extension for PostgreSQL powered by Google's V8 engine. UDF is specially rewritten by PL/V8 for non-Java environment. Unfortunately, the script is never provided to outside of Pega. PL/V8 is only used internally at Pega Cloud instances.
- Update (9/9/2022)
UDF is now deprecated from Pega 8.6 onwards. We have already removed UDF from the latest Pega Cloud instances. When you create a Report Definition, you need to optimize the properties. If it is difficult for any reason, Obj-Browse is another way to get values of unoptimized properties. For questions about how we will makes changes or further direction of a product, I am not the right person to answer. Please reach out to Pega representatives in your project.
Hope this helps.
Thanks,
Infosys Limited
IN
Thanks for providing the quality content. This is superb!!
I am having a couple of questions. Could you please address it?
How Pega handles the reports which have unoptimized properties without UDFs installation in the DB vendor in later versions (8.6 and above) as UDFs are no longer supported?
Does Pega restrict to saving of the report if any of the properties are not optimized in 8.6 and above?
Pegasystems Inc.
JP
We have deprecated UDF starting with 8.6, but as of today UDF is still included in the 8.6/8.7 distribution media and once installed, it works completely fine. As a matter of fact, 8.6/8.7 Personal Edition still comes with UDF. However we would ask all customers to stop installing it as UDFs are performance detractors and it will be removed in the future anyways.
There are no code level differences between 8.6/8.7 and prior versions yet, so you can still save a Report Definition including unoptimized properties. If UDF is not installed, the unoptimized Report Definition will fail at runtime.
Thanks,
Pegasystems Inc.
US
@KenshoTsuchihashi Obj-Browse does not support pagination. Exposing property is preferred vs Obj-Browse from performance perspective.
Pegasystems Inc.
JP
I agree that Obj-Browse method has performance issues, and thank you for raising an FDBK item to support pagination with Obj-Browse.
The reason I mentioned Obj-Browse is because, in certain situations it may be better to choose Obj-Browse approach over optimization approach. For example, my customer had a couple of dozen Job Scheduler rules in the system. In order to review each setting, they created a Report Definition in Rule-Async-JobScheduler class (Admin Studio has a similar interface but let's assume it is not enough). They want to retrieve 13 properties, but only 4 are optimized and 9 are not optimized by default (see below screenshot). The Report Definition was working before as they were on old Pega Cloud instance and UDF was installed. Now they migrated R-A-P to new Pega Cloud instance where UDF is not installed, and reporting started to fail at runtime.
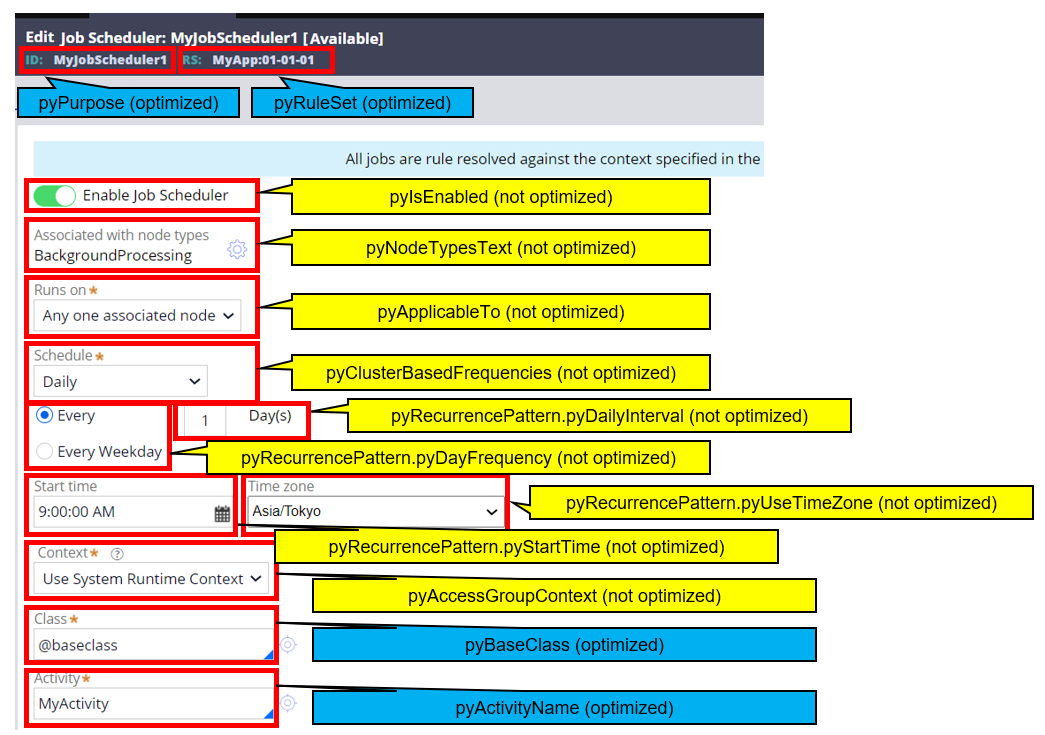
I agree that Obj-Browse method has performance issues, and thank you for raising an FDBK item to support pagination with Obj-Browse.
The reason I mentioned Obj-Browse is because, in certain situations it may be better to choose Obj-Browse approach over optimization approach. For example, my customer had a couple of dozen Job Scheduler rules in the system. In order to review each setting, they created a Report Definition in Rule-Async-JobScheduler class (Admin Studio has a similar interface but let's assume it is not enough). They want to retrieve 13 properties, but only 4 are optimized and 9 are not optimized by default (see below screenshot). The Report Definition was working before as they were on old Pega Cloud instance and UDF was installed. Now they migrated R-A-P to new Pega Cloud instance where UDF is not installed, and reporting started to fail at runtime.
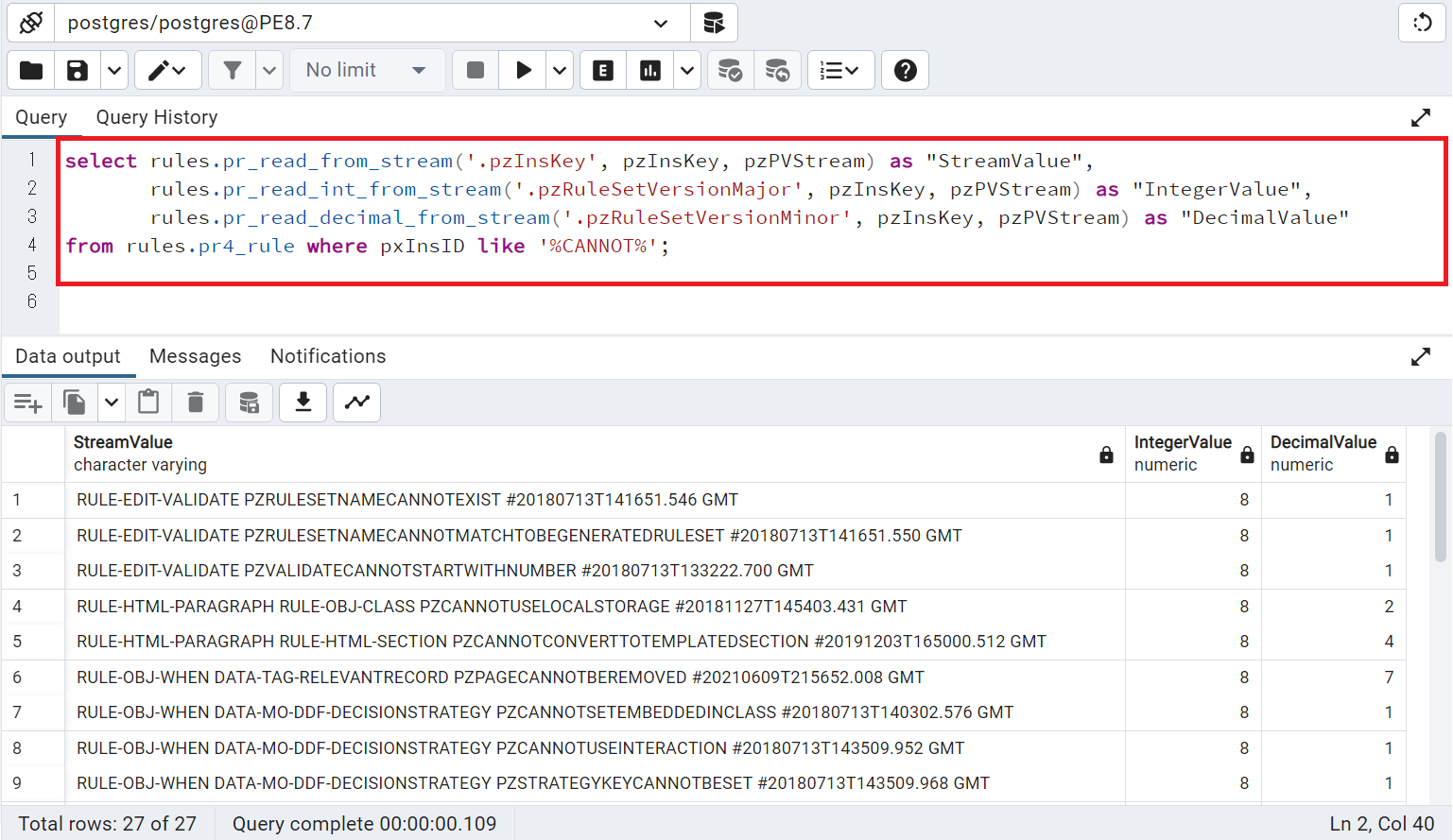
Now, the question is "Should we optimize 9 properties in rules.pr4_rule table for better performance?". Personally I don't feel like altering table structure in Rules schema. rules.pr4_rule is a common out-of-the-box table for many other Rule- derived class. Keeping the out-of-the-box state should reduce the risk in upgrade as well. In this case, I wouldn't mind Obj-Browsing a couple of dozen unoptimized records as performance impact is limited as a whole.
Thanks,
Updated: 7 Oct 2022 16:57 EDT
Pfizer Inc
US
@KenshoTsuchihashi Great article. Appreciate your time and effort in coming up with this. I've a quick question.
People have been using UDF in all lower environment and also in prod sometimes directly via database client to do some debugging. for example they may want to query few properties in the blob of a queued item (of an agent or a queue processor). We wouldn't want to expose those properties in the queue table but for debugging we use them a lot.
What do you recommend as an alternative in such scenarios? if UDF is not supported, we have lost a great standalone tool. isn't it? I understand it should be cautiously used. May be Pega should have upgraded the report definition rules NOT to support usage of UDFs but still support UDF in the database so people can run them independently using database client.
Pegasystems Inc.
JP
Thank you for your insightful feedback. I understand your concern, and I have also faced a number of similar situations with having to UDFs in the past. One is diagnostic / debugging scenario like yours. Another one is actual production used scenario - customer wants to have a view that browses information inside Blob (please see the Job Scheduler example posted one before yours). If it is a generated custom work or data type table (ex. pc_myco_myapp_work or pr_myco_myapp_data_customer), I wouldn't hesitate to just go ahead and expose whatever columns I need. However, if it is a pure out-of-the-box rules or data table, I would weigh the advantages and disadvantages. The trade-off is, for a better performance, customer may have a bit of concerns or worries that come from owning a physically different schema than product (i.e. are we really okay in the future upgrade? isn't it safer to be in sync with product as-is, etc).
Usually I would review how important the expose requirement is. For example, if the business requirement is trivial or short-term trial purpose, and if the number of rows in the table is limited (say, a couple of dozen) and we know that using UDF won't affect performance for sure, I used to go for UDF solution. I made this decision on project basis considering many aspects, rather than uniformly going for expose solution.
Thank you for your insightful feedback. I understand your concern, and I have also faced a number of similar situations with having to UDFs in the past. One is diagnostic / debugging scenario like yours. Another one is actual production used scenario - customer wants to have a view that browses information inside Blob (please see the Job Scheduler example posted one before yours). If it is a generated custom work or data type table (ex. pc_myco_myapp_work or pr_myco_myapp_data_customer), I wouldn't hesitate to just go ahead and expose whatever columns I need. However, if it is a pure out-of-the-box rules or data table, I would weigh the advantages and disadvantages. The trade-off is, for a better performance, customer may have a bit of concerns or worries that come from owning a physically different schema than product (i.e. are we really okay in the future upgrade? isn't it safer to be in sync with product as-is, etc).
Usually I would review how important the expose requirement is. For example, if the business requirement is trivial or short-term trial purpose, and if the number of rows in the table is limited (say, a couple of dozen) and we know that using UDF won't affect performance for sure, I used to go for UDF solution. I made this decision on project basis considering many aspects, rather than uniformly going for expose solution.
As of today, how we may change the specification of Report Definition or what kind of alternatives to UDF we may provide is unknown and it is under discussion. Until then, if your environment has UDF installed, you could continue your current approach (UDF is still fully functional for now), or as I stated in the original post, you could also Obj-Browse in an activity to retrieve unoptimized field and check the clipboard. Performance is not great, but if it's under your control, it is okay anyways.
@petejo @GabeEdwards @szadp
If there is anything to add, please make a comment.
Thanks,
Updated: 15 Feb 2023 18:25 EST
WIPRO
IN
@KenshoTsuchihashi Wonderful article! Thanks a lot for this.
I have a question on exposing properties. I often get lot of real-time reporting requirements where we are forced to expose more columns to fulfil the requirement. Once we start exposing, non-technical business users keep coming up with similar requirement, then we expose, column populate etc. Though exposing more properties is not a best practice, only alternative I know is to use BIX. BIX option does not work as it will run the job overnight and it wont show the data real-time. Is there a better approach to handle this?
Tata Consultancy Services
IN
I have a small doubt, Optimization is to expose a property as a dedicated database column, it means that exposed property data will not store into the "pzPVStream" and it will store only DB Table?
or it will store in both places DB table and BLOB(pzPVStream)?
Thanks,
Ashok
Pegasystems Inc.
JP
Data is stored at both Blob (pzPVStream column) and exposed column. If you update data in exposed column by SQL directly from DBMS, which you should never do against Blob table, at first glance Report Definition may look like it's working, but if you open the work object and hit "Save" button, data in Blob will overwrite this "fake" data in exposed column and data is rollback. In that sense, I would say Blob is more legitimate while exposed column is superficial for performance purposes (Report Definition looks for exposed column).
Thanks,
Updated: 25 Jul 2023 7:13 EDT
Tata Consultancy Services
IN
Thank you so much.
If we update the value in directly into the DB, we can able to see new value while fetching data by using the Report definition.
If open the respective work object and open the ClipBoard it will shows the Blob data only. It's completely misleading the data. It means that in both places data will be different.(Report definition data and Clipboard data).
If we will update same work object from the Pega UI/Work Object Edit option, It will overwrite the data (manually updated data) into the exposed column data in DB, Why it is not happened vice versa.
If it is not happened vice versa. It's completely misleading the data. What would you suggest??
Could you please help me on this? How do I delete some property data in bulk in pzPVStream? @KenshoTsuchihashi
Note: It means that pyWorkPage always fetches or reads data from the Blob(pzPVStream column); is that the correct statement?
I am waiting for your valuable feedback.
Thanks,
Ashok
Updated: 17 Oct 2023 9:38 EDT
Rabobank
NL
@Bhumireddy Please find my answer inline below
If we will update same work object from the Pega UI/Work Object Edit option, It will overwrite the data (manually updated data) into the exposed column data in DB, Why it is not happened vice versa......................Because when you write DB sql to update the DB table data, it is a DB operation and from DB it is not possible to open the blob (only read option is possible through UDF function) and edit the blob data. If that is allowed then anyone who has DB access can update the blob from anywhere (means with any external application) and then it may impact the whole pega application functionality. Also it is not allowed due to security reasons. That is why Blob is owned by Pega and can be edit only through Pega operation or methods (i.e. through Obj-Save or OOTB activity ).
Could you please help me on this? How do I delete some property data in bulk in pzPVStream?........There are two option
1. Through Job Schedule means write a batch process and loop against all the work objects and update its properties and save the instance. You can also use Queue processor along with Job scheduler to make the process faster.
@Bhumireddy Please find my answer inline below
If we will update same work object from the Pega UI/Work Object Edit option, It will overwrite the data (manually updated data) into the exposed column data in DB, Why it is not happened vice versa......................Because when you write DB sql to update the DB table data, it is a DB operation and from DB it is not possible to open the blob (only read option is possible through UDF function) and edit the blob data. If that is allowed then anyone who has DB access can update the blob from anywhere (means with any external application) and then it may impact the whole pega application functionality. Also it is not allowed due to security reasons. That is why Blob is owned by Pega and can be edit only through Pega operation or methods (i.e. through Obj-Save or OOTB activity ).
Could you please help me on this? How do I delete some property data in bulk in pzPVStream?........There are two option
1. Through Job Schedule means write a batch process and loop against all the work objects and update its properties and save the instance. You can also use Queue processor along with Job scheduler to make the process faster.
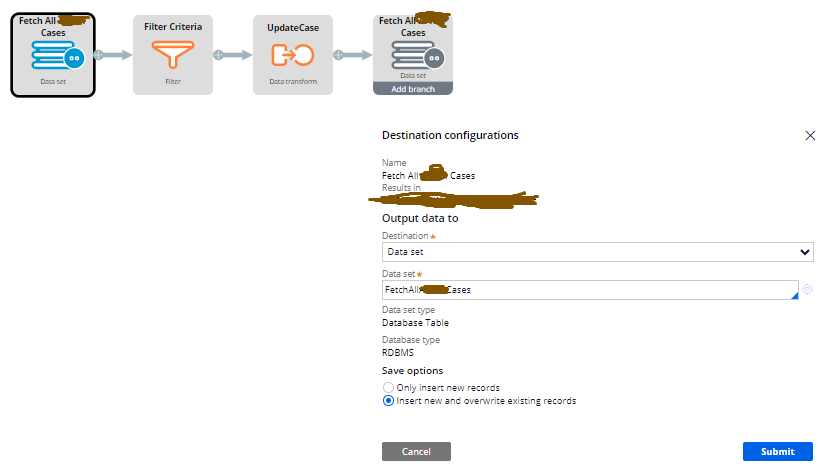
2. Use of Data flow and Data set:- Create a dataset for all those cases where you need to update the properties. And use this data set in the dataflow , where you need to add a data transform (for deleting the property data) and save the data set record. See the screenshot below for more clarity. You can also use filter shape to filter the record. Note:- Dataflow manage opening, locking and saving of work objects instances internally so that is good to use as compare with activities. Also it is faster than activities processing.
Note: It means that pyWorkPage always fetches or reads data from the Blob(pzPVStream column); is that the correct statement?...................Correct
Thanks
Varun