Discussion
Pegasystems Inc.
JP
Last activity: 8 May 2025 5:28 EDT
How to get the next auto-increment ID in Pega
Hi,
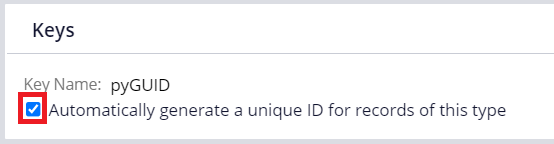
Since 7.3, Pega provides an out-of-the-box unique ID generation mechanism called pyGUID. This is handy because you only need to enable the checkbox on a Class form and system takes care of the unique ID generation for you. This ID is guaranteed to be unique, but it is a random string as below and not human-readable/usable.

Some customers may want the ID to be auto incremented so an ID is a little bit more human-meaningful. I have seen some developers have built such mechanism using DBMS Trigger manually, but in this post I am sharing much easier approach - instead of building everything from scratch, we can reuse an existing Case ID generation mechanism (https://collaborate.pega.com/discussion/case-id-generation-mechanism).
Unique ID generation is not only limited to Data Type use case, but anything. However, since Data Type is the most typical use case, in this example I will create an "Employee" Data Type and configure its ID to be automatically incremented by one as "EMP-1", "EMP-2", "EMP-3"... etc.
- Steps
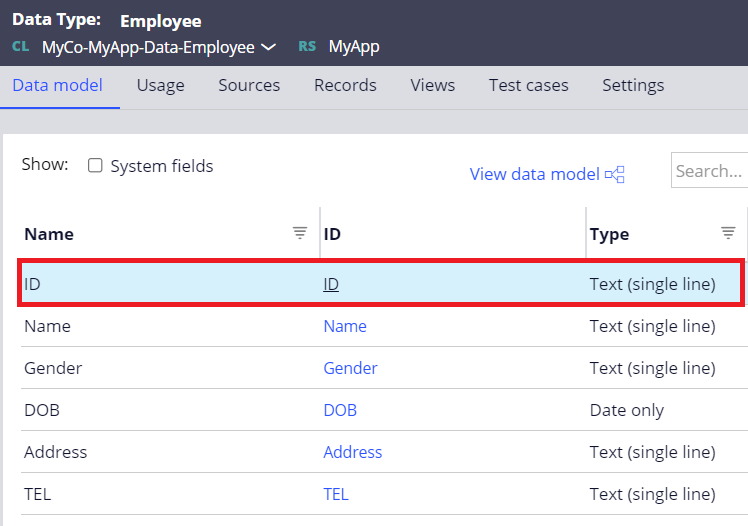
1. Define a Data Type and prepare a property for Primary Key. In this example, I have created an "ID".
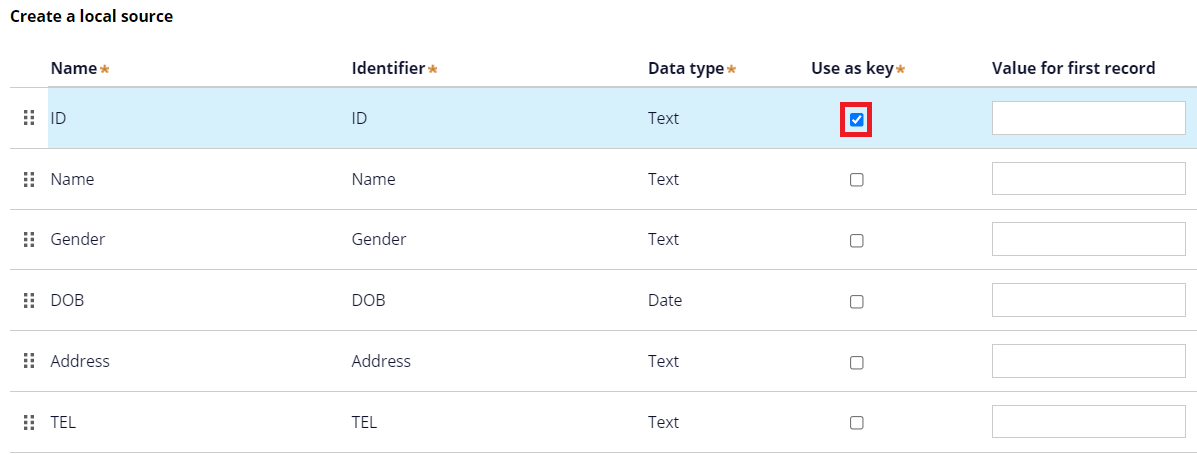
2. Create a local source. Set ID as a key.
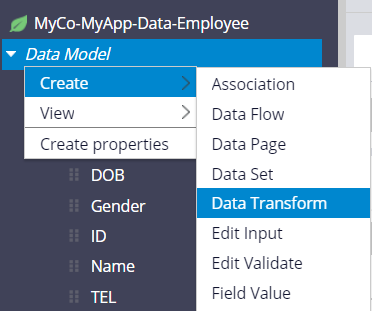
3. Create a Data Transform in the class of Data Type, called "pyDefault". In Pega, if you place a Data Transform named "pyDefault", it gets fired automatically when an instance is created. You don't have to explicitly call it yourself and it works like a constructor.
4. Set below RUF to ID in the "pyDefault" Data Transform.
@Utilities.pzGenerateUniqueID(tools, "EMP")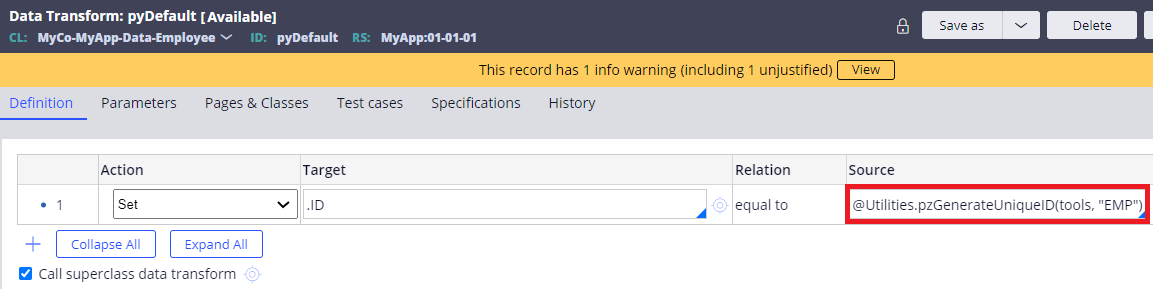
5. That's it. Now when you try to insert a record into Employee table, system will automatically generate an ID as "EMP-X", where X is a sequencial number starting from 1.

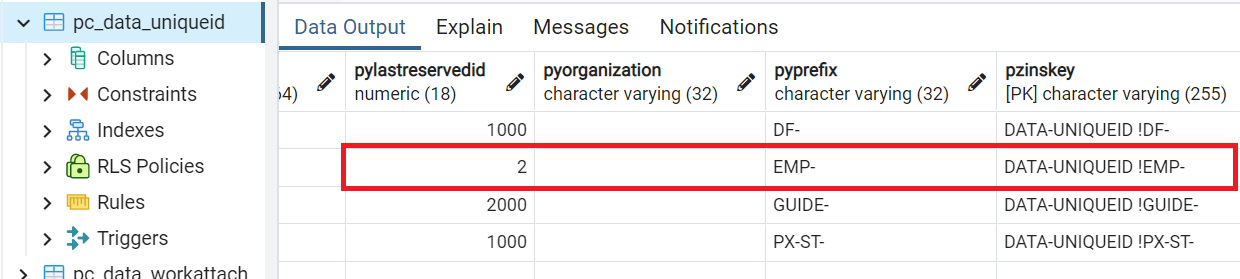
6. ID is automatically maintained in the data.pc_data_uniqueid table.
- Notes
If you do not want a prefix (ex. EMP-) and need only a sequencial number like 1, 2, 3..., here is how to to do it.
1. Locate an out-of-the-box pzGenerateUniqueID RUF in Utilities library.
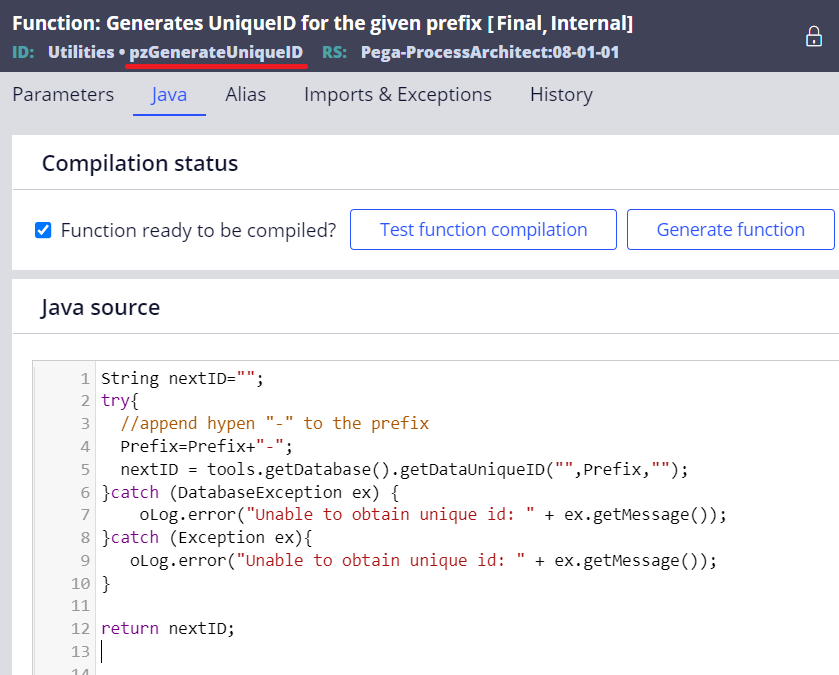
2. Do "Save As" in your ruleset and comment out line 4. This is the only modification needed. In this example, I renamed it "GenerateUniqueID" and put it into "MyLibrary" library.
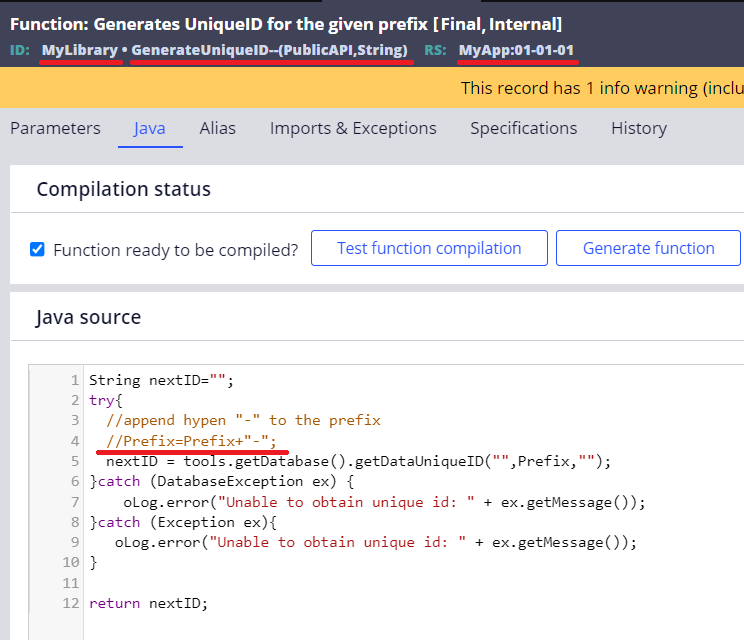
3. Update "pyDefault" Data Transform and call this RUF as below.
@MyLibrary.GenerateUniqueID(tools, "")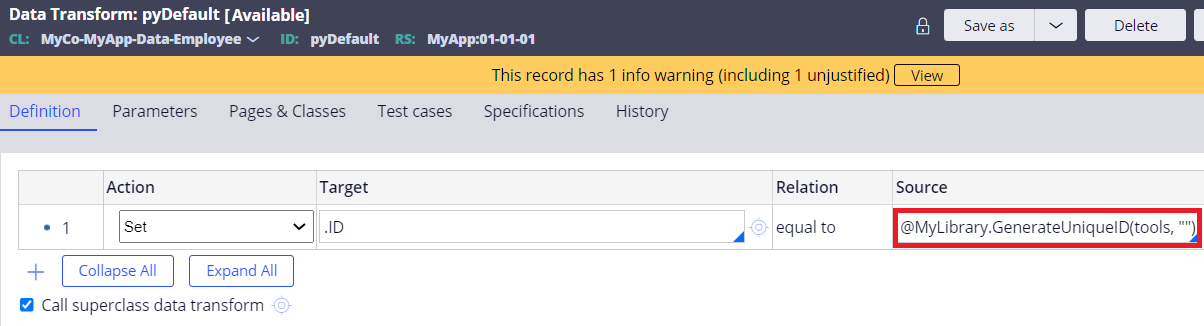
4. That's it. The generated ID will now be only number.

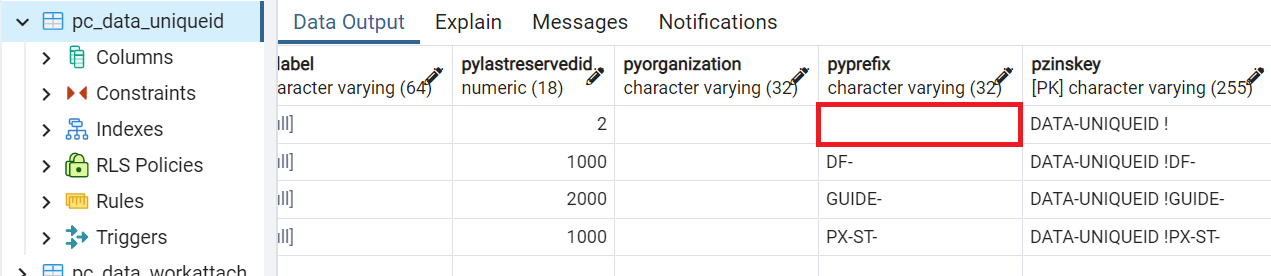
5. In this approach, data.pc_data_uniqueid table holds only a sequential number. pyPrefix property stays empty.
Hope this helps.
Thanks,
Updated: 30 Jun 2022 5:24 EDT
Ernst & Young LLP
IN
The explanation is very helpful and understanding thank you. I would like to know whether the batch numbers between two nodes which was explained for case ID creation will come into consideration while generating ID's for the Data types also or its not applicable in this scenario.
E.g. Numbers 1-1000 is reserved for app node 1 and numbers 1001-2000 is reserved for app node 2. The records created from app node 1 will increment as EMP-1,EMP-2..... and the records created from app node 2 will increment as EMP-1001,EMP-1002..... etc.
Thanks
Pegasystems Inc.
JP
No, the approach in this article with Data Type will always increase ID by one even if you log in to a different app node or restart system. For example, with the Dynamic System Settings being the default settings (idGenerator/defaultBatchSize=1000), if you log in to app node #1 and initially create two work objects (W-1 and W-2) and two data instances using this approach (EMP-1 and EMP-2). Then if you log in to app node #2 (or, you could restart app node #1 and log in to app node #1) and create two work objects and two data instances, then the ID will be W-1001, W-1002, and EMP-3, EMP-4. Batch size of 1000 is not applicable to data instances using this approach. Hope this clarifies your question.
Thanks,
Capgemini
ES
Is there a way to make use of Batch size (1000) for ID generation in data type?
Updated: 17 Nov 2022 11:11 EST
Pegasystems Inc.
JP
In my experience, there are no customers who requested this implementation, but I will show how to build it. In order to apply the batch size (default: 1000), you need to utilize getUniqueID Engine API, which is wrapped in the Work-.GenerateID activity. Since you can't call this activity from Data- derived class, first I have created a new activity in @baseclass, in this example I named it "GenerateMyID". Then copy the Java step from Work-.GenerateID and modified the first three lines as below.
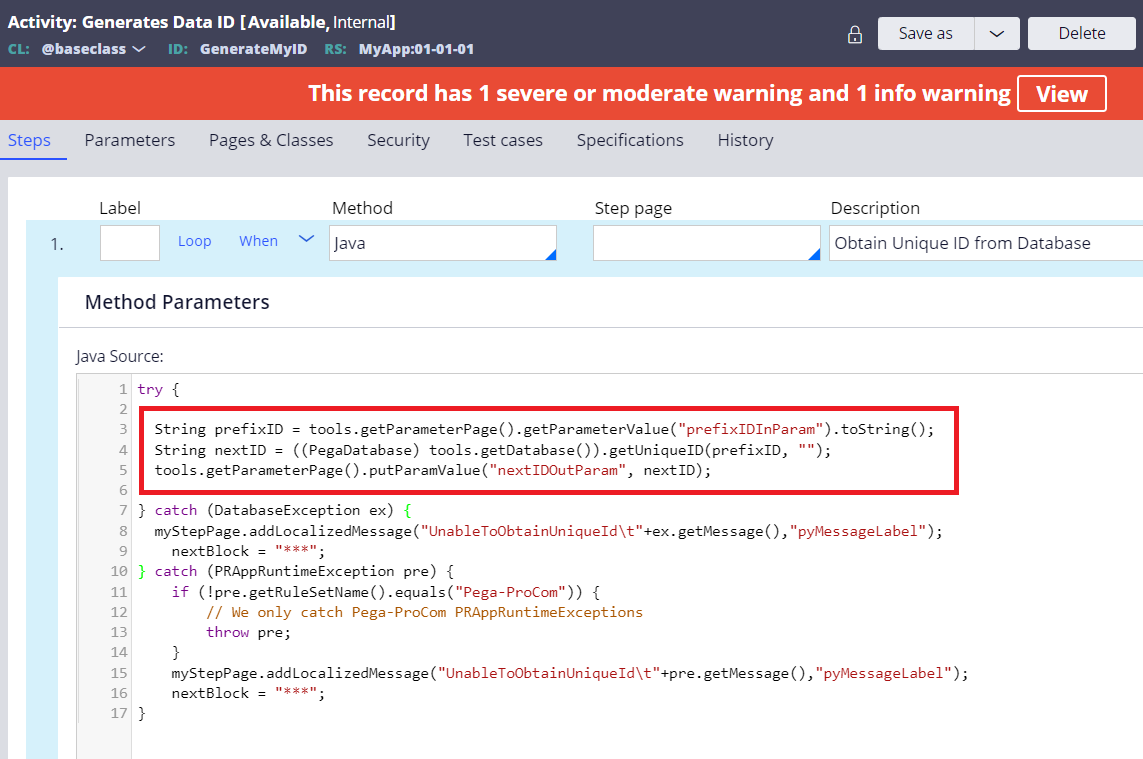
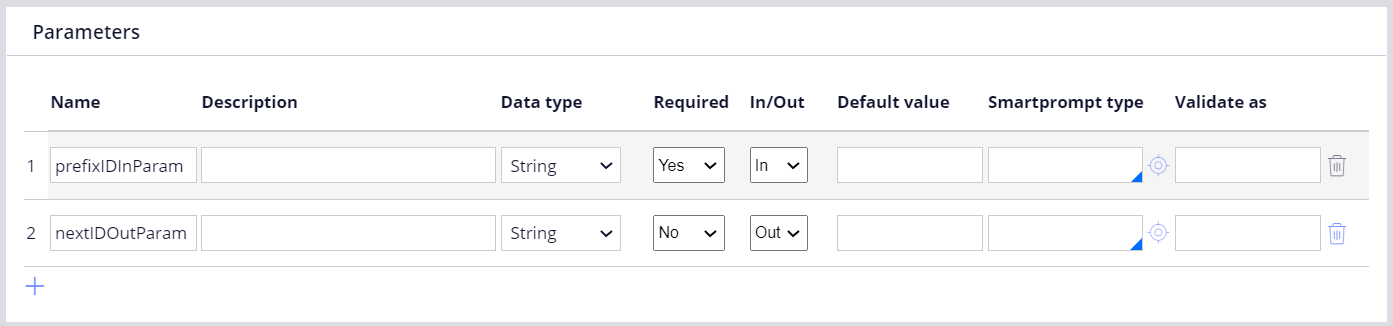
Next, modify "pyDefault" Data Transform in MyCo-MyApp-Data-Employee class as below. In the second step I am calling "GenerateMyID" activity using pxExecuteAnActivity RUF.
@Utilities.pxExecuteAnActivity(Primary, GenerateMyID)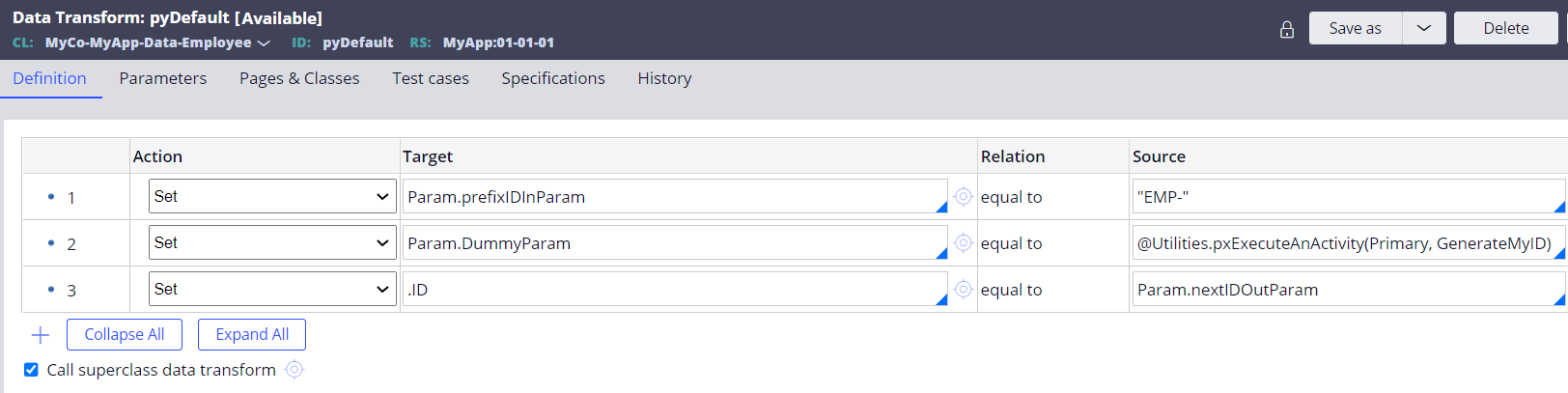
In my experience, there are no customers who requested this implementation, but I will show how to build it. In order to apply the batch size (default: 1000), you need to utilize getUniqueID Engine API, which is wrapped in the Work-.GenerateID activity. Since you can't call this activity from Data- derived class, first I have created a new activity in @baseclass, in this example I named it "GenerateMyID". Then copy the Java step from Work-.GenerateID and modified the first three lines as below.
Next, modify "pyDefault" Data Transform in MyCo-MyApp-Data-Employee class as below. In the second step I am calling "GenerateMyID" activity using pxExecuteAnActivity RUF.
@Utilities.pxExecuteAnActivity(Primary, GenerateMyID)
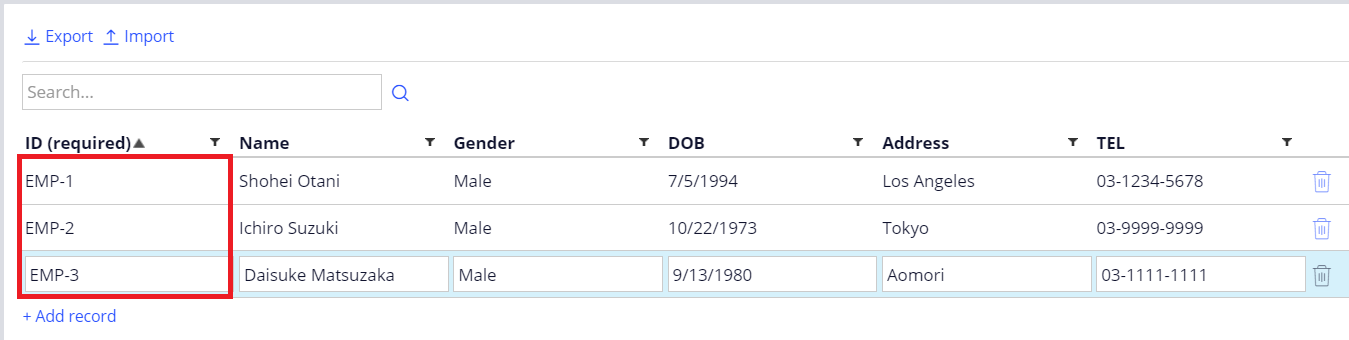
Now, test it. When I added rows in Employee Data Type, the ID starts with EMP-1, EMP-2, EMP-3, etc.
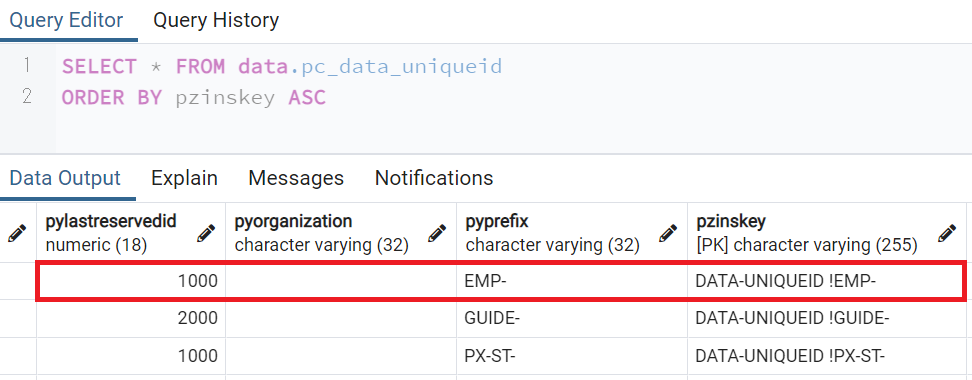
In the data.pc_data_uniqueid table, "1000" is inserted just like other work objects, not "3".
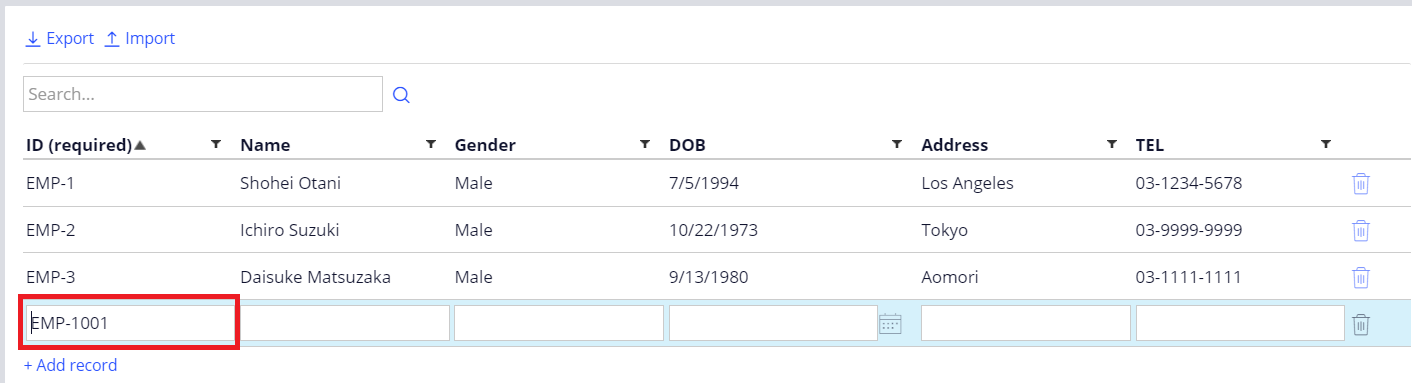
Now if you log in to app node #2 (or if you restart the app node) and add another Employee data instance, the next ID will be EMP-1001, not EMP-4.
Thanks,
TCS
US
@KenshoTsuchihashidoes it work on Thread level or Node level?
Citi
CA
@KenshoTsuchihashi Great explanation and very easy to understand. Also went through the Case ID generation post. Really helpful.
Evonsys
IN
@KenshoTsuchihashi Can this method be used to generate ids for bulk upload/load of data instances via Import utility or data flow?Will generation of id using this method have any adverse impact on table lock when data load is happening from two different nodes.
Pegasystems Inc.
JP
@Sudipta SUR
I've done a quick PoC in my local environment to measure how long it takes to bulk load 1,000,000 records into Employee table using this auto-increment ID approach. Also, for comparison purposes, I have tested out-of-the-box pyGUID approach. Be noted, I used an activity and Data Flow is not tested at this time.
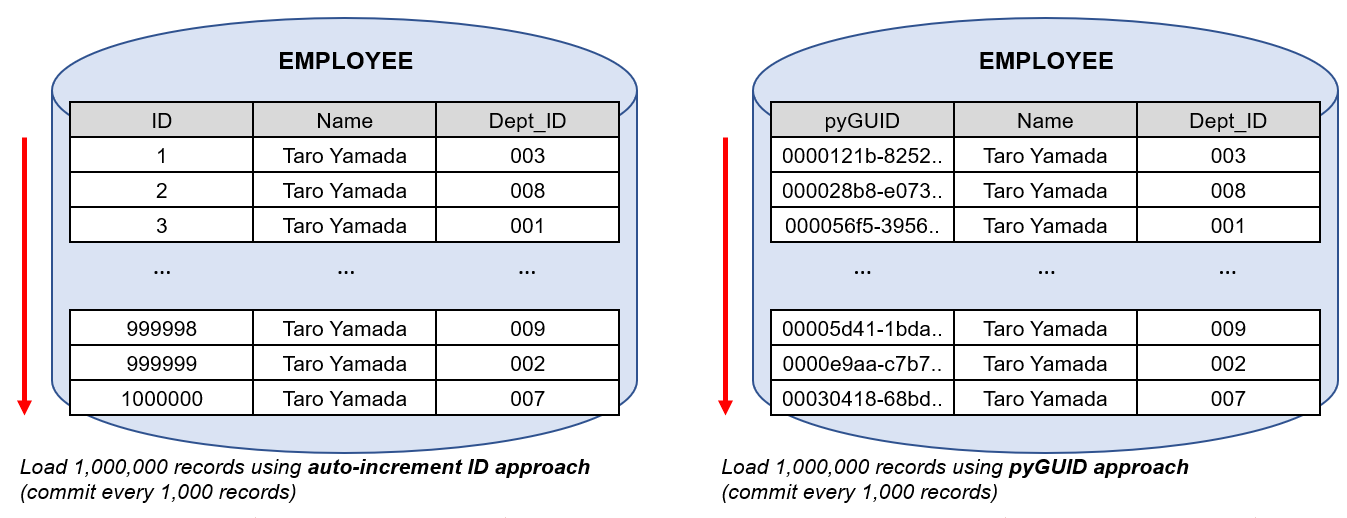
Test results:
- Auto-increment ID approach took 9mins 19seconds (0.000559 seconds per record).
- pyGUID approach took 3mins 32seconds (0.000212 seconds per record).
As you can see, pyGUID approach was faster. With that said, I don't think the auto-increment ID approach is too slow for production purpose. I have also run this bulk load activity from three different requestors at the same time, but system loaded 3,000,000 records without any issue.
Thanks,
Evonsys
IN
@KenshoTsuchihashi Thanks for the update on POC. We implemented pyGUID approach in our application
Ford motors India
IN
When i import an excel via import button of record editor with empty value for ID in excel, ID is not generated automatically, and import fails saying key is not there.
Even pxCreateRecord is not calling pyDefault data transform, so records are not inserted.
Please help.
hcl
IN
@KenshoTsuchihashi How to Locate an out-of-the-box pzGenerateUniqueID RUF in Utilities library? what is the navigation for utilities libraries in dev studio?
Updated: 6 Oct 2022 1:09 EDT
Pegasystems Inc.
JP
In general, when you are looking for rules, use full-text search at the top right corner in Dev Studio.

If it is not found, try enabling Diagnostics from preferences.

If it is still not found for any reasons, find it from the Records Explorer. This is searching from the database, not index.
Thanks,
HCL
NL
@KenshoTsuchihashi: Thank you so much for the detailed explanation, very understandable and helpful
EPA
AU
When we want to generate incremental ID without prefix for a given data type, it might work if we have one single table. However, if we want to sequential ID for multiple data types. Is this feasible? I see that data.pc_data_uniqueid doesn't associate it with any data type.
CIGNA
US
noticed the same
@GenerateID("Emp") -----------------------------------gives you a unique random
@Utilities.pzGenerateUniqueID(tools,"EMP")----gives you an incremental , if you have 2 tables , each data type will have diff numbers.
@MyLibrary.GenerateUniqueID(tools, "")--gives you the numeric incremental but same doesnt work accross different data types
TCS
US
@KenshoTsuchihashi
Thanks for nicely explaining the concept.
We are using 4 Nodes/ 32 threads running together. We are seeing the issue in logs "Cannot obtain a lock on instance <unknown>, as Requestor <unknown> already has the lock". Could multiple threads generating same ID be a potential issue?
TIA
HCL
NL
@KenshoTsuchihashi Hi Kensho, Thanks for the article, I have a question this integer id generation has a catch , I have a requirment where for multiple tables I need to maintain simple integer starting from 1 incrementally but as per the given appraoch the pzinskey of Pc_DataUniqueID table we have only 1 instance with no prefix key , because of this, always the 2nd table ID is generating incremental from the pyLastreservedID of the earlier table.
For example , Table 1 , ID s are 1,2,3, pyLastreserved ID= 3
For table 2, I need to create the same fashin of IDs with an intent that thistable records starts with 1,2,3, but the value starts from 4, how to fix this.
Pegasystems Inc.
SE
@JBRaghuraamm This is the expected and frankly preferred behavior. The purpose of pc_data_uniqueid table is to hold exactly that, unique id's. So it is actually a feature to make sure sequencing remains correct regardless from which place you call it, in your case 2 data types. So if you want to keep a sequencing number without prefix but have it differentiated between the 2 data types/tables, I would say that this is not a native scenario of the pc_data_uniqueid table. With that said, I do see the convenience of using the unique id features already available instead of writing your own implemenation.
So, I would say - First choice would be to use a prefix. If you really can't, then perhaps you can call @Utilities.pzGenerateUniqueID(tools, "XXX") with a unique prefix per data type/table, and then remove the prefix before inserting the record in the table. That way, your 2 tables would have unique distinctions in the pc_data_uniqueid table, but in your data type, a plain sequencing would be kept.
Wells Fargo
IN
@KenshoTsuchihashi when i tried to create a new record through activity, pydefault data transform is not getting called. Is this applicable while adding records through data designer.