Convert Docx (Word document) to PDF in 8.1 and above
Hi All,
in 8.4 we have a new Case step to Generate Documents based on a word template. If you want to convert that word document to PDF we have to add the following Jars in to the platform
Docx4j jar was updated in 8.X from 3.3.0 to 6.1.1 because of this Docx4J.toPDF will not work the way it used to work in previous version. To make it work we need to add following jars.
Add this dependency https://mvnrepository.com/artifact/org.docx4j/docx4j-export-fo/8.1.6 docx4j-export-fo in to platform along with its transitive dependencies.
Transitive dependencies required for docx4j-export-fo:
| antlr-2.7.7.jar |
| antlr-runtime-3.5.2.jar |
| avalon-framework-api-4.3.1.jar |
| avalon-framework-impl-4.3.1.jar |
| batik-anim-1.10.jar |
| batik-awt-util-1.10.jar |
| batik-bridge-1.10.jar |
| batik-constants-1.10.jar |
| batik-css-1.10.jar |
| batik-dom-1.10.jar |
| batik-ext-1.10.jar |
| batik-extension-1.10.jar |
| batik-gvt-1.10.jar |
| batik-i18n-1.10.jar |
| batik-parser-1.10.jar |
| batik-script-1.10.jar |
| batik-svg-dom-1.10.jar |
| batik-svggen-1.10.jar |
| batik-transcoder-1.10.jar |
| batik-util-1.10.jar |
| batik-xml-1.10.jar |
| checker-qual-2.8.1.jar |
| commons-codec-1.12.jar |
| commons-compress-1.18.jar |
| commons-io-2.6.jar |
| commons-lang3-3.9.jar |
| docx4j-core-8.1.6.jar |
| docx4j-export-fo-8.1.6.jar |
| docx4j-openxml-objects-8.1.6.jar |
| docx4j-openxml-objects-pml-8.1.6.jar |
| docx4j-openxml-objects-sml-8.1.6.jar |
| error_prone_annotations-2.3.3.jar |
| fontbox-2.0.7.jar |
| fop-2.3.jar |
| httpclient-4.5.8.jar |
| httpcore-4.4.11.jar |
| jackson-annotations-2.9.0.jar |
| jackson-core-2.9.9.jar |
| jackson-databind-2.9.9.jar |
| jakarta.activation-api-1.2.1.jar |
| jakarta.xml.bind-api-2.3.2.jar |
| jaxb-svg11-1.0.2.jar |
| jcl-over-slf4j-1.7.26.jar |
| libs.txt |
| mbassador-1.3.2.jar |
| slf4j-api-1.7.26.jar |
| stringtemplate-3.2.1.jar |
| wmf2svg-0.9.8.jar |
| xalan-interpretive-8.0.0.jar |
| xalan-metainf-8.0.0.jar |
| xalan-serializer-8.0.0.jar |
| xmlgraphics-commons-2.3.jar |
Sample code to convert an inputstream of docx to a pdf
InputStream is = new FileInputStream("sample.docx");
WordprocessingMLPackage pack = WordprocessingMLPackage.load(is);
pack.getMainDocumentPart().addParagraphOfText("Sample text");
OutputStream os = new FileOutputStream("tes.pdf");
Docx4J.toPDF(pack, os);
***Edited by Moderator Marissa to add the Developer Knowledge Share tag***
Virtusa
US
How to get the other dependencies for docx4j-export-fo; Is there any specific URL to download the below.
| antlr-2.7.7.jar |
| antlr-runtime-3.5.2.jar |
| avalon-framework-api-4.3.1.jar |
| avalon-framework-impl-4.3.1.jar |
| batik-anim-1.10.jar |
| batik-awt-util-1.10.jar |
| batik-bridge-1.10.jar |
| batik-constants-1.10.jar |
| batik-css-1.10.jar |
| batik-dom-1.10.jar |
| batik-ext-1.10.jar |
| batik-extension-1.10.jar |
| batik-gvt-1.10.jar |
| batik-i18n-1.10.jar |
| batik-parser-1.10.jar |
| batik-script-1.10.jar |
| batik-svg-dom-1.10.jar |
| batik-svggen-1.10.jar |
| batik-transcoder-1.10.jar |
Swedbank AB
SE
Hi,
We are using Pega 8.4. We have imported the jars mentioned above, but still getting following error. Can you please tell us how did you fix the following issue.
Caused by: java.lang.NoSuchMethodError: org.docx4j.convert.out.FOSettings.getOpcPackage()Lorg/docx4j/openpackaging/packages/OpcPackage;
at org.docx4j.convert.out.fo.renderers.FORendererApacheFOP.setupApacheFopConfiguration(FORendererApacheFOP.java:200) ~[docx4j-export-fo-8.2.1.jar:?]
at org.docx4j.convert.out.fo.renderers.FORendererApacheFOP.render(FORendererApacheFOP.java:112) ~[docx4j-export-fo-8.2.1.jar:?]
at org.docx4j.convert.out.fo.AbstractFOExporter.postprocess(AbstractFOExporter.java:168) ~[docx4j-export-fo-8.2.1.jar:?]
at org.docx4j.convert.out.fo.AbstractFOExporter.postprocess(AbstractFOExporter.java:47) ~[docx4j-export-fo-8.2.1.jar:?]
at org.docx4j.convert.out.common.AbstractExporter.export(AbstractExporter.java:81) ~[docx4j-6.1.1.jar:?]
at org.docx4j.Docx4J.toFO(Docx4J.java:734) ~[docx4j-6.1.1.jar:?]
at org.docx4j.Docx4J.toPDF(Docx4J.java:749) ~[docx4j-6.1.1.jar:?]
Ernst & Young LLP
IN
Have imported all the reference jars that are mentioned but still the code is breaking after the first line.
try {
java.io.InputStream doc = new java.io.FileInputStream(new java.io.File("C:/PRPCPersonalEdition/temp/Sample.docx"));
tools.putParamValue("Check1","111"); org.docx4j.openpackaging.packages.WordprocessingMLPackage wordPackage = org.docx4j.openpackaging.packages.WordprocessingMLPackage.load(doc); tools.putParamValue("Check5","555"); java.io.OutputStream outDoc=new java.io.FileOutputStream(new java.io.File("C:/PRPCPersonalEdition/temp/test.pdf")); tools.putParamValue("Check2","222"); org.docx4j.Docx4J.toPDF(wordPackage, outDoc); tools.putParamValue("Check3","333"); } catch(Exception e){ tools.putParamValue("Check4","444"); } }
It is moving after first line to Catch block therefore Check1 and Check 4 are coming in Parameter page.
Updated: 20 Nov 2020 21:07 EST
CVS Health
US
Hi,
Initially I tried this approach but I didn't succeed in it. Then I changed to Plan B and started using Opensagres API and was successful as well.
For more details, check my LinkedIn post for all the list of 15 jar files to be used for this exercise.
Maven repository for this API:
<!-- https://mvnrepository.com/artifact/fr.opensagres.xdocreport/fr.opensagres.poi.xwpf.converter.core -->
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>fr.opensagres.poi.xwpf.converter.core</artifactId>
<version>2.0.2</version>
</dependency>
Pega function code used in PE V821. Feel free to contact me offline for more details about this sall exercise.
========================================================
Hi,
Initially I tried this approach but I didn't succeed in it. Then I changed to Plan B and started using Opensagres API and was successful as well.
For more details, check my LinkedIn post for all the list of 15 jar files to be used for this exercise.
Maven repository for this API:
<!-- https://mvnrepository.com/artifact/fr.opensagres.xdocreport/fr.opensagres.poi.xwpf.converter.core -->
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>fr.opensagres.poi.xwpf.converter.core</artifactId>
<version>2.0.2</version>
</dependency>
Pega function code used in PE V821. Feel free to contact me offline for more details about this sall exercise.
========================================================
try {
String wordDocFile=System.getProperty("catalina.base")+WordDoc;
String pdfDocFile=System.getProperty("catalina.base")+PDFDoc;
InputStream docFile= new FileInputStream(new File(wordDocFile));
XWPFDocument doc=new XWPFDocument(docFile);
PdfOptions pdfoptions=PdfOptions.create();
OutputStream out=new FileOutputStream(new File(pdfDocFile));
PdfConverter.getInstance().convert(doc, out, pdfoptions);
out.close();
doc.close();
return "SUCCESS!!";
}
catch(Exception e) {
e.printStackTrace();
return "FAIL!!";
}
Thanks,
Ravi Kumar Pisupati.
Ernst & Young LLP
IN
Thanks Ravi for your reply , the Conversion was successful via apache Poi apis but it seems that it can be only used for simple word templates and breaks when there are templates with complex header footer structures and alignments.
Hopefully docx4j can solve that purpose. Have tried the below code
try{
java.io.InputStream docFile = new java.io.FileInputStream(new java.io.File("C://PRPCPersonalEdition//temp//Sample.docx"));
tools.putParamValue("Shweta1","111");
org.docx4j.openpackaging.packages.WordprocessingMLPackage wordPackage = org.docx4j.openpackaging.packages.WordprocessingMLPackage.load(docFile);
tools.putParamValue("Shweta2","222");
java.io.OutputStream out=new java.io.FileOutputStream(new java.io.File("C://PRPCPersonalEdition//temp//test1.pdf"));
tools.putParamValue("Shweta3","333");
org.docx4j.Docx4J.toPDF(wordPackage, out);
tools.putParamValue("Shweta4","444");
}
catch(Exception e) {
tools.putParamValue("Shweta7",e.getMessage());
tools.putParamValue("Shweta5","555");
}
finally{
}
The line in bold fails with "Exception exporting package error" attaching the tracer snippet as well.
Request anyone to help .
Pegasystems Inc.
IN
Adding a sample spring boot proj which u can run and see by replacing test docx file path in DemoApplication class. including jars list as well.
CVS Health
US
Thank you Tharun for the given 42 jar files. Worked for me and this is another option for me to show case our biz partners. Here is the code used in the function(Eg: @WordToPDF(WordDocFilePath,PDFDocFilePath)) to call from a DataTransform by passing the DSS values as params to this function.
try {
String wordDocFile=System.getProperty("catalina.base")+WordDoc;
String pdfDocFile=System.getProperty("catalina.base")+PDFDoc;
InputStream is = new FileInputStream(wordDocFile);
WordprocessingMLPackage pack = WordprocessingMLPackage.load(is);
OutputStream os = new FileOutputStream(pdfDocFile);
Docx4J.toPDF(pack, os);
is.close();
os.close();
return "SUCCESS!!";
}
catch (Exception e){
e.printStackTrace();
return "FAIL!!";
}
Thanks and Regards,
Ravi Kumar
NTTData
IN
@Ravi Kumar Pisupati, Hi Ravi
I am trying to implement this scenario in pega 8.8.3 testing edition in pdn login as Senior System Architect
so my questin how to intialize variables for example passing word document to be converted into pdf document? how
do we initialize these variables data
for example : String WordDoc = "Test.docx";
String PDFDoc = "Test1.pdf";
suppose if i am not passing data above it throw a error while executing fucntion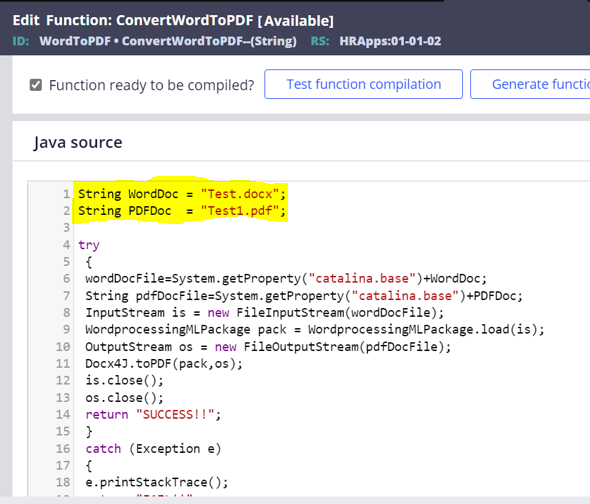
CVS Health
US
Yes, you're right Shweta. I agree that there are some limitations using my approach. But Tharun gave all the necessary jars (42) to work on this implementation. Let me give a try with them in my V85 PE and will get back on the result.
Thanks,
Ravi Kumar Pisupati.
HCL
NL
We have a similar requirement where we are getting base 64 stream from another service. Our requirement is to convert document stream of ms word documents to pdf and show them in browser. I was trying to convert the word document stream to pdf documents using below java code in pega.
version used : Pega Platform 8.4.3
java code used :
String docPath = "\\StaticContent\\global\\ServiceExport\\abcd.doc";
String pdfPath = "\\StaticContent\\global\\ServiceExport\\abcd.pdf";
char sep = PRFile.separatorChar;
try {
byte[] decodedBytes = new com.pega.pegarules.pub.util.Base64Util().decodeToByteArray(base64Stream);
oLog.infoForced("bytes decoded");
java.io.InputStream inputStream = new java.io.ByteArrayInputStream(decodedBytes);
oLog.infoForced("input stream object created from doc byte");
java.io.File wordFile = new java.io.File(docPath);
java.io.OutputStream stream = new java.io.FileOutputStream(wordFile);
stream.write(decodedBytes);
oLog.infoForced("writtern to word file");
We have a similar requirement where we are getting base 64 stream from another service. Our requirement is to convert document stream of ms word documents to pdf and show them in browser. I was trying to convert the word document stream to pdf documents using below java code in pega.
version used : Pega Platform 8.4.3
java code used :
String docPath = "\\StaticContent\\global\\ServiceExport\\abcd.doc";
String pdfPath = "\\StaticContent\\global\\ServiceExport\\abcd.pdf";
char sep = PRFile.separatorChar;
try {
byte[] decodedBytes = new com.pega.pegarules.pub.util.Base64Util().decodeToByteArray(base64Stream);
oLog.infoForced("bytes decoded");
java.io.InputStream inputStream = new java.io.ByteArrayInputStream(decodedBytes);
oLog.infoForced("input stream object created from doc byte");
java.io.File wordFile = new java.io.File(docPath);
java.io.OutputStream stream = new java.io.FileOutputStream(wordFile);
stream.write(decodedBytes);
oLog.infoForced("writtern to word file");
org.apache.poi.xwpf.usermodel.XWPFDocument document = new org.apache.poi.xwpf.usermodel.XWPFDocument(inputStream);
oLog.infoForced("document object created from doc byte");
org.apache.poi.xwpf.converter.pdf.PdfOptions options = org.apache.poi.xwpf.converter.pdf.PdfOptions.create();
oLog.infoForced("options object created");
java.io.OutputStream outputStream = new java.io.FileOutputStream(new java.io.File(pdfPath));
oLog.infoForced("output stream object created");
org.apache.poi.xwpf.converter.pdf.PdfConverter.getInstance().convert(document, outputStream, options);
oLog.infoForced("converion done");
} catch (Exception e) {
oLog.error(e.toString());
}
i am getting below error in pega log files when after convert function in the code. Could you please please share your comments on this.
but when i used the tools.sendFiles with the byte array generated in the above java code am able to download the file in the browser.
com.pega.pegarules.pub.PRRuntimeError
NTTData
IN
@Ravi Kumar Pisupati can you please provide me screen shot for function how you are implementing above function code.
Branch Banking and Trust Company
US
@Mr.Pisupati . i am going to call you today evening to get the process started. if you have any poc please share the same it will help me