Authored by Anonymous
Parallel processing can mean rule-level execution (two rules in parallel) or process-level execution (two processes in parallel).
- Rule-level execution is the spawning of multiple background requestor threads to achieve high throughput and performance by maximizing the resource utilization. This is also called “asynchronous” processing. For example, an application may initiate a call to a back-end system and continue processing without blocking and waiting for the external system’s response.
- Process-level execution involves configuring a stage to run multiple processes in parallel. This configuration allows users to perform tasks independently to complete the work in a stage. In such a case, the rules are not executed in parallel, but the business tasks are performed in parallel. For example, in the recruitment stage, you can include a process for interviewing a candidate. In the same stage, you can include a process for verifying a candidate’s job history. Both processes can be started and completed independently. When the interview and job verification are complete, the case moves to the next stage.
Options for parallel processing
Developers have multiple options available for implementation of parallel processing to improve user experience and application throughput.
Load-DataPage method in activity
Data pages are loaded synchronously by default. To load data pages asynchronously, use the “Load-DataPage” method in an activity and then use the Connect-Wait method. This method lets processing wait for the stated timeout interval, or until all requestors with the same “PoolID” have finished loading data.
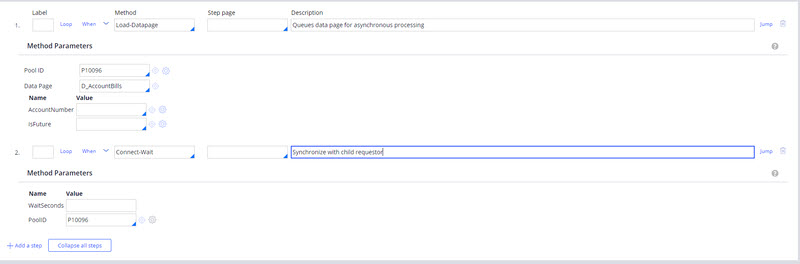
Figure 1: Activity using Load-DataPage method
In this option, “PoolID” is an arbitrary identifier to help manage asynchronous data loading and to utilize the data page results in the parent requestor thread. “PoolID” can be any valid string, a property reference, or a parameter. “PoolID” exists in the context of the activity using it, so you can have identical “PoolID” values in different activities without causing a problem.
The Load-DataPage method can be traced using the tracer setting option “ADP Load.”
The parameter page can be used for passing data to the data page from the calling activity. If the data set is large, as in the case of pages or lists, then you should use node-level data pages to reference required data.
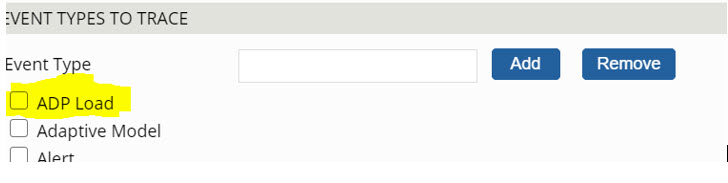
Figure 2: Options on Tracer settings
Note: Data pages loading asynchronously cannot run declarative expressions, triggers, and other rules that belong to a declarative network.
The Load-DataPage method is useful in scenarios where basic customer data and the associated product information need to be loaded, and they can be loaded independently, without waiting for each other to finish. When a data-intensive section needs to be loaded for a customer's microjourney (for example CSR flow), the data can be pre-loaded using this method, which avoids wait time for the CSR.
Call-Async-Activity method in activity
The “Call-Async-Activity” method executes a given async type activity asynchronously. By providing a poolID and then waiting on that poolID using the Connect-Wait method in subsequent steps, you can configure the caller activity to wait for the spin off activity before finishing processing.
The Load-DataPage and Connect-Wait are the only methods that can be used in an asynchronous type activity. Consequently, these activities can be used to group data pages to load asynchronously. Set the type as “Asynchronous” on the Security tab of the rule, as shown in Figure 3.
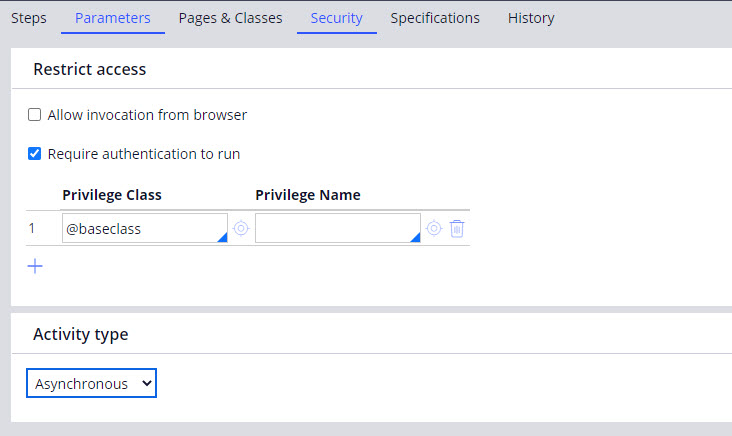
Figure 3: Asynchronous type
This method can be traced using the tracer setting option “Asynchronous Activity" (see Figure 4).

Figure 4: Options on Tracer settings
We can use a parameter page to pass the data to the data page from the calling activity. If the data set is large (that is, the data set is a page or list), you should use node-level data pages to reference required data.
The Call-Async-Activity method is useful when you want to load multiple dependent data pages. For example, you need to get the following data:
- D_Customer: Get the customer information
- D_Account: Get the list of accounts for a particular customer
- D_Products: Get the list of products based on the account information
In this scenario, you group D_Customer and D_Account using the async method and wait for the data to load. After the data loads, you use the loaded customer and account information to identify the list of products, using D_Products.
The advantage of using Asynchronous Activity is modularizing the piece of code which can be reused across the application (loading D_Customer and D_Account in the preceding example). This also eliminates multiple load data page calls within the same calling activity.
Queue method in activity
The Queue method is used to process another activity in parallel. Note the following when using this method:
- Queue uses a Java thread available for batch processing. When you use it, you should check agent/threadpoolsize values in DSS / prconfig.
- Verify that the called activity doesn’t introduce any locking issues, deadlocks, and other concurrency risks into your application as the queued activity works in a “fire-and-forget” mode where it never returns to the called thread to inform the completion status or any errors.
- We can’t trace the Queued activity, and logging is only option available for debugging purposes.
- If you are operating multiple applications in a single Pega instance or if you see any issues with the above-mentioned reasons, then you should use Queue-For-Agent (older versions before Pega 8) / Queue-For-Processing.
You can use this Queue method as an alternative to the Call method in scenarios where you have no need to wait for completion of the second activity or in scenarios where the queued activity can operate in “fire-and-forget” style.
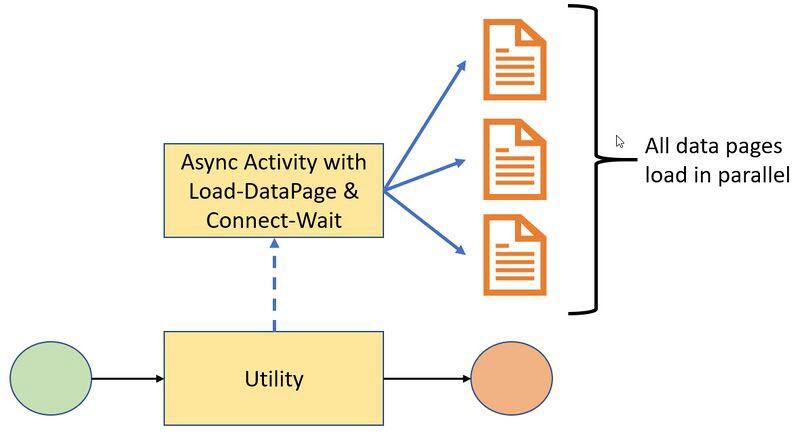
Figure 5: Call-Async-Activity method
The Queue method can be used in scenarios where you want to connect to an external system for any CRUD operation and you have no need to wait for the current requestor. For example if the CSR has a screen to update the account information and the account information needs to be updated in an external system, then you can use this Queue method to save/update account info in the external system while CSR finishes inputting the remaining screens of the journey.
Background processing is another efficient way of processing the rules in the background to achieve scalability, ease of use, parallelism, and better performance.
Queue Processor rules
Queue Processor rules (standard agents in the older versions before Pega 8) can be used for both queue management and asynchronous processing. You can use standard or dedicated queue processor rules.
You can use the Queue-For-Processing method in an activity or the Run in background shape in a flow to trigger asynchronous processes using Queue Processor. This method can use the BackgroundProcessing node to perform the batch processing. For more information, see Queue Processor rules and Queue-For-Processing method.
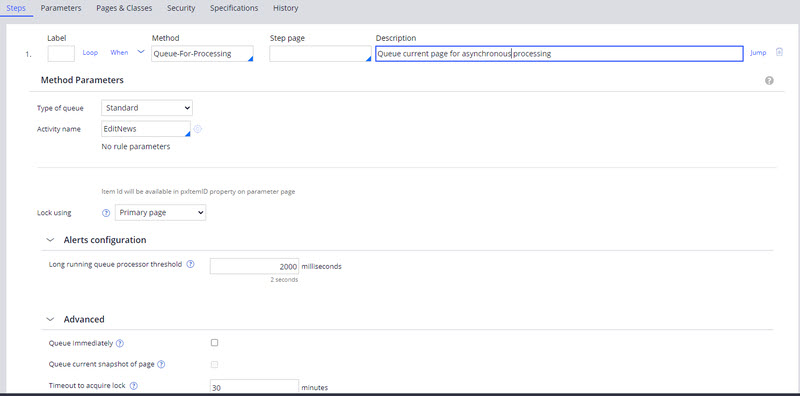
Figure 6: Queue-For-Processing method
You can use this method in scenarios where you want to:
- Submit a status change or any data updates to an external system in the background.
- Send notifications to customers via email or other notification immediately or after a specified delay.
The advantage of using Queue-For-Processing instead of Queue is the better fallback mechanism where broken queues due to an exception can be re-queued from Admin Studio. Tracing for debugging purposes can be done from Admin Studio. Dedicated queue processor rules can be used for delayed processing in tasks that need to be processed with a specific delay.
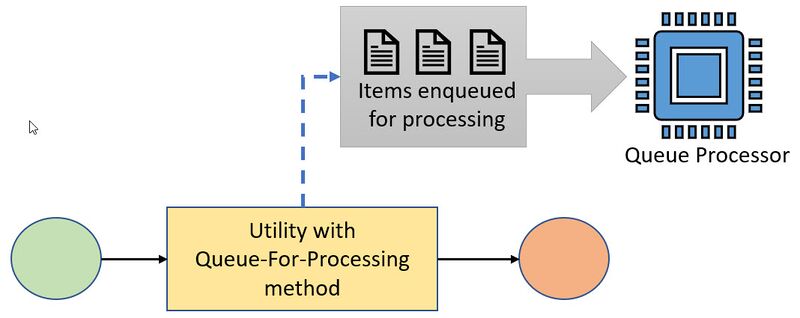
Figure 7: Flow of the Queue-For-Processing method
Connectors and Services
All connect methods except Connect-FTP and Connect-File can be operated in parallel with the combination of Connect-Wait / Wait shape to consolidate the results at a later point.
Most service types except Email and JSR94 Services support asynchronous processing. Service types that support asynchronous processing leverage the standard agent queue. For more information, see How asynchronous service processing works.
Parallel processing at the business process level
Platform provides capabilities to achieve parallel processing at the case level and at the flow level:
- At the case level, you can configure parallel processes. For information on configuration details, see Adding a parallel process to a stage.
- At the flow level, you can use the Split Join, Spinoff, and Split for Each shape provide a degree of parallel processing. for example, a loan application request flow may split into legal and financial flow executions that can proceed independently until a later join operation requires the two to consolidate. For more information, see Parallel processing in Pega applications.