Often when troubleshooting search and indexing issues, you need to know the health of the Elasticsearch cluster and shards. On older versions of Pega, enabling ALL level logging on org.elasticsearch.cluster.service.ClusterService class or enabling the REST API was required to get this information. However, starting with Pega Platform version 8.4.2, you can import or create and run an activity, ESClusterAndShardDetails, that provides this information to you. For Pega Platform version '23 and later, you can obtain the ES cluster information from System Settings tab in Admin Studio. (Refer to the figure below.)
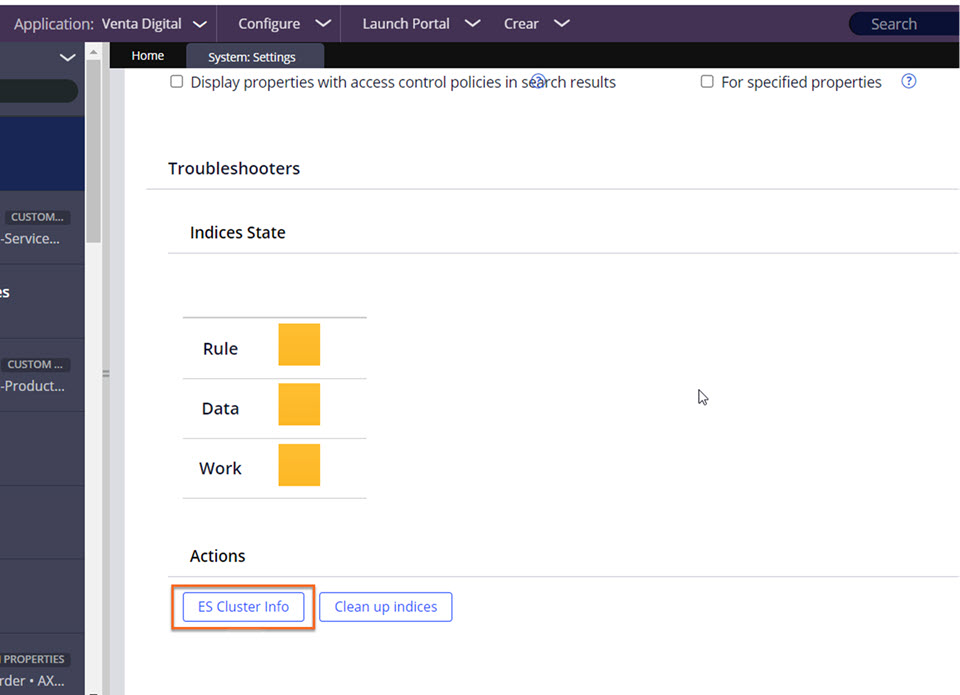
Importing the activity ESClusterAndShardDetails
Download the attached RAP file, which includes the activity, ESClusterAndShardDetails.
To get the activity into your application and access it, complete the following steps:
- Import the RAP file from Dev Studio.
- Add ESDiagnostics:01-01 to the Application Rulesets and click Save.
- Open the activity ESClusterAndShardDetails and run it.
Create the activity ESClusterAndShardDetails
Alternatively, you can create the activity yourself by following these steps:
- On the Parameters tab, create a local variable rtnValue.
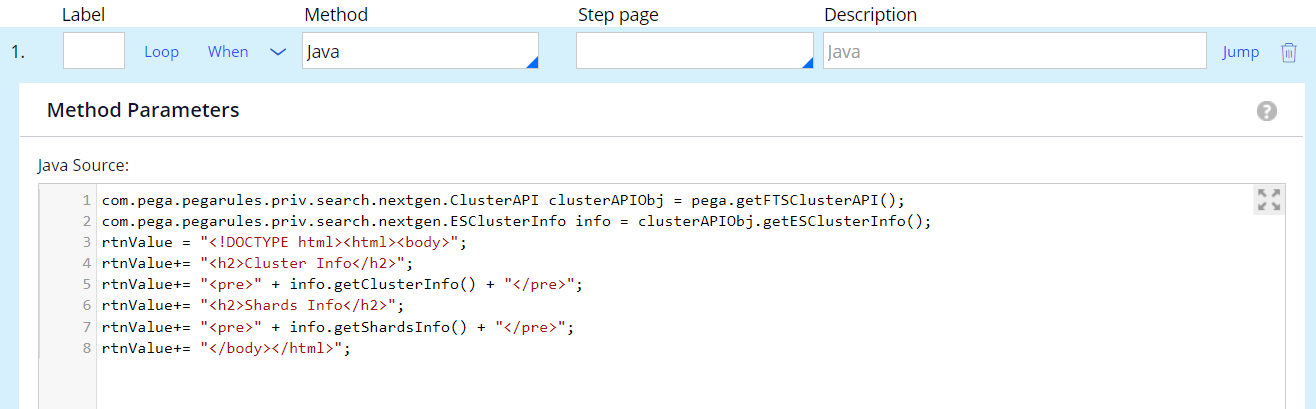
- On Step 1 of the activity, specify the Java method and the following code:
com.pega.pegarules.priv.search.nextgen.ClusterAPI clusterAPIObj = pega.getFTSClusterAPI(); com.pega.pegarules.priv.search.nextgen.ESClusterInfo info = clusterAPIObj.getESClusterInfo();
rtnValue = "<!DOCTYPE html>
<html>
<body>";
rtnValue+= "<h2>Cluster Info</h2>";
rtnValue+= "<pre>" + info.getClusterInfo() + "</pre>";
rtnValue+= "<h2>Shards Info</h2>";
rtnValue+= "<pre>" + info.getShardsInfo() + "</pre>";
rtnValue+= "
</body>
</html>
";
- Step 2 of the activity uses Show-Property. Pass it local.rtnValue.

- Run the activity: It opens a window with the output for your review.
Understanding the output
The results of running the activity ESClusterAndShardDetails provide two sections of diagnostic information:
- Cluster info
- Shards info
Cluster info
This following description of Cluster info is brief because, generally, the Shards info has the data that is more important when troubleshooting an issue.
status: Reflects index health.
- Green indicates that the indexes are currently healthy.
- Yellow indicates that some replica index shards are lost, still initializing, or relocating.
- Red indicates that one or more indexes are missing primary shards.
nodes.count.total: Reflects the total number of Pega nodes in the environment.
If the number shown is fewer than expected, then one or more Pega nodes either failed to start Elasticsearch during startup or they are in a different Elasticsearch cluster.
To determine which nodes are missing, examine the Shards info section, where specific nodes are identified.
nodes.count.master: Reflects the total number of index host nodes in the environment.
If the number shown is fewer than expected, then one or more index host nodes either failed to start Elasticsearch during startup or they are in a different Elasticsearch cluster.
To determine which index host nodes are missing, examine the Shards info section, where specific index host nodes are identified.
For more information, see the Elasticsearch reference guide, Cluster stats API. Note that this reference is for a newer version of Elasticsearch; therefore, there is additional output included that does not exist within the output from Pega.
Shards info
The Shards info section tells you which Pega nodes are in the Elasticsearch cluster, which shards they are holding onto, and the status of the shards. Most of the time, you need to identify the unassigned shards. This information is at the very bottom of the Shards info section. However, information in the other sections can be useful, depending on your troubleshooting needs.
nodes: Identifies all the nodes that are part of this Elasticsearch cluster.
The first value for each node aligns with Pega NodeIDs.
The second value is a node name used by Elasticsearch and is referenced in output further in this section.
You can use the data here to determine what shards are assigned to which Pega node.
You can also find the IP address and port being used by Elasticsearch along with which node is acting as the master.
Example:{UTIL-I-0DA35E2CE7E5E12A3}{dOJLAAJyRsKYZ7HLry1i5Q}{mXFXg8MvSVGaJ1PRw02eoA}{ Proprietary information hidden}{ Proprietary information hidden:9300}, master
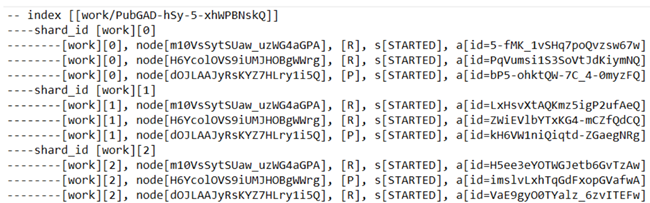
routing_table: Displays shard allocation and status by index, and what node is holding each piece of data.
In the example below we see the work index broken up into three different shards([0],[1], and [2]).
Each shard also has one primary ([P]) and two replica ([R]) shards, which are backups. This is Pega-provided behavior for any Pega Platform version 8.x environment with three index host nodes.
If there were two index host nodes, there would only be 1 replica. If only one index host node, then no replicas.
You can also see the name of the Elasticsearch node holding onto each shard, and you can reference the nodes section above to tie it to a Pega node.
Here we can also see that, in this example, the state of all shards is [STARTED]. You might also see [INITIALIZING] or [RELOCATING], which means that the shard might still be initializing or copying data from another node. These operations can take longer with very large indexes (1-2 hours with a ~600GB index); however, this should typically not take very long.
If the state is [UNASSIGNED], this suggests data loss. The entry also provides some data about why the shard is unassigned, for example, not having a valid copy of the data.
If a particular shard has no valid data (for example, work[1] has no primary or replica shards STARTED), that index is corrupt and a complete cleanup (shutting down index host nodes, clearing the contents of the index directories) is required to resolve this.
Example:
routing_nodes: Displays the same shard data as the routing_table section, except that it displays the data by node and has an UNASSIGNED section at the very bottom. If nothing is in the UNASSIGNED section, that most likely confirms that any issues being experienced are unrelated to corruption or data loss. It would still be worth confirming that the expected nodes are in the Elasticsearch cluster and each of the built indexes have a primary shard in the STARTED state.
Fixing Index Status
During restarts, it is not unusual for the index status to temporarily display as RED or YELLOW. The larger your indexes, the longer it may take for shards to report as STARTED and the indexes will not be GREEN until all index shards are STARTED.
If the indexes still show some shards with a state of INITIALIZING or RELOCATING, allow for more time before taking any action as this should eventually fail or complete successfully. If no shards are INITIALIZING or RELOCATING, then check the UNASSIGNED section for shards and look for a reason listed in the entry. The most important reason to be aware of is "no_valid_shard_copy", which suggests the data needed for this is not available in the current Elasticsearch cluster.
Scenario 1: Index Status is YELLOW
Generally this should not cause any immediate issues, but suggests that replica data is missing, which reduces the indexes resiliency in case of further issues. You may want to review the reason listed for shards being unassigned to see if that sheds any light on what is going on, but there are some general things to check for. Make sure all your index host nodes are online and in the Elasticsearch cluster based on the contents of the Cluster and Shards information as discussed above. If the node is not online and in the cluster, its data is not available for your indexes. If they are index host nodes, they should not only be listed as present in the Elasticsearch cluster, they should be hosting indexes routing_table and routing_nodes sections. If the index host node is online and listed in the Elasticsearch cluster, but is not hosting any indexes see if the node is listed on the Search Landing Page as an index host node. If not, it will not be considered an index host node and will not host indexes. Check to see if you are using the -Dindex.directory JVM argument to set this node as an index host node.
If the node is online, but not listed in the Elasticsearch cluster, check its startup log. When the node fails to initialize the Elasticsearch, you can check the solutions discussed here: the solutions of which are discussed here: pyFTSIncrementalIndexer not running or turning off automatically
Scenario 2: Index Status is RED
The same steps as outlined for Scenario 1 apply here, but there is greater concern because RED is telling us primary data is missing, not just replica data. If your status is RED, the shard data is reporting "no_valid_shard_data", and all your index host nodes are online and part of the cluster. This tells us data is corrupt or otherwise missing.
Solution:
When this is the case, shutdown all your index host nodes, clear out their index directories (where you have specified they store the index data), then bring those nodes up one by one.
You will need to rebuild your indexes from scratch and out of the box this process should start on its own. Check the Search Landing Page after the nodes are back up to see if re-indexing is in progress already or if you need to start it manually.
This could happen if the disk space ran out on the drive where the indexes are held for example, but there are other reasons and it is not always clear even after review. This is especially true on older versions of Pega where the logging is more limited in this area.
One thing to consider if you repeatedly see this behavior is to review your restart procedure. Rapidly restarting your index host nodes can cause this kind of behavior, especially when your indexes are larger because of how index data is managed within Pega, where data is copied from an online index host node into an index host node that is starting.
To help avoid issues with this, Pega has introduced a new index data management process to help prevent data loss in this situation by allowing data to synchronize rather than rebuild after restarts. To enable it, you must have the following DSS implemented.
indexing/distributed/auto_minimum_master_nodes
This should be set to true.
indexing/distributed/minimum_master_nodes
This should be set to more than half of the number of nodes that are hosting indexes. For example, with 3 index host nodes, this should be set to 2; for 5 nodes, this should be set to 3.
indexing/distributed/expected_search_node_count
This should be set to the number of index host nodes you expect to be available in your environment.
After creating or updating these values, a rolling restart of index host nodes is required.
Related Content
PEGA0054 alert: Query exceeded the operation time threshold
Troubleshooting Elasticsearch issues in Pega 7.1.7 through 7.4