Discussion
Pegasystems Inc.
JP
Last activity: 27 Jan 2022 1:51 EST
How to avoid "Unable to synchronize on requestor" timeout error
Hi,
Customer reported to me that thread dump and below error is thrown when they try to update a large amount of data in a database table (Data Type). In this post, I am sharing why this error occurs, and how you can avoid it.
...
--- Thread Dump Complete ---
2021-10-25 17:09:40,142 [http-nio-8080-exec-4] [ ] [ ] [ ] (ngineinterface.service.HttpAPI) ERROR localhost| Proprietary information hidden - Proprietary information hidden: com.pega.pegarules.pub.context.RequestorLockException
com.pega.pegarules.pub.context.RequestorLockException: Unable to synchronize on requestor H8KG0CQUQO6P3Z0RFOEMOK7U0HWYXH6NZA within 120 seconds: (thisThread = http-nio-8080-exec-4) (originally locked by = http-nio-8080-exec-9) (finally locked by = http-nio-8080-exec-9)
- Steps to replicate the error
1. I have created a simple activity as below to update all data in Employee Data Type. This table has 50,000 records.
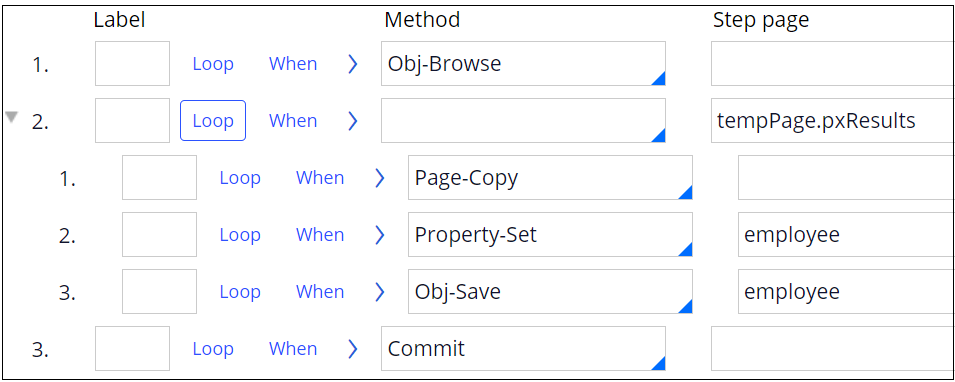
2. Run this activity. It took me approximately 5 minutes to complete and at the end of activity, it logged below requestor timeout error.
Unable to synchronize on requestor H8KG0CQUQO6P3Z0RFOEMOK7U0HWYXH6NZA within 120 seconds3. However, I have also verified that all 50,000 records were successfully updated in the database table.
- Root cause
A requestor thread represents an individual user or external system that connects to Process Commander. Requestors are unique Java objects in the JVM. When a user performs an action (clicks a button or link), HTTP requests are generated and sent to the Process Commander server. Then the Web container retrieves one thread from its thread pool to handle each HTTP request. Since one user can generate multiple HTTP requests, multiple threads may be required to work on the same Requestor object. If a requestor object waits for more than 120 seconds, "Unable to synchronize on Requestor ZZZZZZZ within 120 seconds" error is thrown.
- Solution
Although this error is not limited to the database operation, I think it is the most likely candidate. As I stated above, this error doesn't mean the database operation also fails. You may be able to ignore this error as the situation could be temporary and transient. However, if the error continues to occur and hinders production, you can consider below two options:
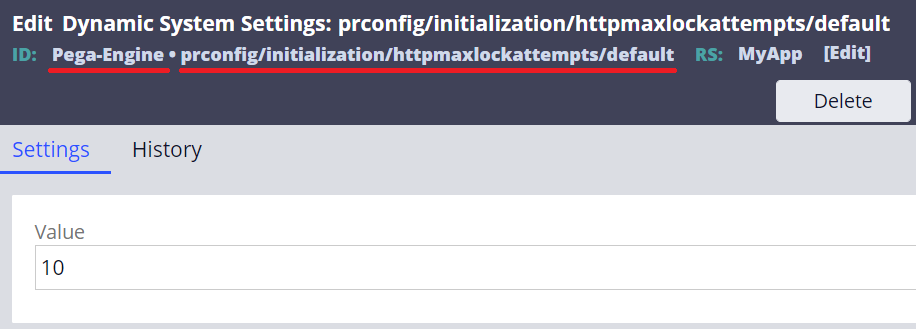
1. Create two Dynamic System Settings to extend the timeout threashold. 120 seconds of timeout consist of 6 attempts * 20,000 milliseconds by default. Below is a sample setting to change it to 10 attempts * 60,000 milliseconds, which makes 10 minutes. This approach doesn't speed up time it takes to complete the activity, but at least it suppresses the error.
1-1. initialization/httpmaxlockattempts
- Setting Purpose: prconfig/initialization/httpmaxlockattempts/default
- Owning Ruleset: Pega-Engine
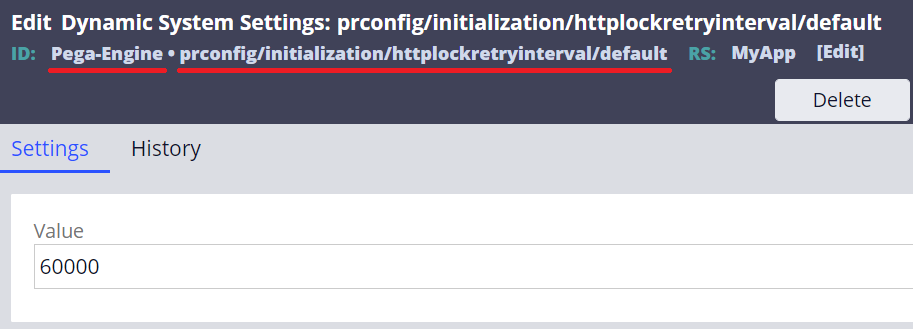
1-2. initialization/httplockretryinterval
- Setting Purpose: prconfig/initialization/httplockretryinterval/default
- Owning Ruleset: Pega-Engine
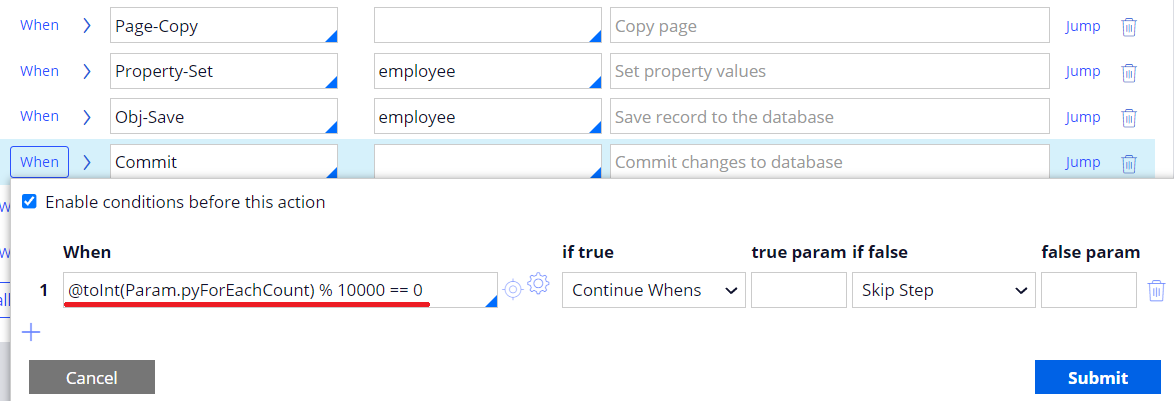
2. Another approach is to increase the commit frequency instead of having just one at the end of activity so the performance actually gets better. Committing 50,000 records at once requires a lot of resources on the database. In my example, I changed it to commit every 10,000 records (commit step has to be moved into a loop), the error is gone and the activity ended in less than a minute. Be noted, the drawback of this approach is that you are unable to manage transaction any longer (i.e. you can't rollback the entire operation when you are updating multiple tables).
Hope this helps.
Thanks,
Lventur
IN
Loading 50,000 instance information will make other requester session process to get impacted under particular node and this may lead to heap out of memory issue also. Pega will always recommend not to load more than 500 query results into session context. I am seeing in error message that this exception is getting occurred under user context, first we need to take this update logic to get happened in backend not in any user context.
One of the optimal solution to handle this error would be:
Query 500 records at a time and inside loop just queue each instance and have your table update logic to get happened in back end queue processor (or) agent for each index entries. After 500 entries queued successfully you can query next 500 records and do the same queue for updating table entry.
If we are going for this approach, the whole update process timing will get reduced at least 30% - 50% and we can easily handle exceptional scenario's also.
Major disadvantage of approach which has been mentioned as a fix would be -
1) If you are using Obj-Browse you need to hardcode the maximum result count, if in future records count is getting increased from 50,000 - 1,00,000 then you may loose some information update.
Loading 50,000 instance information will make other requester session process to get impacted under particular node and this may lead to heap out of memory issue also. Pega will always recommend not to load more than 500 query results into session context. I am seeing in error message that this exception is getting occurred under user context, first we need to take this update logic to get happened in backend not in any user context.
One of the optimal solution to handle this error would be:
Query 500 records at a time and inside loop just queue each instance and have your table update logic to get happened in back end queue processor (or) agent for each index entries. After 500 entries queued successfully you can query next 500 records and do the same queue for updating table entry.
If we are going for this approach, the whole update process timing will get reduced at least 30% - 50% and we can easily handle exceptional scenario's also.
Major disadvantage of approach which has been mentioned as a fix would be -
1) If you are using Obj-Browse you need to hardcode the maximum result count, if in future records count is getting increased from 50,000 - 1,00,000 then you may loose some information update.
2) Inside loop you are doing deferred save and at last you are doing commit, if incase inside loop you are getting any exception then you may lead to loose all deferred save values and it will be hard to implement retry mechanism also.
3) Increasing the threshold time would not be the optimal solution, in future in case you need to update 5,00,000 entries then that time also you will be getting the same error.
-
LK
@KenshoTsuchihashi Thank you for the clear explanation of the root cause
Toyota System
JP
In my opinion, when update large data we should use data flow to update or insert. I had been summary 6mil record into one table only take 1 hour by data flow.
Pegasystems Inc.
JP
Yup, that is a great idea. As far as Kafka is working stably in your environment, we are encouraged to use Data Flows as it will process it much faster.
Thanks,