Discussion
Pegasystems Inc.
NL
Last activity: 28 May 2024 8:27 EDT
Using BIX with large number of records
This page describes solutions to prevent BIX from running out of memory (OOM) while being able to export large number of records.
The issue
BIX can be a memory intensive process. The exact memory requirements depend on many factors including the number of records that are being extracted and the size of the records (the blob). For example, extracting 100.000 medium sized cases might require 40Gb of memory, when using basic BIX configurations. Instead of increasing the heap sizes to prevent out of memory, this article describes different solutions.
The solutions
The solution to this is to break your BIX extracts up into multiple pieces by applying filters or by using incremental delta extracts. Delta extracts can be configured by selecting the ‘Use last updated time as start’ checkbox on the Filter Criteria tab.
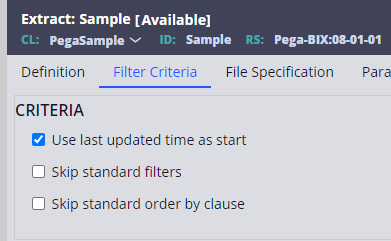
When there are many updated records since the last run, this solution might however still cause OOM errors and filtering should be considered.
Filter conditions can be defined on the Extract Rule itself under the Filter Criteria tab, as show in below screenshot:
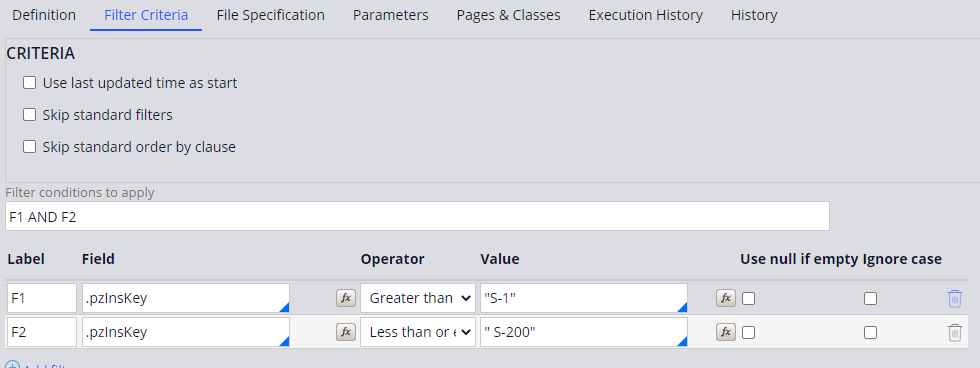
Keep in mind these are alphabetic and not numeric filters. Meaning in the example also the case with id “S-1000” is selected.
Maintaining filters like this directly in extract rules might cause maintenance challenges, but fortunately it’s also possible to use an alternative form of filtering by specifying the filter conditions when running the extract.
For example when running BIX from the command line the -d <start date> parameter can be used to extract only cases created after start date. Full overview of all parameters can be found at:
These parameters can also be used when running BIX with the pxExtractDataWithArgs activity. See https://community.pega.com/knowledgebase/articles/data-management-and-integration/86/running-extract-rule-using-agent for more info.
Note this might cause problems when you’re using the XML of CSV output with static filenames, since files will be overwritten when extracted multiple times without moving the files. To prevent this, you can use dynamic filenames using the % syntax. For example: %i to add the unique run identifier:
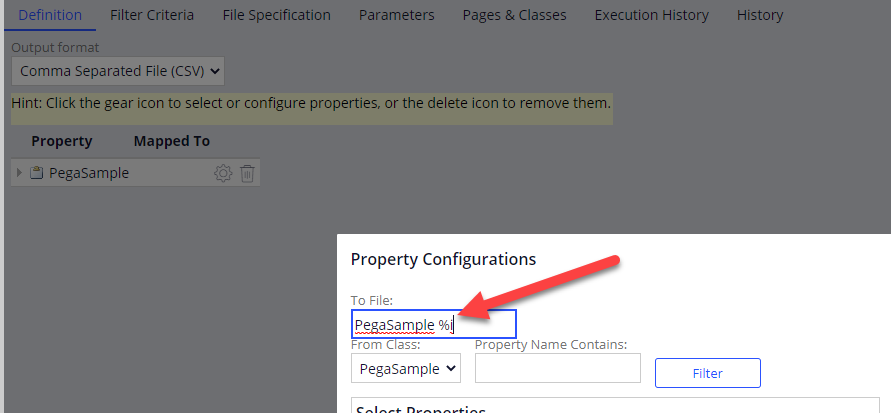
More information about other available parameters see: https://community.pega.com/knowledgebase/articles/data-management-and-integration/86/creating-and-running-extract-rule
As with the incremental delta option using filters might also cause an unexpected number of records to be extracted. For example many cases could be created within a small time window and/or case ids could be skipped because of the way case ids are generated since Pega 8.3 (see https://collaborate.pega.com/discussion/case-id-generation-mechanism)
To resolve this, you could first run a simple query to determine the filter criteria to be used after that in the extract run. In the next example Obj-Browse is called in a loop with a MaxRecords set to 200 and a ‘greater than’ filter, until there are no results found. For each resultset the first and last CreationDate is used to compile the BIX arguments. Also a -k parameter is filled for a unique run identifier. Within this loop a BIX extract can be called, using the BIXArgs parameters.
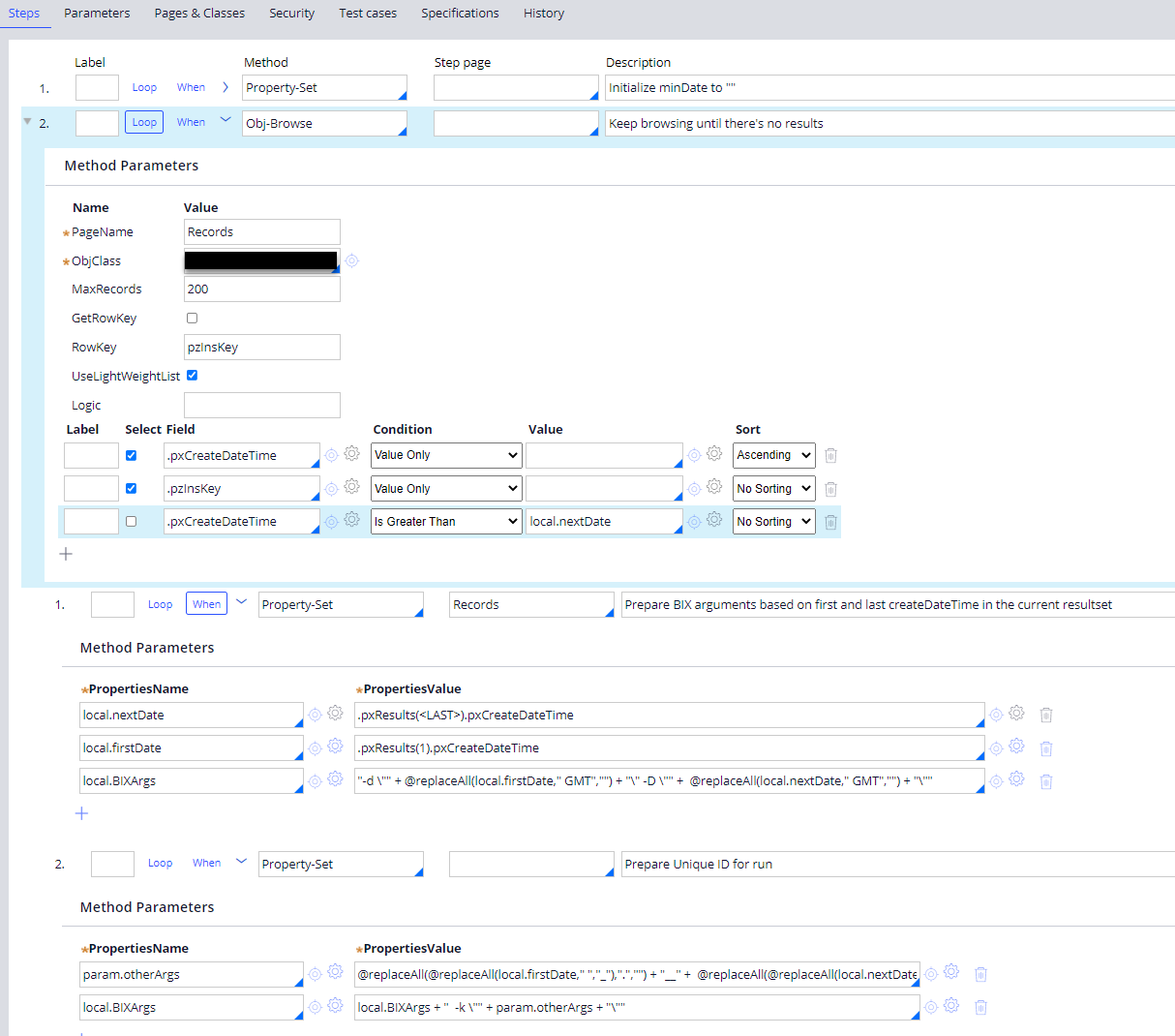
This allows for chunks of 200 records getting exported per extract run, significantly reducing memory requirements.
Further considerations
- Above scenario assumes no vertical or horizontal scaling. Increasing the amount of available heap does allow for bigger chunks but might not be possible or is very costly in many setups.
- As with any background processes make sure you’re scheduling it to run on non-webuser nodes, to improve user experience for interactive usecases. Typically a dedicated BIX nodetype is available for this.
- For effective horizontal scaling consider not directly extracting in the loop but use a queue processor to spread the load over multiple nodes. Keeping in mind that when the extracts are written to the local filesystem, you might need to collect files from various nodes.
- Consider that some cloud environments might have restrictions in the BIX feature set they support.
- Note that when BIX is querying large datasets you might need to increase the BIX specific Database queries timeout (BIX/selectQueryTimeout). When using small chunks however, updates to this timeout are not needed.
- More details on the timeout and troubleshooting see https://community.pega.com/knowledgebase/articles/pega-platform-troubleshooting/troubleshooting-bix-premises-environments#query-timeout-exception
Pegasystems Inc.
US
@Eric Rietveld Thanks for this article. Does the Obj-Browse approach work for CSV extract? When I tried in Pega Platform 8.6.1, it only generated one CSV file (looks like cases extracted in the last loop only) in the destination folder. It did not consolidate the chunks into one CSV file. Appreciate if you can confirm.
Pegasystems Inc.
US
@Will Cho This is fixed by adding "%i" to the file name. Also I had to use GMT datetime in BIX arguments to get all extracts. Thanks.
"-d \"" + local.firstDate + "\" -D \"" + local.nextDate + "\""
TEST
US
@Eric Rietveld what is the condition used on 2nd step LOOP ?