Applies to Pega Platform versions 7.1.7 through 7.4.
Elasticsearch was introduced in Pega 7.1.7 to offer improvements to fault tolerance and search speed over Lucene, which had been used in earlier Pega releases. From Pega 7.1.7 through Pega 7.4, common issues have been reported that best practices and troubleshooting techniques can prevent. This article focuses on Pega 7.3.1. You might find this article to be helpful with other Pega 7 minor releases. When information pertains a specific Pega 7 minor release other than Pega 7.3.1, it will be identified.
Getting started with Elasticsearch
Solutions for Search Results issues
Artifacts to provide when submitting a Support Request or posting to the Pega Support Community
Getting started with Elasticsearch
To specify Elasticsearch settings, go to the Search landing page:
From the Designer Studio menu, click System > Settings > Search.
On the Search page, you can control the following options:
- Enable or disable Indexing (Index administration)
- Initiate re-indexing
- Enable or disable Security settings
- View Agent information
- Specify the Search index host node setting
- Specify Query settings
- Full-text search settings
- Fuzzy query settings
By default, after you install Pega, the first node that starts will begin to build the rules and data indexes in the Pega temp directory automatically.
Best practices
To ensure that Elasticsearch works successfully in your Pega applications, follow the guidelines in this section. Most of the guidelines relate to working with the sections of the Search landing page.
- Always let the first index host node finish building the indexes before you add secondary index host nodes.
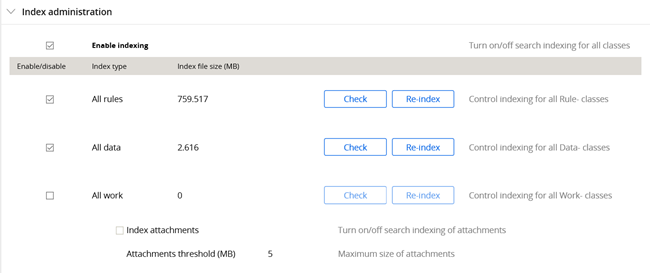
Find the status of the index process on the Search landing page, Index administration, next to the specific Index type, between the Index file size and the Check button.
- If the application has been upgraded to 7.1.7 or a later release from any version of Pega prior to 7.1.7, you need to manually rebuild the indexes to switch to Elasticsearch:
-
Before reindexing, ensure that the following Dynamic System Settings exist and are set to true:
Pega-SearchEngine/indexing/distributed/enabled
Pega-SearchEngine/indexing/distributed/index_enabled
Pega-SearchEngine/indexing/distributed/search_enabled - In Search, Index Administration, click Re-Index to switch to Elasticsearch.
-
- A minimum of three index host nodes is best for maximum fault tolerance, but additional nodes may be advisable depending on the size of the cluster. It is worth noting here that in order for Elasticsearch to function, the number of indexing host nodes online (O) must be greater than or equal to the total number of indexing host nodes configured (T) divided by two, plus one (O >= ((T / 2)) + 1). For example, if four nodes are listed as indexing host nodes, at least three must be online for Elasticsearch to function. If the number of index host nodes online is not high enough because some nodes have gone down, Elasticsearch will need to be restarted.
To address this type of issue without restarting the application, complete the following steps:
- Remove all the nodes from the Search landing page.
- Submit the change.
- Disable indexing entirely from the Search landing page: In Search, Index Administration, the Enable/Disable settings, clear the check boxes to disable indexing for all Index types.
- Click Submit to commit the change.
- Enable indexing again: Select the check boxes for all Index types.
- Click Submit to commit the change.
- In Search index host node setting, re-add the online index host nodes.
- Click Submit the commit your changes one last time.
Removing all indexing host nodes, disabling indexing entirely, and then re-enabling indexing should restart Elasticsearch and allow it to recalculate the number of indexing host nodes that need to be online.
Alternatively, restarting the application after removing the nodes that are down will also address this type of issue.
If you want to manually set the minimum number of indexing host nodes required to be online for Elasticsearch, set the following Dynamic System Settings to true:
Owning Ruleset: Pega-SearchEngine
Purpose: indexing/distributed/auto_minimum_master_nodes
And set the following DSS to your desired minimum:
Owning Ruleset: Pega-SearchEngine
Purpose: indexing/distributed/minimum_master_nodes
- Ensure that indexes are hosted locally on the server that is hosting the application server, rather than on a network drive.
Although hosting the indexes on a network drive is supported, you will have fewer issues if the indexes are local. - For Elasticsearch to function, TCP ports need to be open for communication between nodes.
By default, ports in the range of 9300-9399 are used.
You can customize the range of ports by adding the following setting to the prconfig.xml file and specifying a different port range:
<env name=”indexing/distributed/transport/port” value=”9300-9399” /> - If you are using Pega 7.2.2 or a later release, add the following JVM argument on all nodes:
-Dindex.directory=<index_directory>
On nodes that will always host indexes, specify the directory for the indexes to be built in.
On nodes that should never host indexes, do not specify an index directory.
For more information about managing Elasticsearch index host nodes outside of the Search landing page, see Managing Elasticsearch index host nodes outside of the Search landing page. - If index size becomes a problem, limit the classes being indexed to only ones that need to be included in search results.
The option to do this appears when you perform a re-index:
Either specify specific classes to include or include all classes except specific ones.Reindexing specific classes will not stop other classes that are already being indexed from continuing to be indexed. For this, the indexes would need to be rebuilt from scratch. That is, if you previously had all classes indexed and wanted to reduce the size by specifying specific indexes only, you need to start over; otherwise all classes will continue to be indexed.
- The Agent information section of the Search landing page shows the FTSIncrementalIndexer, the size of its queue, and the oldest entry in its queue.
As work is created and updated, entries are added into this queue so that the indexes can be updated. For small clusters, this agent can run on all nodes. But as the cluster grows in size, additional nodes running the agent may not add value.
Exactly how many nodes should be configured to run the agent depends on the expected volume of cases updated and created. If there is concern about this agent having a performance impact, find a balance for your specific application for the least number of nodes running the agent while also being able to keep up with entries in the FTSIncrementalIndexer queue. - Additional log entries can be produced for both searching and indexing issues if DEBUG or ALL (more verbose) level logging is enabled on the Elasticsearch package:
com.pega.pegarules.search.internal.es
If you are using Pega 7.3.1 or a later release, use the following loggers instead of the one given above:
PegaSearch.Indexer (for Indexing)
PegaSearch.Searcher (for Search) - Find node information in the <data_schema>.PR_SYS_STATUSNODES table, which includes data about which nodes are hosting indexes and what network address and ports are being used.
The <data_schema>.PR_LOG_CLUSTER table will contain data about batch indexing operations, including who initiated a re-index, what classes were included in the re-index request, and its status.
Solutions for Indexing issues
If re-indexing does not start or indexing takes a long time, try the following techniques.
If you are unable to initiate a re-index, check the following conditions:
- The index host node ID is correct on the Search landing page.
- The specified index directory exists and is writeable for the user running the application server.
- Elasticsearch TCP ports are open between nodes. See Best practices, Guideline 5.
If the index host node ID specified is not the node that you are logged into and you are unable to initiate a re-index, this could be a sign that the Elasticsearch ports are not open between the nodes. - The index file directory is refreshed if there are existing index entries.
Sometimes re-indexing runs more smoothly if the application is brought down and existing indexes are deleted by removing the contents of the index file directory.
If none of these suggestions help, try the following alternatives:
- Run Tracer when performing the re-index to see if an error is present there.
- Enable DEBUG on the Elasticsearch package and review the PegaRULES log. See Best practices, Guideline 9.
If the indexing process is taking a long time, adjust the following Dynamic System Settings to improve the performance:
Note: Running a re-index with these DSS values requires more resources (CPU and memory):
indexing/distributed/batch/numworkers value: 2
indexing/distributed/batch/workqueuesize value: 20000
indexing/distributed/batch/requestbatchsize value: 500
After adjusting the DSS values, restart Elasticsearch. See Best practices, Guideline 3.
Solutions for Search Results issues
If search does not work as expected and search results are questionable, ask the following questions and try the suggested actions.
Does search work at all for any user or on any node?
If search is not working for anyone, this is likely an issue with the indexes.
- Check the Search landing page to confirm that indexing is enabled.
- Click the Check button next to the indexes to see if any of the indexes have become corrupt.
- Rebuild any corrupt index.
When rebuilding corrupt indexes, you might want to stop all FTSIncrementalIndexer agents that are running and truncate the <data_schema>.PR_SYS_QUEUE_FTSINDEXER table prior to initiating the re-index. This is suggested because the re-index process will index the current state of the objects being indexed (work, data, or rules) and, therefore, the entries in this table are not needed.
Running out of file space on the server that is hosting the node hosting indexes is an example of something that could cause indexes to become corrupt.
Is the issue specific to one user or one group of users?
Search requests are restricted to the operator’s current work pool.
Check to see if the instances that are not found belong to a work pool that is different from the operator’s default work pool.
Are you unable to find newly created work? Do recently updated work objects show old data in the results?
These types of results are usually caused by the FTSIncrementalIndexer agent not processing items in its queue or processing them slowly. This causes delay between when work is created or updated and when the search results reflect those changes.
Check the Agent information section on the Search landing page or check the count of the <data_schema>.PR_SYS_QUEUE_FTSINDEXER table directly to see if the queue size continues to grow over time.
If the FTSIncrementalIndexer agent is not running on all nodes, having additional nodes run it might help.
Note: A performance issue with this agent was discovered and fixed in Pega 7.2.1. If you are running a release prior to Pega 7.2.1, submit a Support Request (Service Type = Product Support and Request Type = Existing Hotfix) to obtain the following hotfixes:
Pega 7.1.6 – HFix-32069
Pega 7.1.7 – HFix-32072
Pega 7.1.8 – HFix-25805
Pega 7.1.9 – HFix-28521
Pega 7.2 – HFix-28181
Along with these hotfixes, changes to a stored procedure and indexes must be made.
See the companion article for more information: Updates to sppr_sys_reservequeueitem_b
Is the issue node specific?
Node-specific search issues suggest a node communication problem, which you can resolve using the following checklist:
- Ensure that the Elasticsearch TCP ports are open between nodes. See Best practices, Guideline 5.
- Check to see if there are any clustering issues being experienced. Clustering issues can also lead to search problems.
For example, in Pega 7.2.2, clustering issues might manifest as changes not propagating across nodes or all members not being listed in the cluster in the logs or on the Cluster Management landing page. - Consult your system administrator to see if the servers hosting the Pega indexing host nodes have multiple network interface cards.
When Elasticsearch starts, it chooses one of the available IP addresses on which to listen for communications. If the wrong IP is used, communications will not be received and users will experience a search issue.
You can see the IP address and port being used by the indexing host nodes by reviewing the pyIndexerAddress column of the <data_schema>.PR_SYS_STATUSNODES table.
Set the IP explicitly by adding the following setting to the prconfig.xml file and specifying the correct IP to use:
<env name="indexing/distributed/network/host" value="<the IP address your server should use for internode communication>" />
Example: <env name="indexing/distributed/network/host" value=" Proprietary information hidden" /> - Enabling DEBUG or ALL level logging on the Elasticsearch package might also be useful in further diagnosing the issue. See Best practices, Guideline 9.
The node on which the search request was made will show what the user was searching for, the generated Elasticsearch query, and the top results. It will also indicate if it was unable to reach the indexing host node. Developers are encouraged to use this approach to aid in determining the root cause of node-specific search problems.
Artifacts to provide when submitting a Support Request or posting to the Pega Support Community
When you post your Elasticsearch question to the Pega Support Community (PSC), remember not to disclose personal or company-confidential information. Refer to the Community Rules of Engagement.
The Global Customer Support engineers working in the Pega Support Community will respond to your post or determine if a Support Request (SR) is needed.
When you submit your SR, write a clear, concise description of your problem that includes the answers to these questions:
- When was the issue first observed?
- What task were you performing and what issue was observed?
- Were any changes to Search settings or the environment made around that time?
- For issues with search results, answer the questions listed in Solutions for Search Result Issues.
Attach the following artifacts to the SR:
- Screen shots that show the issue.
- Screen shots of the Search landing page with all sections expanded.
- Screen shots of the Administration > Configuration Management screen in the System Management Application (SMA).
- The output of this query: select * from <data_schema>.PR_SYS_STATUSNODES;
- PegaRULES and ALERT logs with DEBUG level logging enabled. See Best practices, Guideline 9.
Related Content
Pega Predictive Diagnostic Cloud release notes archive
Updated stored procedure, sppr_sys_reservequeueitem_b
Troubleshooting Search indexing failures
Troubleshooting pyIndexDirectory null after nodes restart