Authored by <Anonymous>
Consider the following scenarios:
- A health care customer receives a huge volume of claim information in a variety of file formats (XML, EDI, CSV, or JSON ). Incoming files must be processed and cases must be created for each record.
- A banking customer receives bulk home loan requests and supporting data from its front-end system in a CSV format. At the end of each business day, these files must be processed and cases must be created in the loan application system.
- An insurance customer is migrating its legacy mainframes system to Pega Platform™ as part of its organization’s digital transformation initiative. During this migration, huge sets of old and inflight data must be transferred as files. These files must be processed and cases must be created in the new system.
In each scenario, a high volume of data in predictable file formats flows in, and the data must be processed accurately and quickly. To support these scenarios, you can use file listeners in combination with Service File rules.
About file listeners
File listeners monitor the contents of specified file directories. When a file in a monitored directory matches a defined pattern, the file listener moves the file to a temporary folder and calls the file service. The file service uses the parse rules to read the files and map the information to the clipboard. The service activity can then process the data; for example, it might persist the data into a data table or create a case in the application.
Refer to the following resources for information about file listener configuration:
- https://community.pega.com/knowledgebase/articles/data-management-and-integration/86/configuring-file-service-and-file-listener-process-data-files
- https://community.pega.com/knowledgebase/articles/data-management-and-integration/86/best-practices-processing-files-using-file-listener
Options for maintaining high data throughput
This section describes options for scaling data ingestion and achieving high data throughput by using file listeners.
Multithreading
Multithreading executes multiple threads doing identical tasks simultaneously. The number of threads should be optimized based on the thread pool size available on JVM. See "Thread pool size configuration," below, for more information on optimizing multithreading.
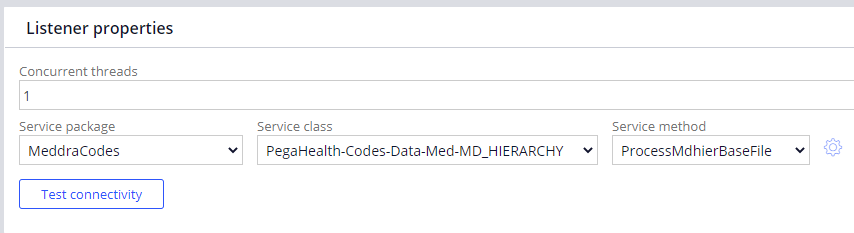
Concurrent threads on listener rule
Enter a number in the range 1-5 in the Concurrent threads setting in the listener Properties tab (Figure 1) to configure concurrent threads. For example, if a single listener can process X number of files, then setting the Concurrent threads setting to 5 would make the listener process 5X records during the same time.
The thread pool size can be changed if you want to increase the number of concurrent threads available for this work.
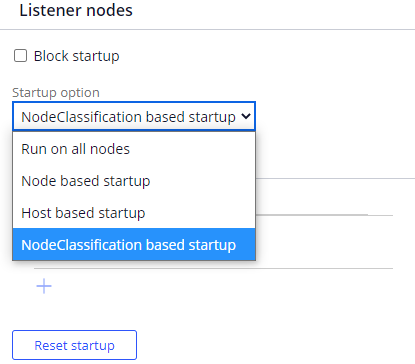
Multiple dedicated nodes
Increasing the number of records a single listener processes (vertical scaling) can be a limited solution. You can deploy multiple dedicated background processing nodes (horizontal scaling) to read files and process data by using listeners. Configure options on the file listeners to manage data processing in a multi-node environments (Figure 2).
Configuring File Services
The preceding sections describe how to use multithreading at the file listener level. This section describes options for using service file rules to process the records simultaneously in multiple threads.
Using Agent -Queues for processing
You can use the Execute asynchronously (queue for Agent) option (Figure 3) on the service file to place a service request in a queue to be picked up for scheduled execution by a standard Agent ProcessQueue (from the Pega-IntSvcs agent rule). With this option, the file service starts reading the next record in the file while the queue is getting picked up by the standard agent.
A standard agent picks up items in a queue and executes service activities, such as persisting data or creating a case using the data in the record. This parallelism help achieve high throughput in reading files and in processing them. This mechanism also provides better exception handling through requeuing options if errors are detected.
NOTE: The thread pool size can be changed for increasing the number of concurrent threads available for processing the queues.
Refer to the following resources for information about asynchronous processing using services:
- https://community.pega.com/knowledgebase/articles/data-and-integration/how-asynchronous-service-processing-works
- https://community.pega.com/knowledgebase/articles/data-management-and-integration/86/service-request-processor-data-instances
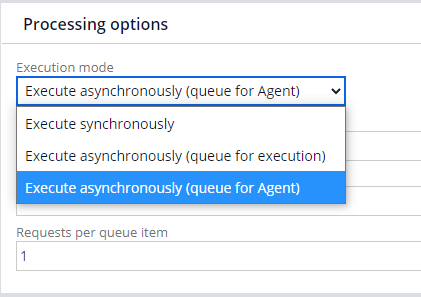
Job scheduler
You can select the Execute Synchronously option (Figure 3) on the service file to process and persist the records to a staging data table. You can then configure a number of identical job schedulers to process discrete records from the staging data table to create cases.
Using job schedulers helps achieve high throughput in processing the data records. but additional logic must be written in job scheduler activity to identify the discrete unprocessed records from the staging table and to handle any exception scenarios.
Refer to the following resource for information about job schedulers:
Thread pool size configuration
The size of a thread pool determines the number of threads allocated for execution of tasks. The number of threads available for parallel processing depends on the value set in the “threadpoolsize”. By default, this size is set at 5. To override this default setting and increase the number of concurrent agent executions, add or change the following string to the prconfig.xml file:
<env name="agent/threadpoolsize" value="#" />
where # identifies the number of threads in the thread pool.
NOTE: Changing the thread pool size affects overall system performance. You should override the default value only on batch processing nodes.
Tuning the listener configuration settings
You can tune listener configuration settings to optimize performance during high volume data processing:
- Set the listeners polling interval (seconds) to the minimum time (1-2 seconds) to reduce the time that the listener goes for sleep before checking for a new file to process. You can increase the listening polling interval when you no longer require high data throughput.
- Uncheck the Process empty files check box if you do not need to address null record processing.
- Uncheck Persist Log-Service-File instances? to save instances of the Log-Service-File class (which records the processing of a listener) in the Pega Platform database for reporting or debugging. When this setting is disabled, instances of this class are present in server JVM memory only and are discarded when the server is stopped. For optimal performance in high-volume production situations, uncheck this check box after you debug a Service File configuration.
- Uncheck Select Attempt recovery? to disable automatic debugging overhead. When this option is enabled, file listener processing might create many instances of the Log-Service-File class to aid in debugging, which can affect system performance.
Processing more emails, faster
You can configure the number of concurrent threads that can be spawned simultaneously, within the email listener. This would help in scaling up for large volume load requirements for organizations.
Refer to the following resources for information about configuring email listener threads.