Authored by Vinod Pakalapati
Extensibility is a software system design principle that simplifies the addition of new capabilities or modification of existing functionality. It’s also a measure of a system’s ability, or the level of effort required, to extend the default logic. Extensibility has a lot of advantages such as easier maintenance, easier updates, promoting reusability, faster development, savings in testing time, etc.
In a multi-layered application (for example, base application, segment specialization and customer implementation), design is a key factor for ensuring proper maintainability and extensibility. Improper design would compromise the quality of the application and make its maintenance very complex. For example:
- A data transform without parameters or extension points in the base layer, needs to be overridden in the customer implementation layer, even for minor specializations.
- A flow with a hard-coded class name or work queues, needs to be overridden in the customer implementation layer just for referring the implementation specific class or work queue.
Once overridden, logic should be maintained in two versions (base and customer implementation) of the rule and customers need to manually retrofit any changes into their own versions whenever the base version changes.
The following list of patterns, in combination with the traditional specialization techniques like class, ruleset, etc., will help to reduce the duplication of code and improve the maintainability and extensibility of the application.
- Parameterization
- Extension
- Modularization
- Componentization
Extensibility patterns
Parameterization
Parameterization is a pattern wherein the logic inside a Pega rule is driven based on the value that is passed as a parameter to the rule, instead of hard-coded data. Parameters are always the preferred option for implementations, instead of having different versions of the same rule with minor specializations doing the same thing. The concept of parameterization is not limited to data transforms, but can be applied to many Pega rule types, like data pages, report definitions, activities, flows, etc. The main objective of parameterization is to:
- Reduce duplication of code.
- Reduce implementation time of future specializations.
- Increase reusability.
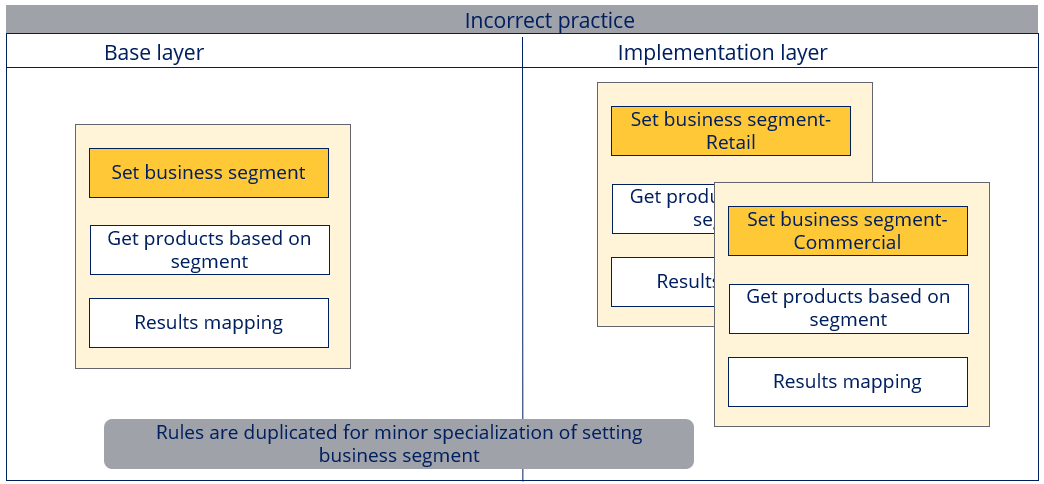
For example, let's take a use case where business segment is set via a data transform, and based on the business segment, associated products are retrieved. Incorrect and correct behaviors on how this use case can be implemented are shown in the image below.
- Assume the data transform for setting the business segment is not parameterized.
- In the base layer, business segment is set to ‘General’, as it is not dependent on any segment.
- A retail segment application built on the base layer has to set the business segment to ‘Retail’ and in this case the data transform in the base layer has to be overridden in the retail implementation layer, to set the business segment.
- Likewise, for a commercial segment application built on base layer, the data transform has to be overridden, to set the business segment as ‘Commercial’.
- Essentially, the same data transform is copied into different layers to set different segments.
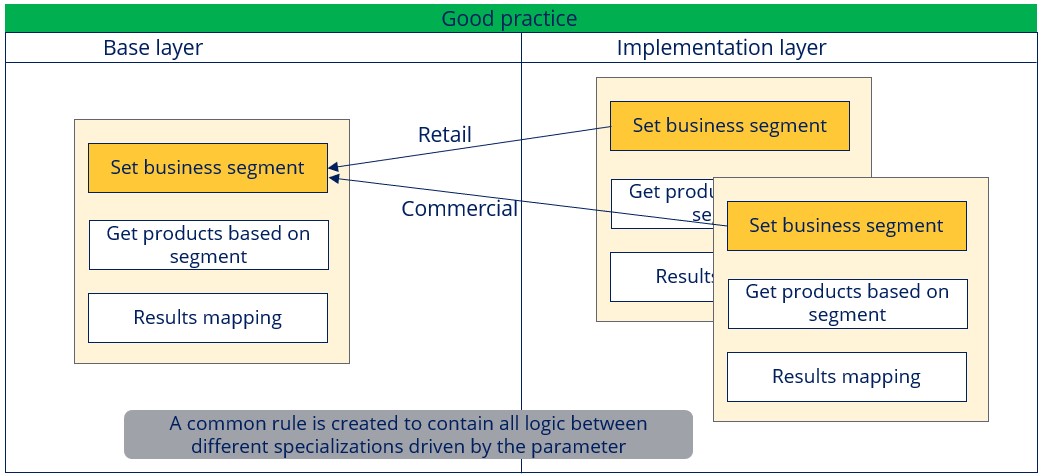
- In case there is a common logic for both retail and commercial segments, then the logic can be wrapped up in the base layer data transform and can leverage the “Call superclass data transform” option from retail and commercial segment data transforms. This way, duplication of logic can be avoided in specialized layers. Instead of copying, if the data transform is parameterized to accept business segment as a parameter, then the data transform in the base layer can be reused for both the retail and commercial segments. This would reduce duplication of the code and would assist in easier maintenance of the application.
Extension rules
Extension rules are designed and intended to be overridden to meet application needs. Typically, the overriding rule is updated in the implementation class. Rules that are intended to be extended are called stub rules, marked as extension, without any logic in them.
Core rules in the base layer should be provided with appropriate extension points at the right places so that customers can use those extension points to add implementation-specific logic without overriding the base rule. The extension rule is overridden into the customer implementation layer to extend default behavior by adding implementation-specific logic. The main objective of the extension rule is to:
- Reduce the number of overrides, for customization.
- Promote extensibility.
- In turn, assist with easier updates.
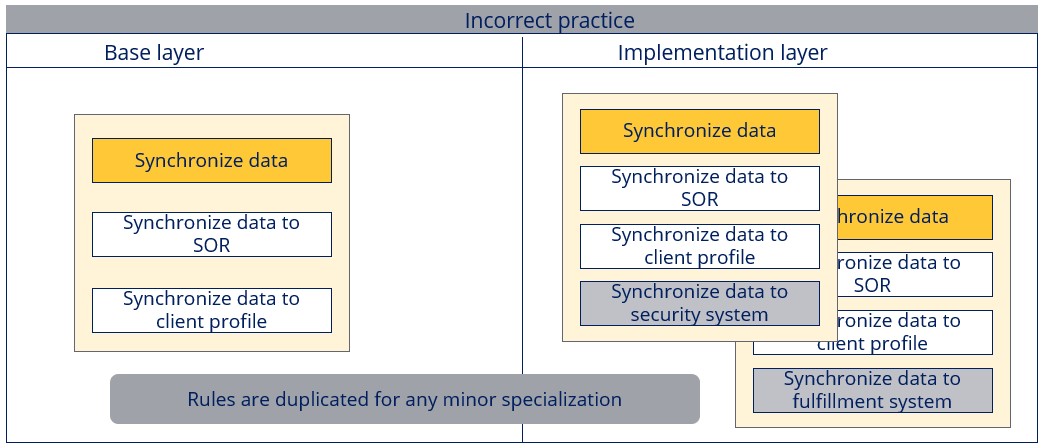
For example, let’s take a use case of data synchronization. Incorrect and correct behaviors on how this use case can be implemented are shown in the image below.
- Assume the discussed data transform does not have any extension points.
- In the base layer, data is synchronized to the system of record (SOR) and client centralized profile.
- In one of the customer implementations along with synchronizing the data to SOR and client centralized profile, the requirement is to synchronize the data to the fulfillment system as well.
- In this case, as the data transform does not have any extensions, the base layer rule needs to be overridden in the implementation layer to include the logic for synchronizing to the fulfillment system. Due to this, any subsequent changes introduced in the base layer, would not be picked up in the implementation layer due to the rule being overridden.
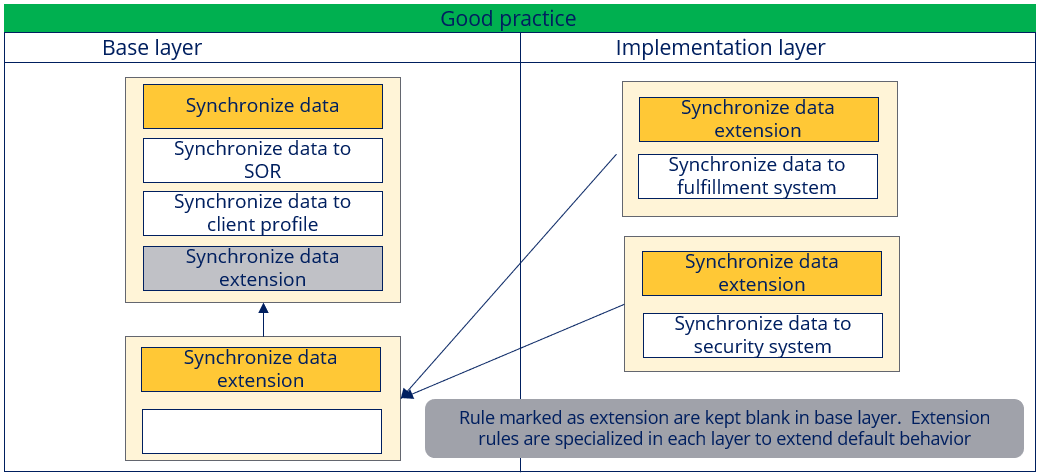
- Instead of overriding the rule, if the data transform is provided with an extension point, customers can override just the extension rule and add all implementation-specific logic. This would avoid any manual retrofitting of logic in the implementation layer rule, whenever the base rule is updated. This would also assist in easier updates.
- Likewise, Dynamic referencing is another related pattern which amongst its many advantages, also provides easy extensibility.
Modularization
Modularization is a design pattern that emphasizes segregating the logic into independent, reusable modules, as opposed to building a monolithic rule. The implementation logic has to be modularized into smaller chunks of reusable logic, and typically gets wrapped under a single rule. Code modularization promotes:
- Specialization of only the required block and not the whole code.
- Reuse, as each modularized block can be plugged in at multiple places within the enterprise.
- In turn, easier updates.
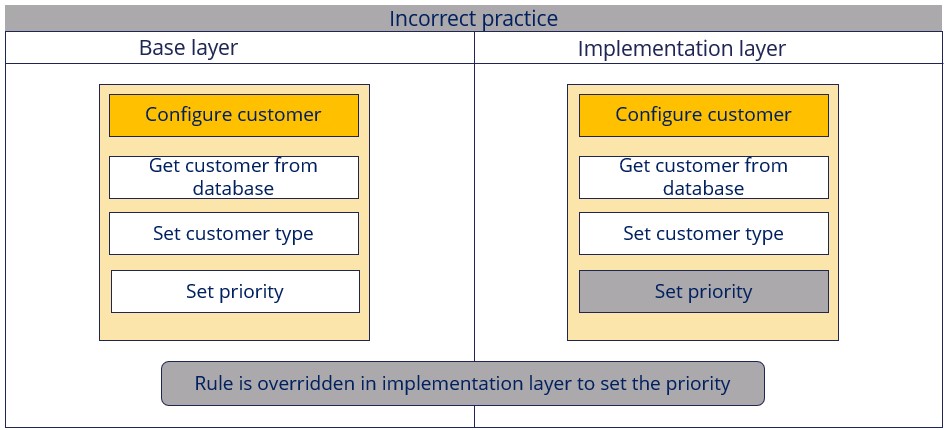
For example, let’s take a use case of configuring customer information. Incorrect and correct behaviors on how this use case can be implemented are shown in the below image.
- Assume the data transform is not properly modularized and the whole logic is wrapped in the same data transform.
- In the base layer, the customer data is fetched from the database and then customer type (Individual or entity) and priority are set.
- In one of the customer implementations, instead of getting the customer data from the database, it should be fetched from an external service. Using data pages, solves the purpose. Data pages can be overridden to point to different sources based on the requirement.
- However, in the implementation layer, if there is a need to set the "priority" field to a different value than the base layer, then the base layer data transform needs to be overridden in the implementation layer. Owing to the override, any down-the-line changes to this rule (in the base layer), will not be picked up in the implementation layer.
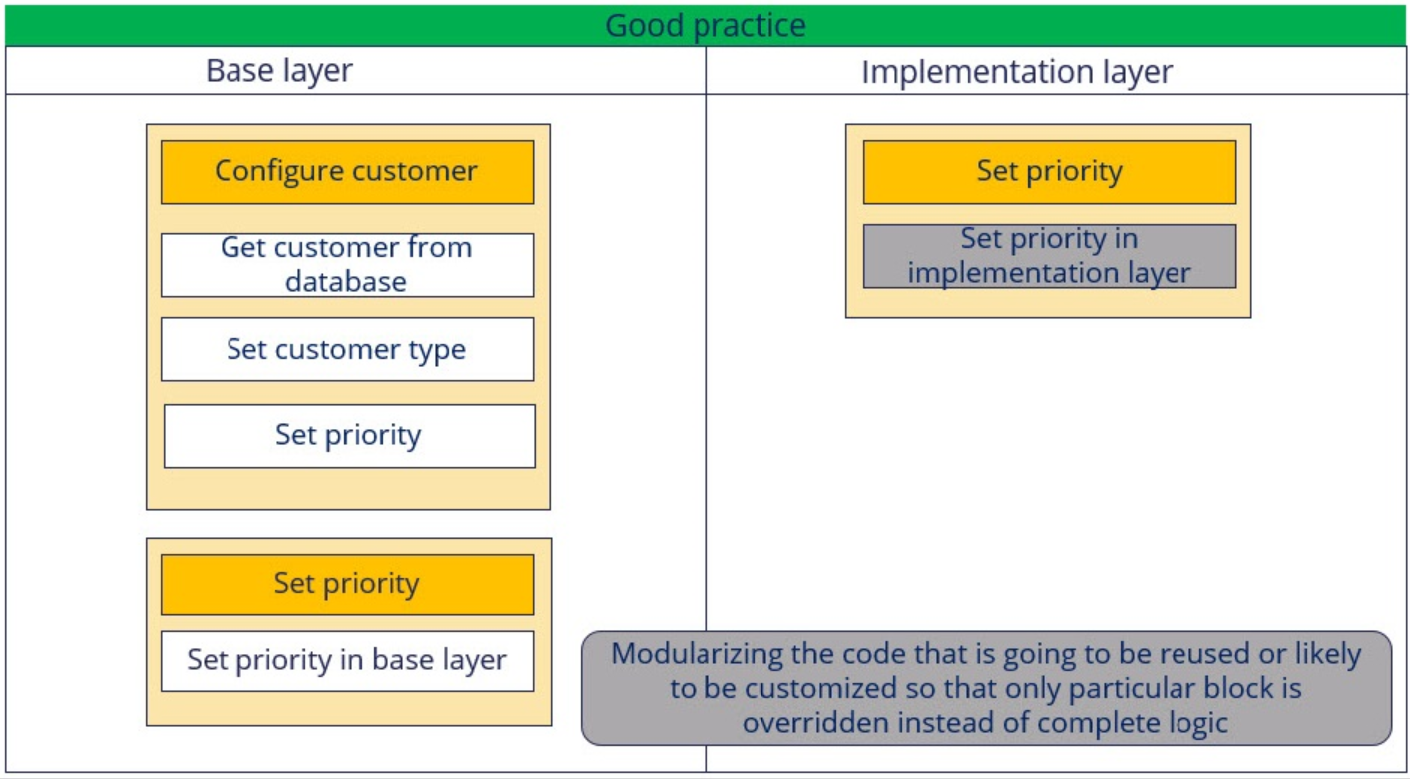
- Instead of copying the rule, if the data transform is properly modularized into different blocks, then it’s enough if only the required module is overridden instead of overriding the complete rule. This avoids manual retrofitting of logic in the implementation layer rule whenever the base rule is updated.
- The “Call superclass data transform” option can also be leveraged if there is a generic logic in the base layer that can be reused in the implementation layer.
Components
In the Pega context, a component is a collection of rules that creates a reusable, plug-and-play feature that can be added to any application in an enterprise. Components are not tightly coupled with any application. They are built in one or more component rulesets and are self-contained. All the necessary rules for the execution of their process should be in these rulesets.
Components should be created when there is functionality that could be used in multiple applications. Once a component is included in an application, it can receive inputs from the application and can then process the input to return the intended output.
As components provide critical features in a plug-and-play mode, they naturally assist in easier extension of functionality; help in moving away from reinventing the wheel.
Examples of components would be Optical character recognition (OCR) and Digital signature, which are common features used across multiple industries, and instead of building those features as part of a single application, it is good if they are componentized so that multiple applications can use them as plug-and-play features.
Additional resources
For more information, refer to the following articles on Pega Community:
| Page | URL | Description |
|---|---|---|
| Pega Community | https://docs.pega.com/bundle/platform/page/platform/app-dev/components.html | More information on components |
| Pega Community | https://docs.pega.com/bundle/platform/page/platform/app-dev/extension-points.html | More information on extension points |