Question
Capgemini
ES
Last activity: 17 Dec 2020 18:43 EST
How to merge multiple PDF files into a single PDF file
There are multiple PDF documents generated in a case. Requirement is to merge all the PDF files into a single PDF document.
For EForm there is an OOTB activity to merge "ConcatenateEForms" but for PDF files I could not find anything. IS there a way to merge PDF files in Pega?
***Edited by Moderator Marissa to update platform capability tags****
Updated: 22 Jan 2020 3:29 EST
ING
NL
Hi, Did you refer this link
https://collaborate.pega.com/question/how-merge-multiple-pdf-files-single-pdf-pega
Capgemini
ES
Hi Abhinav,
I tried with the code mentioned in the article:
1. It gives a compilation error with java code for FileData
2. How can I find the details of attached PDF if the code runs successfully.
Ai4Process
GB
hi,
Could anyone help me on this
I have used code mentioned above but it is giving error
1. It gives a compilation error with java code for FileData
2. How can I find the details of attached PDF if the code runs successfully.?
Updated: 2 Oct 2020 13:21 EDT
Capgemini
NO
Hi, I wrote a function utilizing the OOTB Apache PDFBox library to merge PDFs in our application.
Input : ByteArray of 2 PDFs Output: ByteArray of merged PDF
PublicAPI tools = ThreadContainer.get().getPublicAPI();
byte[] byteArray1 = (byte[]) pdfOne;
byte[] byteArray2;
boolean check;
if (pdffinal != null) {
byteArray2 = (byte[]) pdffinal;
check = true;
} else {
byteArray2 = (byte[]) pdfOne;
check = false;
}
org.apache.pdfbox.pdmodel.PDDocument mergedPDF = new org.apache.pdfbox.pdmodel.PDDocument();
java.io.InputStream bis1 = new java.io.ByteArrayInputStream(byteArray1);
java.io.InputStream bis2 = new java.io.ByteArrayInputStream(byteArray2);
try {
org.apache.pdfbox.pdmodel.PDDocument doc1 = org.apache.pdfbox.pdmodel.PDDocument.load(bis1);
org.apache.pdfbox.pdmodel.PDDocument docf = org.apache.pdfbox.pdmodel.PDDocument.load(bis2);
org.apache.pdfbox.multipdf.PDFMergerUtility merger = new org.apache.pdfbox.multipdf.PDFMergerUtility();
if (check) {
merger.appendDocument(mergedPDF, docf);
}
merger.appendDocument(mergedPDF, doc1);
java.io.ByteArrayOutputStream bos = new java.io.ByteArrayOutputStream();
mergedPDF.save(bos);
mergedPDF.close();
return bos.toByteArray();
} catch (Exception e) {
byte[] nn= null;
return nn;
}
Hi, I wrote a function utilizing the OOTB Apache PDFBox library to merge PDFs in our application.
Input : ByteArray of 2 PDFs Output: ByteArray of merged PDF
PublicAPI tools = ThreadContainer.get().getPublicAPI();
byte[] byteArray1 = (byte[]) pdfOne;
byte[] byteArray2;
boolean check;
if (pdffinal != null) {
byteArray2 = (byte[]) pdffinal;
check = true;
} else {
byteArray2 = (byte[]) pdfOne;
check = false;
}
org.apache.pdfbox.pdmodel.PDDocument mergedPDF = new org.apache.pdfbox.pdmodel.PDDocument();
java.io.InputStream bis1 = new java.io.ByteArrayInputStream(byteArray1);
java.io.InputStream bis2 = new java.io.ByteArrayInputStream(byteArray2);
try {
org.apache.pdfbox.pdmodel.PDDocument doc1 = org.apache.pdfbox.pdmodel.PDDocument.load(bis1);
org.apache.pdfbox.pdmodel.PDDocument docf = org.apache.pdfbox.pdmodel.PDDocument.load(bis2);
org.apache.pdfbox.multipdf.PDFMergerUtility merger = new org.apache.pdfbox.multipdf.PDFMergerUtility();
if (check) {
merger.appendDocument(mergedPDF, docf);
}
merger.appendDocument(mergedPDF, doc1);
java.io.ByteArrayOutputStream bos = new java.io.ByteArrayOutputStream();
mergedPDF.save(bos);
mergedPDF.close();
return bos.toByteArray();
} catch (Exception e) {
byte[] nn= null;
return nn;
}
You can call this function as below. If you have Base64 of the file, convert to bytearray and then pass it to function. If you have HTML markup of the PDF, convert to bytearray using HTMLtoPDF activity.
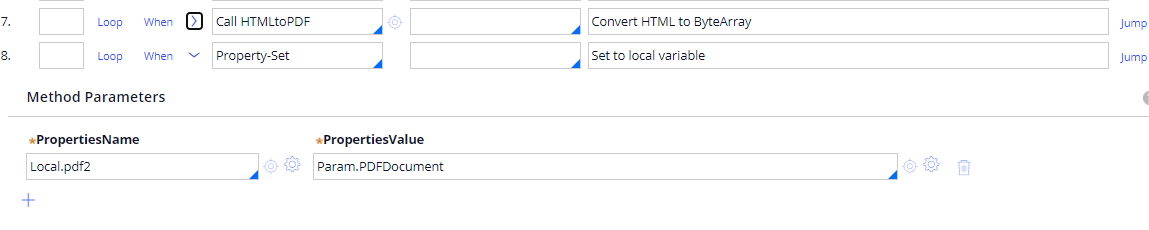
You can allow the user to download the merged PDF using by passing param value to View activity.
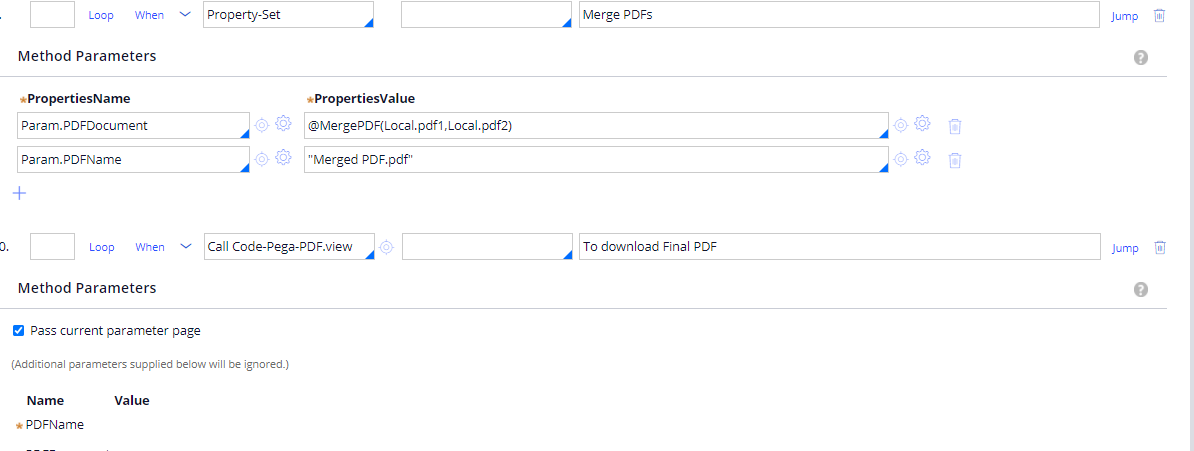
You can tweak the code and loop through the PDFs to work for your scenario. Let me know if you have any questions.
Good Luck!
Banco Múltiple Bhd León SA
DO
Hi i'm using your code for generating a PDF based on two base64 and the PDF is downloaded but when i open the PDF the PDF file is corrupt, i get an error message, please check the attached document.
Check it out my code:
PublicAPI tools = null;
PRThread thisThread = (PRThread)ThreadContainer.get();if (thisThread != null)
{
tools = thisThread.getPublicAPI();
}
else
{
throw new PRAppRuntimeException("Integration Failed", 0, "Unable to obtain current thread.");
}byte[] byteArray1 = new com.pega.pegarules.pub.util.Base64Util().decodeToByteArray(base64);
byte[] byteArray2 = new com.pega.pegarules.pub.util.Base64Util().decodeToByteArray(base64);org.apache.pdfbox.pdmodel.PDDocument mergedPDF = new org.apache.pdfbox.pdmodel.PDDocument();
java.io.InputStream bis1 = new java.io.ByteArrayInputStream(byteArray1);
java.io.InputStream bis2 = new java.io.ByteArrayInputStream(byteArray2);try {
Hi i'm using your code for generating a PDF based on two base64 and the PDF is downloaded but when i open the PDF the PDF file is corrupt, i get an error message, please check the attached document.
Check it out my code:
PublicAPI tools = null;
PRThread thisThread = (PRThread)ThreadContainer.get();if (thisThread != null)
{
tools = thisThread.getPublicAPI();
}
else
{
throw new PRAppRuntimeException("Integration Failed", 0, "Unable to obtain current thread.");
}byte[] byteArray1 = new com.pega.pegarules.pub.util.Base64Util().decodeToByteArray(base64);
byte[] byteArray2 = new com.pega.pegarules.pub.util.Base64Util().decodeToByteArray(base64);org.apache.pdfbox.pdmodel.PDDocument mergedPDF = new org.apache.pdfbox.pdmodel.PDDocument();
java.io.InputStream bis1 = new java.io.ByteArrayInputStream(byteArray1);
java.io.InputStream bis2 = new java.io.ByteArrayInputStream(byteArray2);try {
org.apache.pdfbox.pdmodel.PDDocument doc1 = org.apache.pdfbox.pdmodel.PDDocument.load(bis1);
org.apache.pdfbox.pdmodel.PDDocument docf = org.apache.pdfbox.pdmodel.PDDocument.load(bis2);
org.apache.pdfbox.multipdf.PDFMergerUtility merger = new org.apache.pdfbox.multipdf.PDFMergerUtility();
merger.appendDocument(mergedPDF, docf);
merger.appendDocument(mergedPDF, doc1);java.io.ByteArrayOutputStream bos = new java.io.ByteArrayOutputStream();
mergedPDF.save(bos);
mergedPDF.close();
tools.putParamValue("Data",bos.toByteArray());
return bos.toByteArray();
} catch (Exception e) {
tools.putParamValue("Data",e.toString());
byte[] nn= null;
return nn;
}
Coforge Limited
IN
Hi Sudhanshu,
The solutions described earlier using Apache pdfbox are really great and worth trying. But in my experience, not all PEGA developers are comfortable with Java coding and in case if you are using an old PEGA version, for instance 7.1, PDFBox JARs will have to be imported into the application for the solution to work. If you want to implement the solution using only PEGA OOTB below is a suggestion which I implemented for PDF generation in PEGA 7.1.
Steps:
- Create an activity and create a page with class Code-PEGA-eForm(PageName example: MergePDF)
- Use HTMLToPDF to generate PDF from HTML stream.
- The above activity provides the PDF in byteArray form through an output parameter named PDFDocument.
- Do a Property-Set after each of the HTMLToPDF activity call with code like below:
- MergePDF.pyEForms(<APPEND>) = Param.PDFDocument
- After calling all required HTMLToPDF call ConcatenateEForms activity on the above-created page (MergePDF here).
- The final PDF byteArray will be available on the Property pyEForm of the same page.
- Do a Property-Set:
- Param.PDFDocument = MergePDF.pyEForm
- Param.PDFName = Test.pdf
Call Code-Pega-PDF.View which will generate your final PDF.
Although the class of the above activity indicates that it is for eForm but will work perfectly fine for normal PDFs a well.
Hi Sudhanshu,
The solutions described earlier using Apache pdfbox are really great and worth trying. But in my experience, not all PEGA developers are comfortable with Java coding and in case if you are using an old PEGA version, for instance 7.1, PDFBox JARs will have to be imported into the application for the solution to work. If you want to implement the solution using only PEGA OOTB below is a suggestion which I implemented for PDF generation in PEGA 7.1.
Steps:
- Create an activity and create a page with class Code-PEGA-eForm(PageName example: MergePDF)
- Use HTMLToPDF to generate PDF from HTML stream.
- The above activity provides the PDF in byteArray form through an output parameter named PDFDocument.
- Do a Property-Set after each of the HTMLToPDF activity call with code like below:
- MergePDF.pyEForms(<APPEND>) = Param.PDFDocument
- After calling all required HTMLToPDF call ConcatenateEForms activity on the above-created page (MergePDF here).
- The final PDF byteArray will be available on the Property pyEForm of the same page.
- Do a Property-Set:
- Param.PDFDocument = MergePDF.pyEForm
- Param.PDFName = Test.pdf
Call Code-Pega-PDF.View which will generate your final PDF.
Although the class of the above activity indicates that it is for eForm but will work perfectly fine for normal PDFs a well.
Do analyze the code of ConcatenateEForms activity as depending on your PEGA version you will get multiple functionalities available in this OOTB activity including encryption and password protection for PDF.
Note: PDFDocument parameter used by PEGA is actually the object address pointing to PDF Byte Array. So if someone wants to use a custom code instead of HTMLToPDF the final PDF can be converted to bytearray and et on a parameter to be used by PEGA.
Let me know in case of any further queries.