Question
Adqura
US
Last activity: 19 Oct 2016 9:51 EDT
How to fetch data in parallel in dataflows in Pega Marketing
Hi,
In Pega Marketing we're using CustomerData dataflow to compile customer data in real-time. All data sets are accesing Oracle tables. Everything is working as designed.
In the second phase of our project, we would like to call (at least) two different webservices; webservice-1 returns CustomerComplaints and webservice-2 returns CustomerTotalAccountBalance. Execution paths, in Next-Best-Action strategy, will dramatically change based on this information. For example, if customer has complaint, a "retention" related messages/offers will be shown and for valuable customers, based on customer's acocunt balance, some specific propositions will be available. Therefore, data must be fetched in real-time.
As far as I see, datasets are getting executed in serial, which means total execution time of the DF is equal to the sum of each data set's execution time. That would slow down DF's execution time and will most likely cause timeouts on channel applicaitons because PM would not be able to meet with its SLA.
Therefore, briefly, we would like to fecth data from various webservices in parallel. Expectation is not limited to webservice calls.
Is there a way to implement this?
Regards,
Pega Markeitng 7.13 on top of Pega 7.2
Accepted Solution
Pegasystems Inc.
IN
Hi Oguz,
An enhancement request has been created on our internal portal. The request ID is attached to your post above (under Related Support Case Number field.)
Regards,
Lochan
Adqura
US
Hi Kevin,
Where do you set this option in data sets/flows? When I trace it, it seems to be running in serial. It executes them from left to right. Or do I have this option only in REST/SOAP APIs but not in JDBC calls?
Regards,
Pegasystems Inc.
US
only in REST/SOAP. Not familiar with data sets/flows, if they are using REST/SOAP, then the option should be available, check the online help for REST/SOAP connectors.
Accepted Solution
Pegasystems Inc.
IN
Hi Oguz,
An enhancement request has been created on our internal portal. The request ID is attached to your post above (under Related Support Case Number field.)
Regards,
Lochan
Pegasystems Inc.
NL
Oguz,
can you attach a sample data flow in which you would like data to be fetched in parallel ? Currently in a data flow you can't read explicitely from WS.
Cheers,
Ionut
Adqura
US
Hi Ionut,
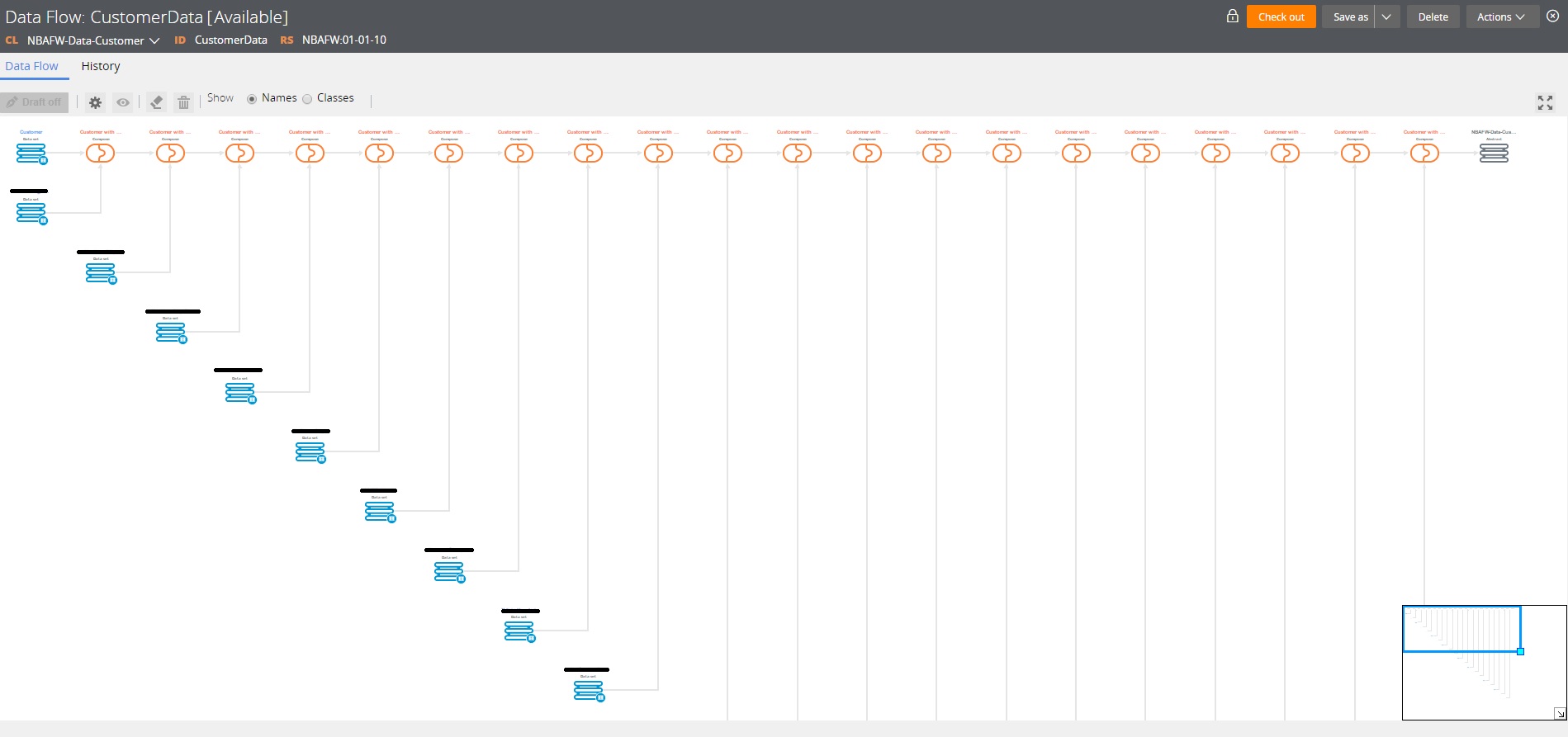
Attached customer data flow has 20 compose shapes because customer data is fetched from 20 different tables. This is phase-1. In phase-2, we'll also call a webservice (CustomerCompliants) to enrich customer data to improve Next-Best-Action strategy, and with phase-3 we're eager to add at least one more real-time WS call to get customer balance.
Therefore, for phase-1 we would like to fetch data in paralel via data sets. With phase-2, as mentioned above, we'll introduce webservices into CustomerData fata flow.
Due to high number of data sources (~20 tables & 2-3 webservices), we would like to have the ability to call these datasources in paralel so that we can reduce the execution time of data flow and stay in agreed SLAs.
Regards,