ADM Model advanced settings
Hi All,
We wanted to create same ADM model with different subset of responses. Before that, I would like to understand how the weighted score gets calculated.
What is the difference between scenario 1 and scenario 2 attached in this post?
What is the importance of scenario 3 in terms of model snapshot?
Pegasystems Inc.
NL
Hi Nizam,
The default setting is to weight all responses equally when updating a model (internally a value of 0 is then used).
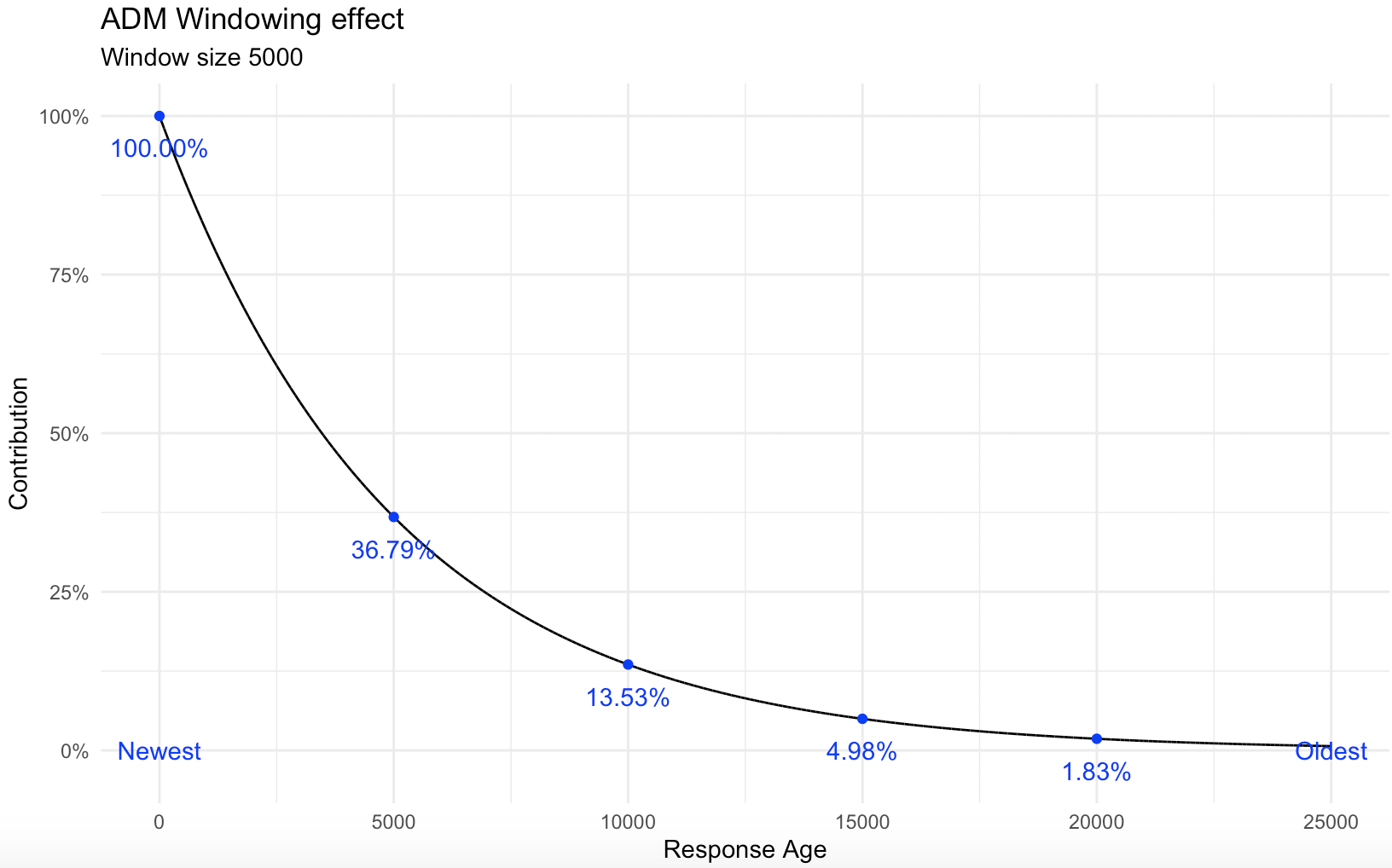
If you use a subset of N responses when updating an adaptive model then the impact of previous responses is down-weighted with every new response. This gives an exponential decay of the weight of the responses, like shown below.
Note: the value shouldn't be set too low, for example to 500 if there is a click-through-rate of 1% because then the window('memory' of the adaptive model) would be too small,
Regards,
Ivar
Tech Mahindra
IN
@Ivar_Siccama Thanks for responding back to my question.
Can you please clarify on the below point.
If you use a subset of N responses when updating an adaptive model then the impact of previous responses is down-weighted with every new response.
How does the impact of previous responses is down weighted? I mean lets say if the model refresh(learns) happens after 5000 responses and if I have given use subset of responses as 500 will it only pick 500 responses out of 5000? If yes, then how it will happen? Is it random or any specific weighted filters?
Regards,
Nizam
Updated: 21 Jan 2022 9:54 EST
Pegasystems Inc.
NL
@Nizam ADM does not keep those 5000 (in your example) around. It only keeps track of aggregate values.
So if the window is 5000 and the 5001'th comes in, the current sums are first multiplied by 4999/5000 then the new one is added.
If you do that repeatedly you get the exponential decay that the plot illustrates.
Tech Mahindra
IN
@Otto_Perdeck Thanks for the response. But what is the difference between scenario 1 and scenario 2 (ATTACHED SCREENSHOTS)?
So if the window is 5000 and the 5001'th comes in, the current sums are first multiplied by 4999/5000 then the new one is added. I mean in both scenario 1 and scenario 2, the same pattern is followed right?
Scenario 1: (500 Aggregated value) multiplied by 501/502/503(All responses).... And this continue.
Scenario 2: (500 Aggregated value) multiplied by 501/502/503(weighted responses).... And this continue.
For me both looks similar.
Regards,
Nizam
Pegasystems Inc.
NL
@Nizam Hi Nizam. Out of curiosity - what is the use case behind this? How do you plan to arbitrate between models with different learning rate, or are you just considering the weights for reporting on AUC?
Tech Mahindra
IN
@Otto_Perdeck We have created four models with the below settings and compare the performance at run time.
- NBADigital ---> Refresh after 500 responses and use all responses when updating the model.
- NBADigital_High ---> Refresh after 500 responses and use 500 responses when updating the model.
- NBADigital_Medium ---> Refresh after 500 responses and use 250 responses when updating the model.
- NBADigital_Low ---> Refresh after 500 responses and use 100 responses when updating the model.
I think both 1, 2 will have same ADM learning in the above example. Let me know if my understanding is right.
Pegasystems Inc.
NL
@Nizam The "Refresh" setting is a technical setting that governs how often the ADM models are updated from the queued responses. This is independent of the setting that tells ADM how many responses to use when updating.
The model update frequency by default is set to 5000. Setting it to a lower value as in your example may have computational implications (more load on the system). We do not recommend doing that except perhaps in situations where there just is very low volume.

The 100-250-500 window sizes are also small - with typical success rates of just a few percent these would implicate the models receive just a handful of "positives". Typically not enough to be reliable. Then again, I don't have the full context of your use case, so just for your consideration.
Using a subset of the responses is considered an "advanced setting", not used very often and we do recommend using this with care.
Verizon
US
I'm one of @Nizam 's colleagues.
The use of Low, Medium, and High/Full memory windows is intended for cases where models would benefit from being trained on shorter predictor data timeframes.
In general, Full/High window models are better, but there may be cases where lower window models would provide better accuracy.
Weather may be an appropriate example. Models trained on more recent data would produce more accurate predictions - aggregated data over 5 years would have less relevance versus the past week of data when trying to predict weather conditions. There are likely better examples.
Similar models with different memory windows would then compete, and whichever performed best would win arbitration.
Ideally, the memory windows should be based on time. However, since time is not available as a parameter, weighing by latest x responses is the closest we can get.
So you may think of the intention as:
Low ~ 1 week of data
Medium ~ 1 month of data
High/Full ~ entire dataset
These are not accurate but should clarify the intent and context.