Discussion
Pegasystems Inc.
BR
Last activity: 19 Aug 2025 9:05 EDT
Understanding Data Access Patterns: When to Use Embedded, Reference, and Query List Fields
Overview
Embedded, Reference, and Query represent three distinct data access patterns that serve different purposes in managing data relationships within Pega applications. Each pattern is optimized for specific use cases and data flow requirements, making the choice between them crucial for application performance and maintainability.
Detailed Analysis
Embedded Data
Represents the most direct approach to data management within Pega applications. This type captures field values directly from user input or actions performed within a Case instance. The data remains contained within the case context, creating a self-contained data structure that simplifies management and reduces external dependencies.
Data Reference
Provides a more sophisticated approach by retrieving data from other objects, whether they are entities or data objects. This pattern enables dynamic interaction capabilities, allowing you to pass parameters and fetch relevant data based on user actions or evolving case requirements.
Query
Functions similarly to Data Reference in its ability to retrieve records based on specified parameters, but it's specifically designed for one-way data retrieval scenarios. Once the initial query executes, the parameters remain static and cannot be modified through user interaction.
When to Choose Each Pattern - Best Practices and Recommendations
Based on the most recent Pega documentation, the selection criteria for these data types should align with your specific application architecture and data flow requirements.
Choose Embedded Data when implementing data structures that are intrinsically linked to individual cases and don't require external sourcing. This approach maintains optimal performance by keeping data structures simple and efficient, reducing the complexity of data relationships and minimizing external dependencies. Embedded Data proves most effective for user-generated content, temporary calculations, and case-specific metadata that doesn't need to be shared across multiple cases or applications.
Implement Data Reference when your application requires access to dynamic data that may change based on user input, external system updates, or other runtime factors. This pattern enhances application flexibility and responsiveness by enabling real-time data retrieval and parameter-based filtering. Data Reference becomes essential when building applications that need to maintain relationships between different data objects, access shared organizational data, or implement complex data hierarchies that span multiple business entities.
Select Query for scenarios requiring straightforward data display without interactive parameter modification. This approach ensures efficient data retrieval processes while maintaining clear separation between data presentation and user interaction. Query patterns work exceptionally well for populating dropdown lists, displaying reference information, or presenting read-only data that supports decision-making processes within your cases.
Implementation Considerations
When implementing these patterns, consider the broader architectural implications of your choices:
- Embedded Data offers the highest performance for case-specific data but limits reusability across different contexts.
- Data Reference provides maximum flexibility but requires careful consideration of data synchronization and external system dependencies.
- Query patterns offer excellent performance for read-only scenarios but may require additional mechanisms if data modification becomes necessary in future iterations.
The most effective Pega applications typically employ a combination of these patterns, selecting the most appropriate approach based on specific data requirements, performance considerations, and long-term maintainability goals.
Using in a view as List
I've created a Data Object named "Concert" with the following columns: Name, Price, and Date. I also added a few sample records as shown in the image below.
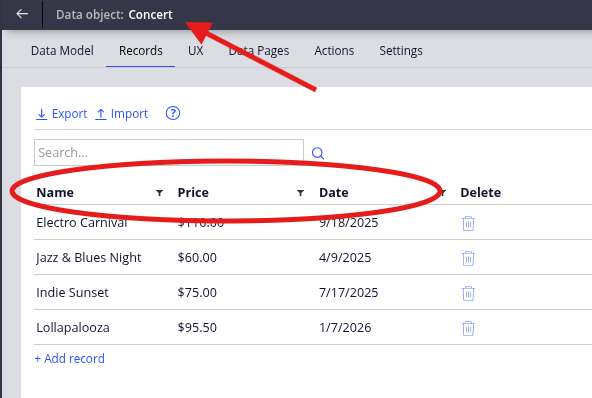
Now, in the case type, I will create three new Properties named: ConcertEmbeddedList, ConcertReferenceList, and ConcertQueryList. All will be configured as lists and added to a view to be displayed in a case.
Embedded Data
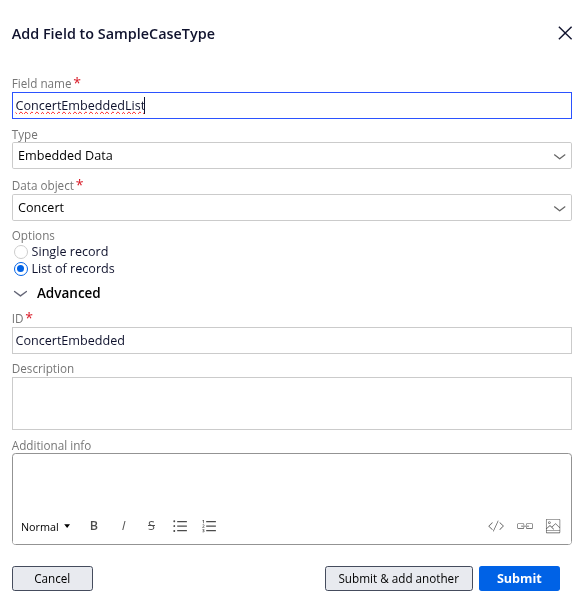
This is what generates with no configuration, simply by adding the property to the view.

To configure this property, click on the name of the field in the display.

This will take you to the property view where you can change the configuration for the presentation.
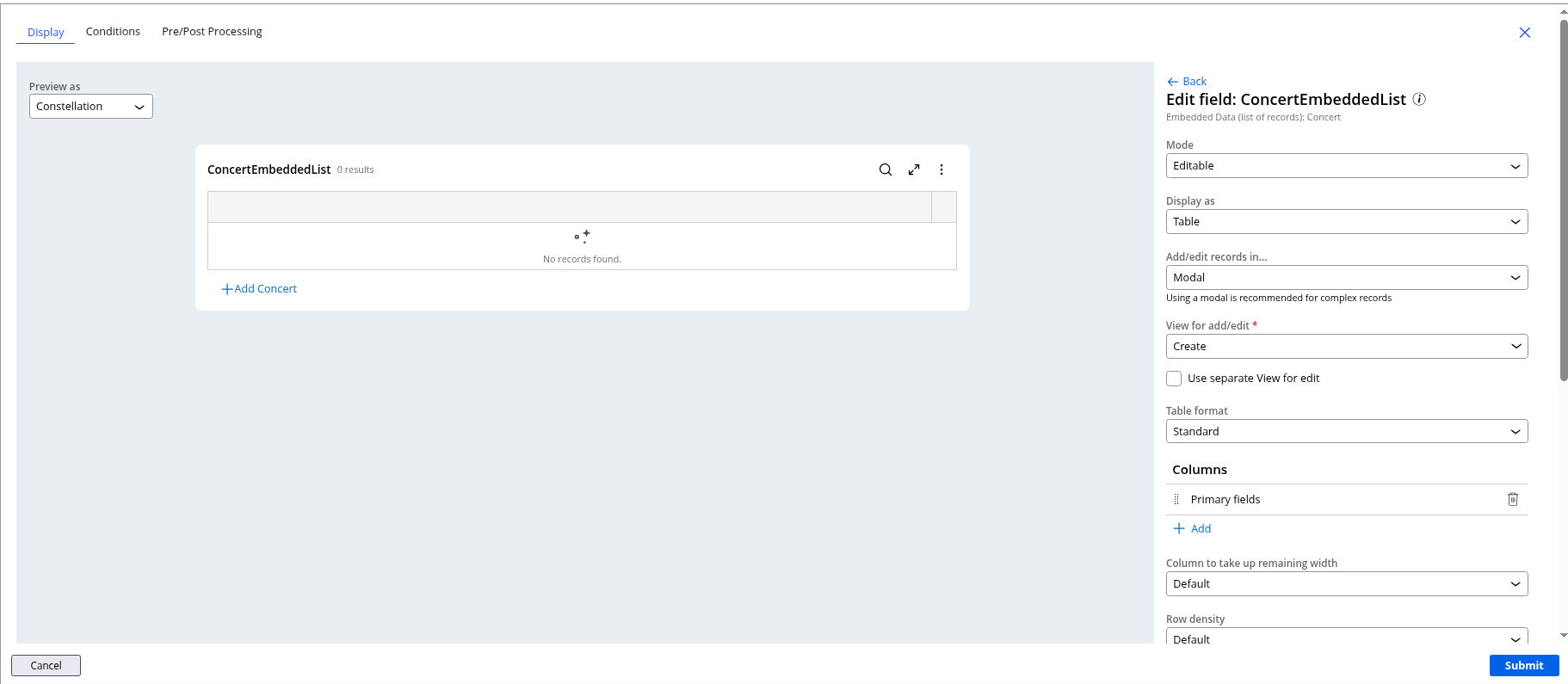
We are going to keep most of this information as default. The first thing we'll do is work with the "Columns" section. Remove the Primary Fields and add the fields we have created.
NOTE: We could also create the fields as Primary Fields. If this is the case, the columns will automatically show in the table.
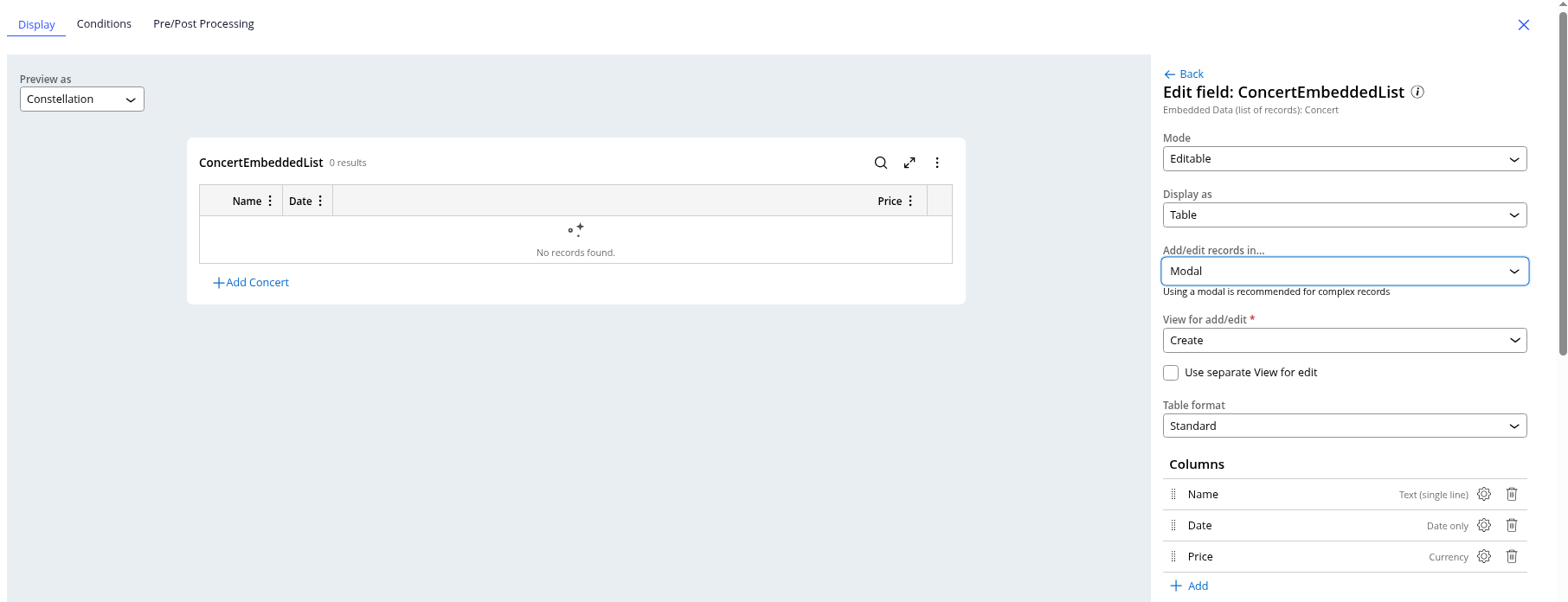
Once you've added the fields, the display updates with the columns. You can change options for each field by clicking the gear icon, but we are going to leave all options out-of-the-box (OOTB).
Now, to create the Modal so we can add new lines to the table, we go to the Data menu and click on the Concert Data Object. At the top, you will see a tab called UX. Once you click on it, a menu opens on the right. Click on the Other Views tab in this menu to view the Create view under the Form option.
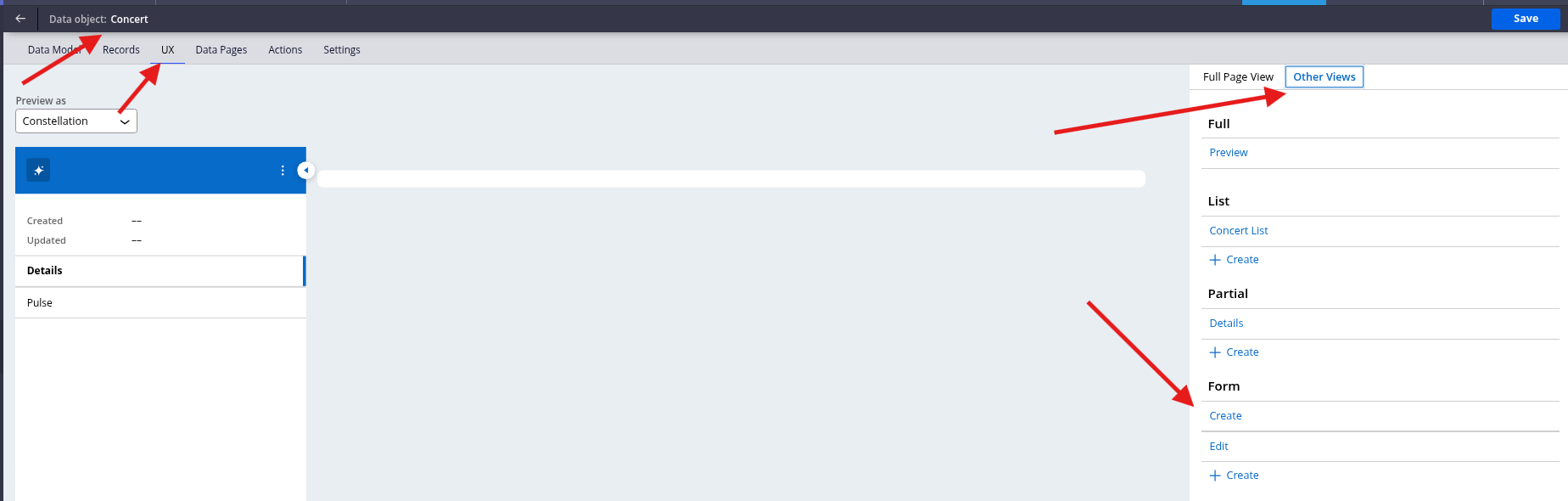
As with the other options, the fields are set to Primary Fields. Simply remove the current fields and add your custom fields, then save.
Now, if you test by creating a new case, you can see that once you click on +Add Concert, you will have a modal display with your information.
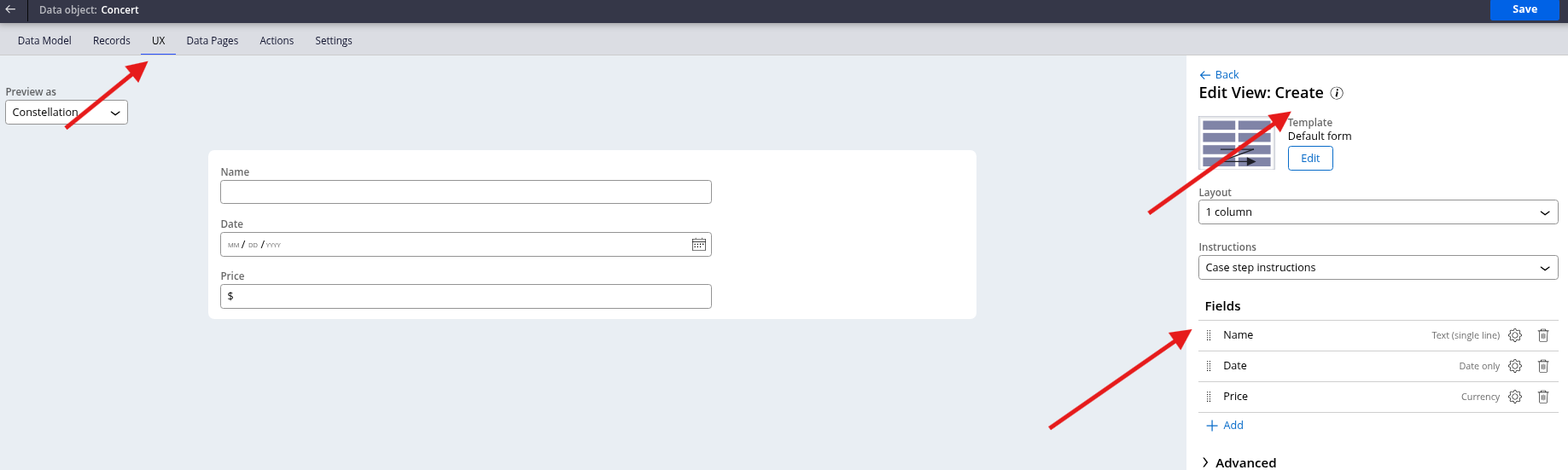
Fill in the modal information and click Submit.
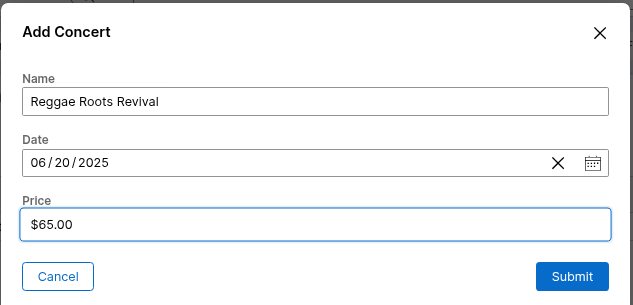

It is important to observe that the information I manually added to the Concert Data Model is not automatically populated in the Embedded Data Object table. This is because we are using Embedded Data, which means we are using the structure of Concert but not the data saved in the table. Additionally, the information added here will not be saved in the database; it will remain in the case blob information.
If you need to save this in the database or bring the table pre-populated, you have to configure this in Dev Studio. We are not going to cover this in this article.
Data Reference
This is what generates with no configuration, simply by adding the property to the view.
To configure this property, click on the name of the field in the display (as we did with Embedded Data).
This will take you to the property view where you can change the configuration for the presentation.
Now, simply add the Columns you wish to see in the table.
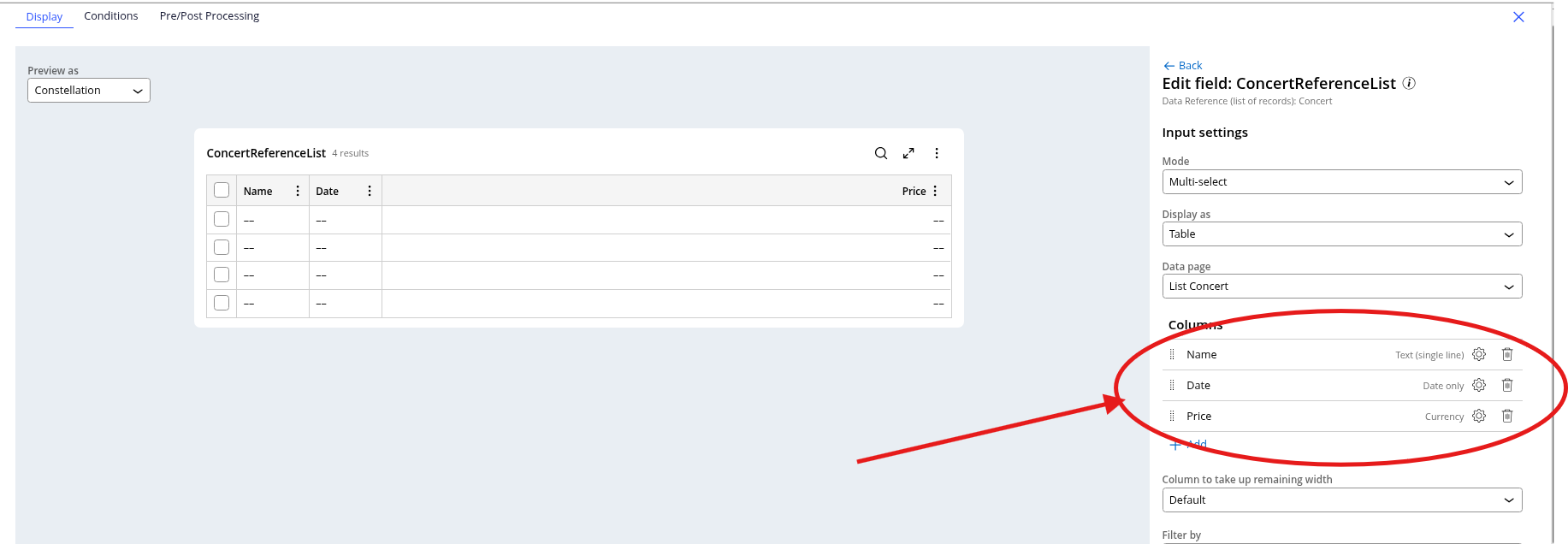
Once you submit, you can save and run the case for testing. Once the view opens, the table will be populated with the information that is in the Data table.
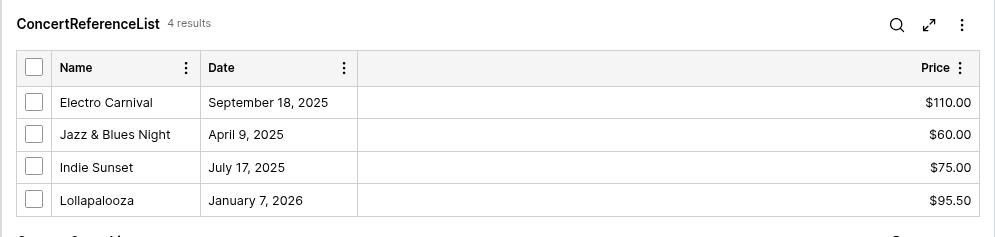
All the other options are set to default. You can change filters and order, but this is just to show the most OOTB possible use of Data Reference.
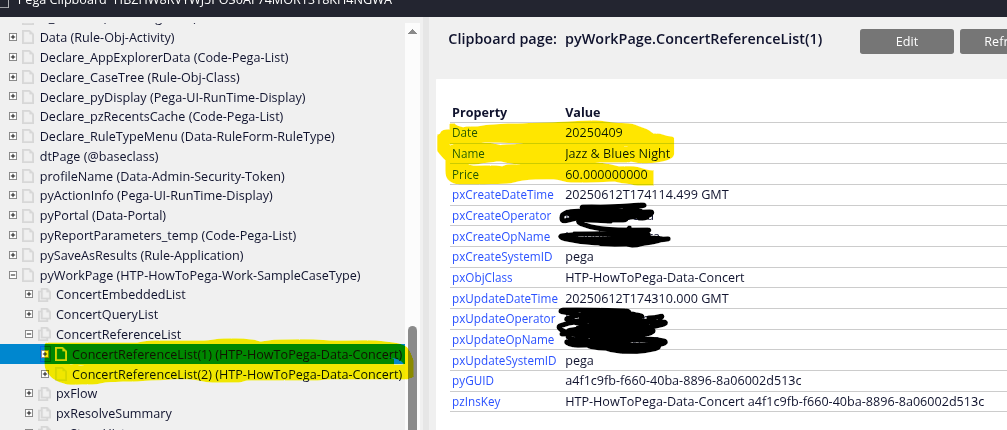
You can select some items (in my case, I selected two) from the list, and these items will be saved in the Case Blob.
Query
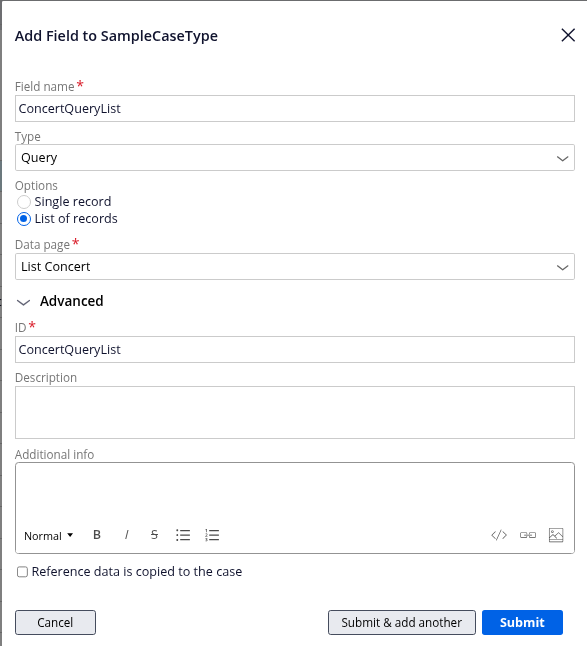
This is what generates with no configuration, simply by adding the property to the view.

To configure this property, click on the name of the field in the display (as we did with Embedded Data).
This will take you to the property view where you can change the configuration for the presentation.
Now, simply add the Columns you wish to see, and the table will update with them.
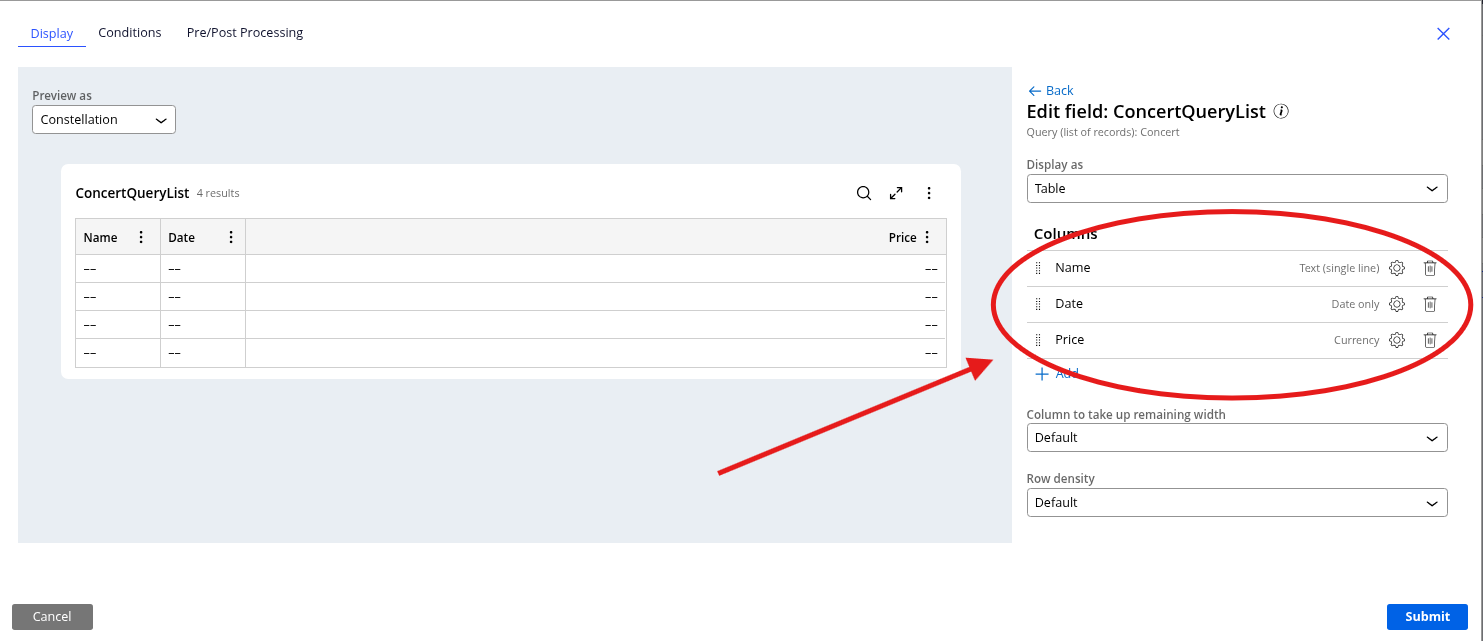
Once you submit, you can save and run the case for testing. Once the view opens, the table will be populated with the information that is in the Data table.

All the other options are set to default. You can change filters and order, but this is just to show the most OOTB possible use of Query.
In Query, the data is not saved in the case Blob; it remains read-only for display purposes.
Conclusion
Understanding these three data access patterns empowers you to make informed architectural decisions that align with your application's specific requirements. Each pattern serves distinct purposes: Embedded Data excels in case-specific scenarios where data isolation and performance are paramount; Data Reference shines when dynamic, real-time data interaction is essential; and Query provides efficient, read-only data presentation for decision support.
The strategic selection of these patterns directly impacts your application's scalability, maintainability, and user experience. By leveraging Embedded Data for case-contained information, Data Reference for dynamic data relationships, and Query for streamlined data presentation, you create robust applications that can adapt to evolving business requirements while maintaining optimal performance.
As Pega continues to evolve, these foundational patterns remain central to effective application architecture. Mastering their implementation and understanding their trade-offs positions you to build applications that not only meet current business needs but also provide the flexibility to accommodate future growth and changing requirements.
References
The information provided is based on the most recent Pega documentation and best practices:
- Pega Academy: Entity Relationships
- Pega Platform Documentation: Data Relationships
- Pega Academy: Creating Data Objects
- Pega Academy: Data Access Patterns
- Pega Platform Documentation: Embedded Data
- Pega Academy: Reference Data Management
- Pega Platform Documentation: Query Rules
- Pega Academy: Case Management Best Practices
Constellation 101 Series
Enjoyed this article? See more similar articles in Constellation 101 series.
Pegasystems Inc.
GB
@LeandroTaveira checkout https://community.pega.com/conversations/user-experience/constellation-… from @Kamil Janeczek
HCL
NL
@MarcCheong what should be the suggestion if I have an embeeded data type which inturn have mutiple columns one column is a pick list based value and other columns sourcesare from external sor based on the selected value from the pick list , now in a same table we will have the combinatiion of patterns of query , pick list and also there can be a possibility of data reference and as a whole that can be an embedded object in a case , for example shipment order is a case which captures list of selected products and each product the other attributes have to be referenced from an external SOR.
Pegasystems Inc.
GB
@JBRaghuraamm yes. Embedded Data that has a Data Reference in it is supported (and by far the better implementation).
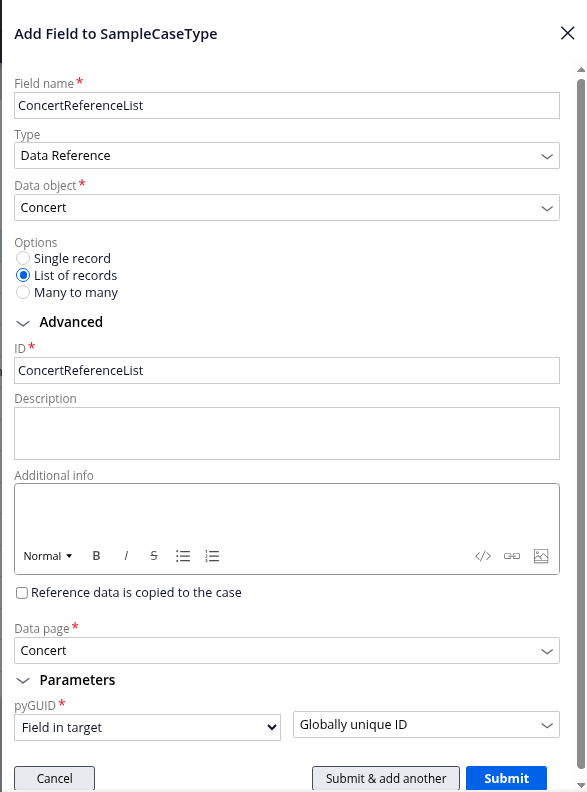
In the article i shared, https://community.pega.com/conversations/user-experience/constellation-…, there are 3 images for visual representation that I added to that post, for this exact reason.
- Look for the text "Add an embedded data field to allow entry of one or more items. This can be combined with data references to allow selection of one or more items from a list." > it has the image i refer
I've had this same conversation recently for examples like "Product Order". Product Order is an embedded data (multiple records), and in it you select a product (Data reference, single record) along with the quantity (integer) and total (currency, calculated). I know a 101 with a detailed implementation is in the works on this too, but hopefully that helps the understand for now?
Pegasystems Inc.
BR
@JBRaghuraamm I think this is a good idea for a "How to" article. I will try this when I have the time. @MarcCheong made a great point, and it should help you with your request.
Pegasystems Inc.
BR
@MarcCheong, It is an excellent article. Both have a way to address the same topic. I think they complement each other.