Troubleshooting NLP in Pega Platform 8.2
How to troubleshoot NLP issues with email, chat, and messaging
Text analytics and natural language processing (NLP) issues are related to either text categorization (topic, small talk, sentiment, and language) or text extraction (entities, keywords, and auto tags). You can handle most of the issues in the channel interface by using Dev Studio. However, advanced issues might also require access to Prediction Studio. Information presented below covers the majority of NLP issues that you can address by just using the channel interface in Dev Studio.
Symptoms of a potential NLP issue
The following NLP issues relate to email:
- Topic is not detected
- Topic is detected but the case is not assigned
- Multiple mentions of the topic are not detected or I am not able to restrict the action to the first occurrence of the topic
- Language is not detected
- Model not detecting topic
- Case properties are not detected
- Feedback data not reflecting
- Signature and greetings in email body part of entities detected
Chat, Messaging, and Live chat
The following NLP issues relate to chat, messaging, and live chat:
- Small talk is not detecting
- Topic not detected for an incoming chat request
- Escalation to agent not getting detected
Step-by-step debugging process
The debugging process includes the following steps:
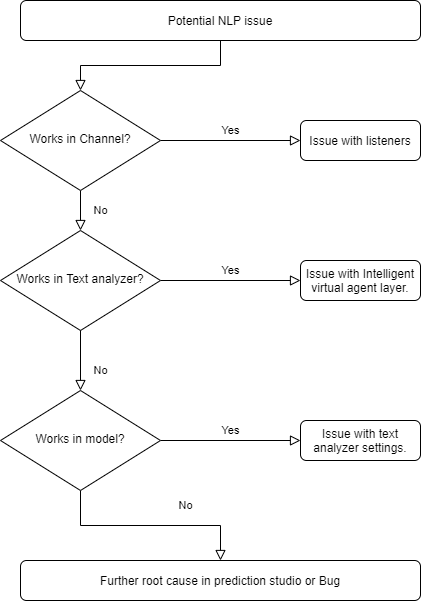
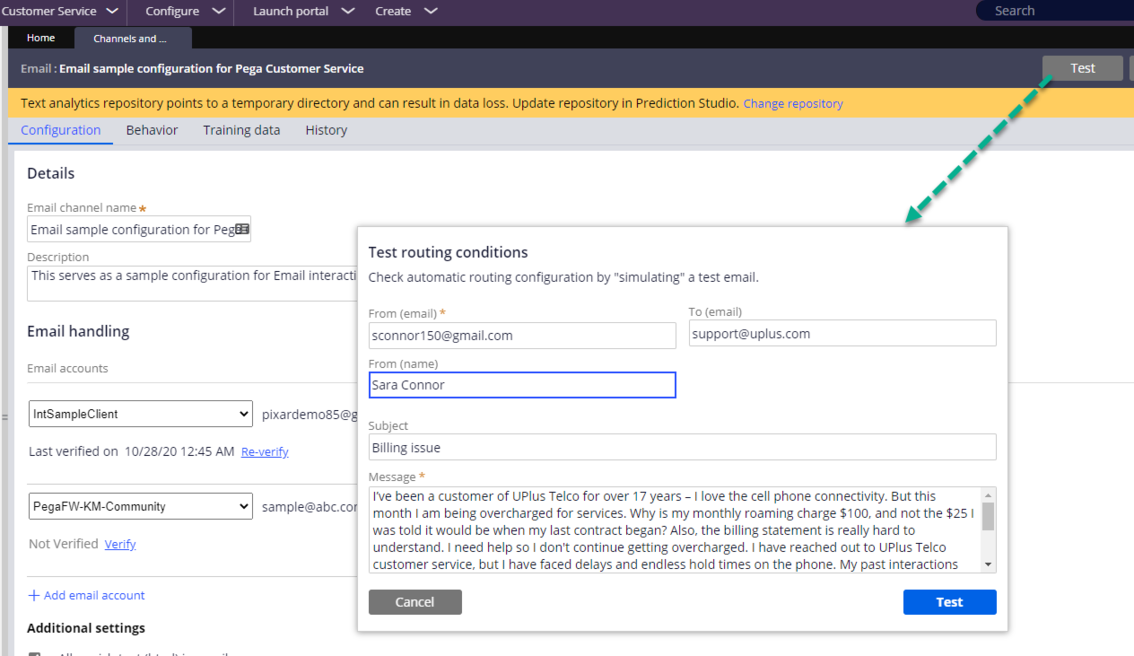
- Test the channel: Every Email or Intelligent Virtual Assistant (IVA) channel includes a test button in the user interface. You can isolate most listener or channel-related issues by clicking this button. Check whether the system detects the right topics and entities together with the confidence scores.
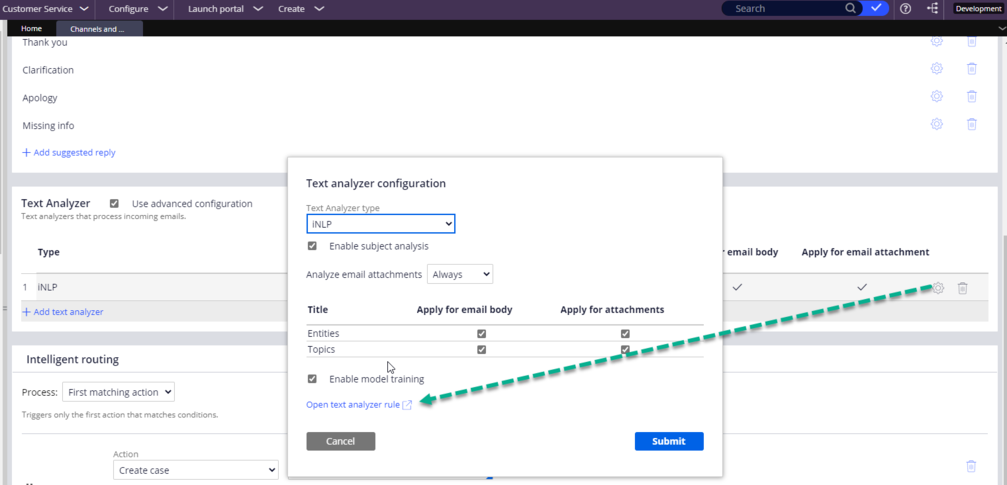
- Test the text analyzer: Click Channel > Text Analyzer > iNLP > Settings > Open text analyzer rule. If the error displays in this test interface, then the error is in the channel interface.
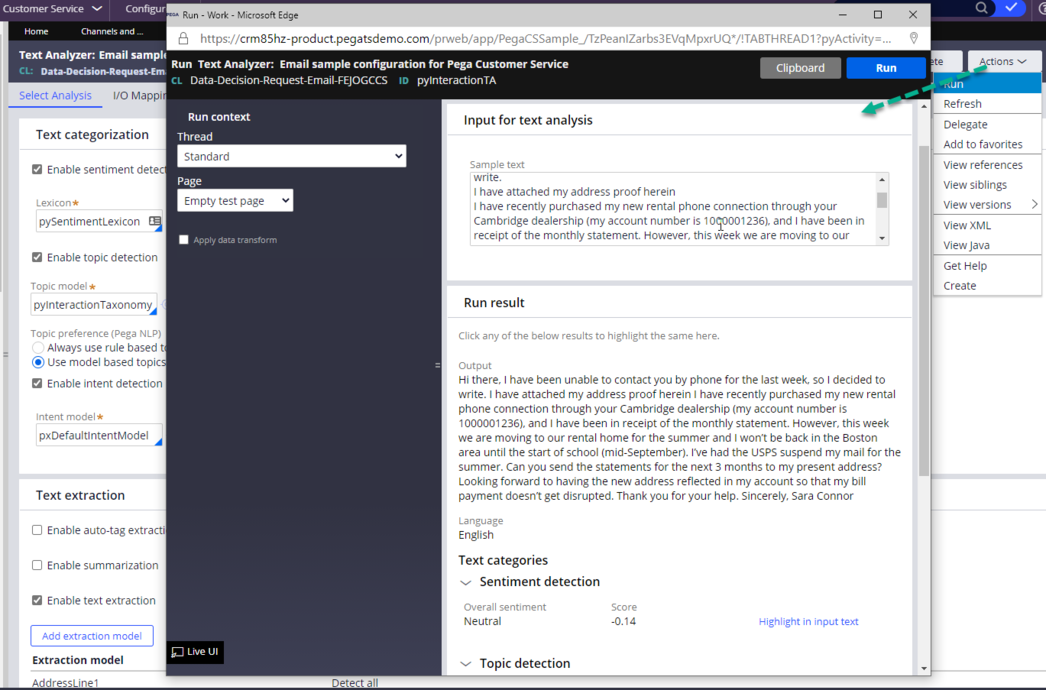
- Test the topic and entity models: The models are essentially decision data rules. Individually, you can test the models by launching the models from the text analyzer.
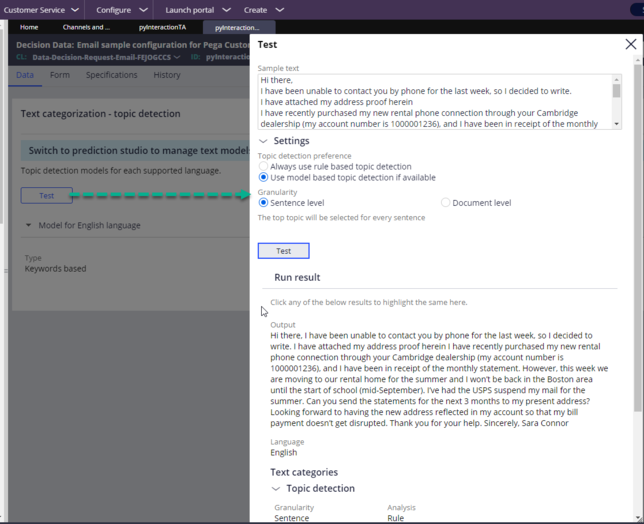
- Test the model settings: Models operate at both sentence and document level. In the test interface, check the results as per the model usage in production. Compare accordingly the confidence score results.
- Test the confidence scores: The system uses model confidence score cutoffs (typically more than seventy percent), as a filter to remove low score topics and entities.
-
Other known issues
- The language is not detected: This issue typically takes place when the input text is too short and might not be a complete example. The system expectation is that the input text consists of at least more than 4 words in a sentence.
- Incorrect language is detected: If you use a combination of languages in the input text, then the system might not correctly detect the language. In the advanced settings for a text analyzer, you can configure the NLP engine to fall back to a specific language when no language is created.
- Training lost after instance restart: The text analytics repository might be pointing to a temporary directory and can result in data loss. Ensure that you update the repository in Prediction Studio.
***Edited by Moderator Marije to add the Developer Knowledge Share tag***
To see attachments, please log in.