Discussion
Pegasystems Inc.
US
Last activity: 30 Oct 2023 5:33 EDT
Pega Logical Architecture
Pega is a thin-client, Java-constructed application designed for deployment in a web browser environment. Pega is a JEE application and is deployed in a 3-tier architecture as illustrated below. The Pega engine consists of a single EAR or WAR deployment that serves as a thin interpretive layer for the application logic which is stored in the database.
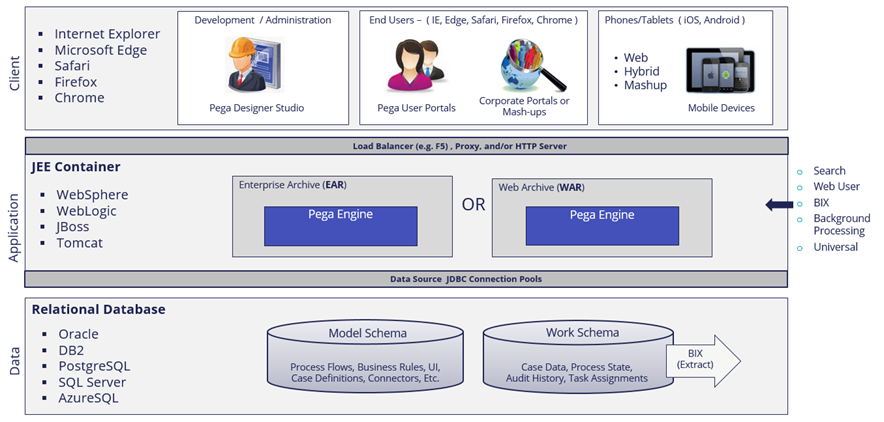
The Pega’ applications are Java applications and are most commonly deployed as a classic multi-tier JEE application.
The Client Tier is all browser-based, including the design time. Being browser-based allows Pega to support our own portals for end users, embed our user interface into other applications such as SharePoint, and Mash-ups. The End User interface is browser-independent and supports IE, Firefox, Safari, Chrome as well as MS Edge. Having a unified rules engine allows Pega to dynamically adjust the user interface to account for channel and/or client device. This unique ability is well suited to supporting mobile clients such as phones and tablets not only through web-kit enabled browsers but natively as well, allowing your Pega applications to take advantage of mobile device capabilities like the camera and geolocation.
At the application tier, Pega supports deployment into WebSphere, Oracle, JBoss, and Tomcat. The Pega engine is deployed either as an EAR or a WAR file. The functionality provided by Pega is the same regardless of how the engine is deployed; however, when deployed as an EAR, Pega can take advantage of the EJB container as well as JEE transaction API and JEE security services. Pega engines can be scaled vertically or horizontally and will typically be deployed in conjunction with a load balancer and other infrastructure resources such as a proxy and/or HTTP server. Note that load balancers must support session affinity, aka of “sticky sessions”, for users who are leveraging the Pega UI; service clients can invoke Pega using either stateless or stateful sessions.
You can optimize performance and provide higher scalability and stability in a cluster through node classification, a configuration that allows specific nodes to be assigned a specific purpose.
At the data tier, Pega leverages a relational, application database. Oracle, DB2/UDB, SQL Server, PostgreSQL, and AzureSQL are all supported. The Pega database uses a split schema design. The Model Schema holds all the process models, business rules, user screens, case definitions, and service levels, that define the way your application runs. When users save a change to a process flow, what they’re really saving is a record to the Model schema. The Work schema stores run-time information such as processes states, case data, assignments and audit history. The split schema design is used to support solutions that need to be highly available by allowing upgrades and maintenance of the Pega platform to be performed with minimal to zero downtime.
Pega persists data to Pega database using a hybrid approach that involves both table column data as well as binary streams (BLOBS). This approach allows the application data model to be changed without requiring updates to the repository schemas, remember Build for Change is our goal with this architecture. It also provides for improved performance as it is not necessary to join together multiple tables to load a single case into working memory. As data is being persisted, Pega looks to see if any of the data has a matching column and if so, will also write the data there as well. This allows the data to be exposed to third-party reporting tools or to be used for optimizing queries. Pega can re-persist previously saved objects so that the exposed data can be written into the new column.
Pega supports network-level and/or HTTP-load balancers to route requests between multiple servers. The solution automatically persists the state of a work object into a central or a cluster database. If server A is unavailable on the next invocation of the server, a built-in load balancer will know server A is unavailable and automatically switch to server B, at which point the work would continue from where it left off. In the event of a system interruption or failure, the Pega solution will store locally any in-process work through business rules workflow, which allows the user to resume processing from the stopping point. Pega leverages standard app server technologies that are multi-threaded and capable of supporting multiple sessions. At the application level, Pega offers multiple options for workload balancing algorithms available for individuals and workgroups including: workload leveling, skills-based, and round-robin routing as well as hybrids of these.
Pega is configured for deployment into high availability environments. High availability deployments do require that the customer has an enterprise-class load balancer that can detect node failures and reroute requests to an available node in a pool. It also requires configuration of shared storage between nodes for persisting user session data. This allows the ability to quiesce a node to apply an operating system patch or perform some other maintenance on the server. Pega provides automated recovery support when the user’s browser crashes or a node in the cluster crashes.
The Pega platform provides out-of-the-box Business Activity Monitoring and Reporting capabilities; however, sometimes it is desirable to copy the data into a data warehouse or an analytics system for further analysis. Pega offers the Business Intelligence Exchange (BIX) product which allows customers to export Pega binary streams into a format suitable for importing.
Updated: 20 Jan 2021 0:05 EST
Scotiabank
CA
@geigm Wonderful article! Loved it, thanks so much for taking the time to write so thoroughly.
Pegasystems Inc.
US
@Smriti @VINAYKUMAR @VenkiteswaranS2935 I am so glad you found this helpful. Honestly, I had forgotten I posted it. There have been so many advances within the Pega platform and framework. These advances should push me to make updates with the newer directions and functionalities included.
rbc
CA
@MattGeigerthanks... looking forward to your update. I am interested in the pega 8.5 deployment on container platform. You mentioned about sticky session. Do you mind to elaborate more? e.g. which type of the users need it?
Thanks,
walter.
Pegasystems Inc.
AU
@MattGeiger having recently joined Pega this article is very informative.
Would be great to have it updated to keep it current.
IUST
IR
Pega persists data to Pega database using a hybrid approach that involves both table column data as well as binary streams (BLOBS). This approach allows the application data model to be changed without requiring updates to the repository schemas, remember Build for Change is our goal with this architecture.
I wonder why you are not using NoSQL databases if that's your goal. What do you think?
Optimum Infosystem Pvt. Ltd.
IN
Thanks to share a grate knowledge. Happy Learning !!
Optimum Infosystem Pvt. Ltd.
IN
Thanks to share a informative knowledge....Happy Learning!!